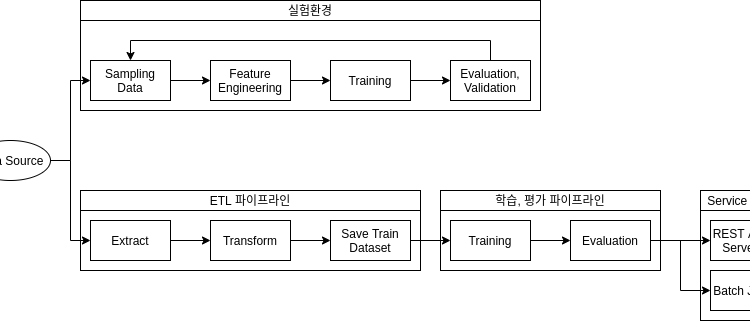
MLOps에는 복잡하고 다양한 파이프라인을 잘 관리해야 합니다. 파이프라인을 관리하는 도구들을 Airflow, Luigi, Azkaban, Step Function등 다양한 도구들을 활용할 수 있습니다. MLOps를 위해서 일반적인 것들과는 다른 선택 기준들이 있을 수 있습니다. 아래에 그 기준들에 대해서 간단히 살펴보겠습니다.
- 파이프라인 개발의 단순화
데이터를 탐색하고 파이프라인을 정의하는 사람은 개발자가 아니라 데이터 과학자입니다. 데이터 과학자분들은 Jupyter Notebook 상에서 python이나 R을 활용해 데이터를 분석하고 문제를 해결하는 것입니다.
실제 파이프라인을 반복적으로 사용하고 수정하는 사용자는 데이터 과학자이므로, 이분들이 쉽게 파이프라인 개발하는 것이 중요합니다. - 작업의 다양한 정상 기준
파이프라인 내의 작업의 정상 기준은 단순히 소스코드가 에러없이 종료되는 것이 아닙니다. 작업의 기능은 데이터를 사용해, 유의미한 데이터를 만들어내거나 학습, 예측하는 것입니다. 이와 같은 작업은 데이터를 어떻게 변경했는지, 학습된 모델의 성능이 어떤가에 따라 정상 기준을 판단할 수 있어야 합니다. - 디버깅
앞서 설명 했듯이 파이프라인 관리 도구의 사용자는 데이터 과학자입니다. 이들이 원하는 디버깅은 IDE에서 Breakpoint를 잡아 진행하는 소스 코드 디버깅과 작업이 처리하려고 했던 데이터의 디버깅입니다.
데이터 과학자가 빈번하게 수정하고 추가해나갈 파이프라인을 관리하는 데에 Airflow가 훌륭한 도구입니다. 오직 파이썬만으로 파이프라인 구현이 가능하기 때문에 데이터 과학자가 실험에 사용한 코드의 많은 부분을 활용하는 것이 가능합니다.
다양한 프레임워크 중 파이썬 기반인 Luigi 와 Airflow 를 비교해보면 확실히 Airflow 가 사용하기 쉽다는 것을 알 수 있습니다.
추가적으로 다양한 데이터 관련 서비스와 연동이 매우 쉽습니다. 위의 샘플 코드에서처럼 파이썬 함수에서 데이터 분석을 해도 되지만, Spark 나 AWS, GCP 에 있는 데이터 분석 도구들도 연동할 수 있습니다.
하지만 Airflow의 단점이 있습니다. 바로 파이프라인 버전 관리와 데이터와 모델의 관리입니다. 앞선 두 개의 글 “feature store란?”, “모델 서빙이란?” 에서 관리의 중요성에 대하여 설명하였습니다. 데이터 과학자는 실험, 구현, 파이프라인 적용의 과정을 반복하며 정의하고 구현해야 합니다.
Airflow 설치를 로컬 환경에서 간단하게 셋업하고 DAG를 만드는 것에 대한 훌륭한 글( 설치방법 link, 튜토리얼 link )은 많습니다. 본문에서는 Airflow를 어떻게 구성해야 성공적인 MLOps를 만들어 나갈 수 있을지 AWS 환경에서 알아보도록 하겠습니다.
Step 1) 하나의 서버
가장 먼저 도입할 수 있는 가장 간단한 방식입니다. 대단한 MLOps 보다는 Airflow 도입을 고려한다면 시도해볼 수 있습니다. DevOps가 1~2일 정도면 충분히 구성할 수 있습니다. DevOps는 구성 후 DAG 와 플러그인이 저장될 폴더를 데이터 과학자에게 안내만 하면 됩니다. 최소한의 보안을 위해 Public / Private 서브넷은 구분하는것이 좋습니다.
컴퓨팅 자원이 한정적이기 때문에 무거운 연산을 하기에는 부담스럽습니다. 그리고 데이터 과학자가 사용하기 조금은 까다로울 수 있습니다. 매번 파이프라인을 수정하거나 추가할 때마다 ssh로 해당 인스턴스에 접근하고, 로컬 환경에서 작성한 코드를 옮겨야 합니다.
Step 2–1) Worker 의 확장
Step 1에서 단점이었던 컴퓨팅 자원 부족을 해결하기 위해선 다음 단계로 Worker를 확장해야 합니다. Airflow는 Worker의 확장이 쉽습니다. AWS 의 Auto Scaling을 활용하여 CeleryWorker를 손쉽게 늘리고 줄일 수 있습니다. 데이터 추출, 변형과 학습에 필요한 컴퓨팅 자원이 다를 수 있기 때문에, 사양이 다른 Pool을 준비할 수 있습니다.
이 환경에 치명적인 단점은 모든 인스턴스들의 환경이 homogeneous 해야합니다. Python 환경과 DAG와 Plugin폴더는 모든 인스턴스가 동일해야 합니다. airflow.cfg, DAG, Plugin와 같은 공유 파일들은 AWS EFS 와 같은 서비스를 활용하면 편리합니다.
모든 인스턴스의 homogeneous 하도록 유지하는 것은 상당히 까다로운 일이기 때문에 Docker 이미지를 제작하여 AWS ECS나 AWS EKS 를 활용하는 것이 좋습니다.
Step 2–2) 외부 서비스 활용
Step 2–1은 Worker가 직접 연산을 하는 것이었습니다. 이는 데이터 과학자가 데이터 분석을 위한 Python 스크립트에는 능숙하지만, AWS와 같은 외부 서비스의 활용 능력은 부족하다는 가정이 있었습니다. EMR, Lambda, Batch, SageMaker, Spark, Hive와 같은 데이터 분석과 학습 시스템에 능통하고 세부 작업들이 잘 구현 되어 있다면 이를 활용할 수 있습니다.
하지만 위와 같이 모든 기술 스택에 능한 사람은 찾기가 어렵습니다. 데이터 과학자는 파이프라인을 설계하고, DevOps는 인프라스트럭쳐를 준비하고, 데이터 엔지니어는 데이터 처리를 구현하고, 이를 한데 모아 Airflow의 DAG로 구현해야 합니다. MLOps의 다양한 진입장벽 중 가장 큰 부분을 차지하는 지점입니다. 관련 있는 모든 팀원들이 명확한 R&R을 가지고 분업이 잘 이루어져야 합니다.
Airflow는 어떻게 보면 단순히 연결된 작업을 수행하고 관찰하는 구조입니다. DAG가 어떤 작업을 하는지와 데이터와 모델의 관찰, 관리는 실험 단계에서 많은 연구가 있어야 합니다. 이 과정에서 세워진 가설을 파이프라인에 적용하고, 검증한 다음 가설을 다시 고쳐나가는 과정을 반복해야 합니다.
결국은 사용자 파이프라인을 자유롭게 다룰 수 있어야 하고, 문제가 발생해도 빠르게 대처할 수 있는 환경이 중요합니다. Airflow는 반복적인 작업을 수월하게 수행하고 관찰하는 좋은 도구입니다.
MLOps의 목표는 사용자에게 예측 서비스를 빠르게 전달하는 것입니다. 더 좋은 도구들이 있다면, Airflow를 고집할 필요는 없습니다. MLOps와 연관된 모든 실무자의 가장 익숙한 환경이 AWS라면 Step Function을 쓰면 됩니다. 어떤 도구를 쓰더라도 예측 서비스를 빠르게 전달하고, 파이프라인과 데이터, 모델을 잘 관리할 수 있다면 충분합니다.