This is an article written by both Jas (https://github.com/jas10022) and Alex (https://ionkov.tech/).
Today, we’re writing about a pipeline and interface we’ve spent the last six months making to automate 3D avatar creation for virtual and augmented reality experiences, 3dconvert.me.
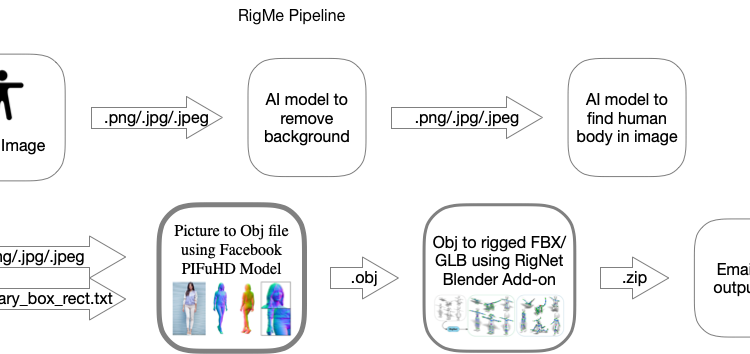
This summer, we were experimenting with Three.js, and WebXR. There are many virtual platforms like VRChat, Mozilla Hubs and Exokit that use avatars for each user and the idea of highly accessible, interoperable and standardized avatars was a problem that caught our attention. Recently around that time, Facebook had released a model, PIFuHD, which converted a 2D human image and boundary box to a 3D object.
We started by trying to modify the PIFuHD GitHub repository as their environment was trained on a specific OS platform using NVIDIA GTX 1080 along with Ubuntu to train the models. There were a lot of CUDA related issues since no GPU device was available to use while we were starting to develop this idea.
We then added a background removal AI to clean the input image for better accuracy. We also had to use the lightweight-human-pose-estimation-3d-demo GitHub repo which is another AI model that can predict the boundary box around a person and returns a tuple for where the person is located. This boundary box along with the cropped image is used as an input for the PIFuHD model to convert the 3d object with more accuracy.
So far, we had built a flask application that contains all the different models within the pipeline and calls them sequentially.
By that time, SIGGRAPH2020 had come around, and we were very hopeful to see some amazing research; potentially new models we could use. RigNet was released and we managed to actually get it working with the help of the author, Zhan Xu. We emailed him asking questions about the setup and he looked at the models and identified some problems like the vertex and triangle count. His advice was extremely helpful and we went onto other issues in days. We found that the PIFuHD model outputs objs with too many vertices (>15k) and RigNet only accepts models with 5k or less just because that is what it has been trained on.
We fixed these problems by reducing the output resolution of PIFuHD but still couldn’t get RigNet to work and were getting an error about normals. We read about obj files and how some of them have the normal info stored which meant that the PIFuHD model outputs obj files without normals so we had to calculate them and output a new obj.
Our 3D models were looking somewhat pixelated because of the low resolution and we thought about applying some smoothing function like the one in Maya. Then we found that by smoothing the models, we can also reduce the number of vertices and reduce any strange protrusions that might have happened.
Each AI model worked very well separately but configuring them to work in series was trickier than we thought.
There were a lot of problems trying to send the api request on mobile. We got a lot of Cross Origin request errors and finally figured out the request format by removing headers and letting the browser add them automatically as well as removing “redirect: follow”. The image is sent as base64 in the body of the request to the AWS server where we parse and save it and then run the pipeline on it.
The next goal of the project is to be able to host the working pipeline into a website. Thus, we decided to host an EC2 instance that would contain all of the pipeline code in a container on AWS that has a public IP to host as an API service. When we first started hosting the pipeline we tried creating a docker image with all the necessary dependencies while installing Maya into the container as well. We found out soon enough that it was not that easy to simply create this unless we had a working version of an instance first.
We launched a t2.micro 1 core 1GB ram 8 gm storage instance but quickly required the g4dn.xlarge with 4 cores 16 GB rams, and 125 GB storage instance that has GPU compatibility to host a Cuda 10.0, 10.1, and 10.2 on an NVIDIA GPU. Since we required funds to run this instance we applied for the AWS Founders package to fund our expenses. When setting up the instance, we ran into many CUDA version issues until we finally installed the correct version on the instance (don’t ask what it is we have no idea, installed literally every version). When moving the pipeline from our local Mac OS environment into the Ubuntu OS we had to reinstall all the models that were being used because the transfer corrupted all of the models weirdly enough. The pipeline was using a lot of RAM within the system and 16 GB of RAM was proving to be slower than expected so we created a swap file to store big matrices of data in faster storage on the system. We tried to implement Maya onto our EC2 instance but our educational license does not seem to allow us to have an activation key. Eventually, we found a Blender add-on called BRigNet which used the RigNet model to predict the joints of the object. The add-on allows us to create a rigged object and then output the scene into FBX, GLB, STL, and OBJ.
Currently when the EC2 pipeline finishes it stores all outputs to a specified S3 bucket and once the process is complete the request will return an S3 download link with CORS setup. We ended up setting up a custom SMTP server on AWS SES and set up an HTML template with Python SMTP to send emails over to the user with the various download links.
Another issue we are facing is with the SSL certification for our API endpoint. We need the SSL certificate because many browsers require HTTPS for webcam access on mobile and requests sent with image data. We used the Python SSL library to connect the flask application to the private key and the SSL certificates to enable HTTPS.
In order to maintain traffic, we decided to set up a separate T2.micro instance in order to handle email requests from our front-end that stored the image data and the user’s email in an Amazon SQS Message. This instance also enables us to scale up all our GPU instances by creating a wait timer to constantly read messages from the SQS one at a time. This enables us to run the long process of converting any person’s image to an email output.
Unfortunately, the pipeline takes a while to process a single request because there are multiple models computing information from the image. In order to accommodate for this we decided to email users the output of their request. We have future plans for optimizing this pipeline but we did not see it necessary to take the steps for that until we gain interest.
At some point we had our avatars working with Exokit Avatars which is a virtual platform. We tried to make our models compatible with VRChat and Mozilla Hubs but this is still a work in progress. At this point, we’re just providing this as a service to show the potential of AI and avatar interoperability.
Our website and email service is free for everyone to use until we run out of money 😄.
https://3dconvert.me