Artificial Intelligence (AI) has made enormous strides in the last several years both due to the advent of technologies such as deep learning, and the cost-effectiveness and pervasiveness of supporting infrastructures, such as the evolution of GPUs, cloud computing, and open datasets and software. In a number of well-defined and significant tasks, including face recognition, machine translation and question answering, achieving or even crossing human-level performance is considered inevitable by mainstream researchers. The question naturally arises, what next? Many argue that due to the current interest in AI, not just in research and industry, but also geopolitics and national security, the decade is ripe for moonshot advancements that bring us closer to artificial general intelligence (AGI).
Despite talk of the singularity however, the challenges in truly accomplishing AGI are formidable, and recognized by the experts. For example, in interviews conducted in 2018 with 23 prominent researchers and stakeholders working in AI today (including Google AI chief Jeff Dean and Stanford AI Director Fei-Fei Li), Martin Ford reports in his book that, among the 18 who answered, the average estimate was that AGI was still at least 80 years away. A primary reason cited was that we were still missing the fundamental breakthroughs needed for machines to achieve a general and powerful model of intelligence.
These informal studies, buttressed by the precedent of AI history, suggest that rather than thinking of general intelligence in vague or hyperbolic terms, more fruitful progress can be made (and measured) by identifying and researching the critical capabilities that are needed to achieve AGI, guided by a scientifically established stream of work in allied fields such as cognitive science. I argue that one such capability is that we need AI systems to be more context-aware. However, before we get there, we need to ask ourselves, just what is context, and why is now the right time to be thinking about ‘imbuing’ AI with context?
The Oxford Dictionary defines context as the circumstances that form the setting for an event, statement, or idea, and in terms of which it can be fully understood and assessed. More academic treatments, such as in areas within the social sciences and humanities tend toward narrower, more precise terminology (e.g., one definition is that it is a frame that surrounds the event and provides resources for its appropriate interpretation).
No matter the definition adopted, we could well argue that, at an intuitive level, these definitions share many common threads, including the relativistic nature of context. Beyond a definition, it is important to explicitly address the question: why is context important for AI? We believe that the most effective way to answer this question is to present some representative examples below where context is shown to be vital for humans, including the seamless way in which we navigate everyday situations. The argument then proceeds: for an AI to successfully interact with humans, replicate, or supersede these abilities, it must be both aware of context, and be able to handle it appropriately, which may or may not mirror human cognition. I designate such a futuristic AI as a ‘context-rich AI.’ If AI had its own evolutionary tree, this milestone would be an important node in that tree.
Example 1: Context in Conversation
Philosophers of language and cognitive scientists are familiar with the conversational maxims proposed by Paul Grice as a model for why (and how) most people are able to make sense of conversation even when so much is left unsaid. The truth is that conversations rarely happen in a vacuum, but are situated in a context. The most immediate context might be the previous ‘sentence’ that was spoken, but it is only a small part of the conversational context. The people who are conversing, their roles in the conversation (e.g., an individual talking to another as a friend versus as a colleague), their individual goals in the conversation and the circumstances of the conversation (e.g., planned versus serendipitous) as well as the history of past conversations and shared contexts, all constitute the context around a particular conversation, though some aspects may dominate over others. One kind of AI that attempts to maintain and remember such long histories is a never-ending learning system such as NELL, but it has not been shown to be proficient at navigating in, or designed for, such personalized contexts. Chatbots that are currently being developed in industry would be the greatest beneficiaries of context-rich AI research that is able to take Grice’s maxims and conversational contexts more fully into account.
Example 2: Context as Background Knowledge
Background knowledge helps us navigate everyday life in more ways than we consciously realize. The example above also relied on background knowledge as a contextual aspect of conversation, at least to an extent. However, beyond conversation, background knowledge plays an important role in more abstract tasks such as planning. For example, when setting our calendars, we choose not to make business calls on Sunday because we know (or suspect) that the business might be closed on that day. Similarly, we plan ahead for summer vacations because experience has taught us that the summer is a heavy-demand period for vacations, and that we will not get good deals (or any deals) if we book closer to the anticipated vacation.
The influence of personal experience on background knowledge is an interesting one that is not completely settled, and is not deeply relevant to the topic at hand. There is ample evidence that some background knowledge is coded at the level of instincts and may have genetic or evolutionary origins (e.g., fear of snakes, but not electricity). Others are learned from experiences, while yet others are a combination of nature and nurture. This is generally true for many aspects of human cognition and is unlikely to be settled anytime soon. For AI research, the question is more pragmatic. Namely, for an AI to have a relatively complete ‘model’ of background knowledge and use it in a context-rich fashion, should it learn the model from large quantities of data (as language representation learning models, such as GPT-3 and BERT, in the NLP community, try to do) or should it instead apply powerful reasoning techniques on a core set of principles, common entities and relations? Proponents of deep learning believe in the former, but more recently, some researchers have started to explore the benefits of combining or encoding top-down AI principles in neural architectures.
Example 3: Expression and Behavior Adaptation in Social and Emotional Contexts
Human beings are able to adapt their behavior in varying social and emotional contexts. For example, an ordinary human being would not crack a joke at a funeral, and would be more conservative with humor in a work party than in a party with close friends. While humor is just one aspect of outward social interaction, many other examples can be construed that are similar, including formality of conversation, use of sarcasm, emotional intensity, choice of verbiage (e.g., explaining a concept to a layperson versus a scientific audience of experts) and even modality of expression (e.g., text message versus email). Currently, even AIs that are trained to produce conversation or text (including chatbots ,and automated email and sentence completion) only work properly in a very specific context, and are not able to adapt seamlessly with changing social and emotional context. A context-rich AI would be more human-like in its assessment of, and adaptation to, complex real-world settings.
I began this article by noting that there have been tremendous advances in AI. But specifically, just what advances suggest that context-aware AI might be on the horizon if we mobilize our efforts right?
Representation Learning
First, there have been some very exciting advances in the last decade in the field of representation learning. In fact, representation learning is intimately connected with the growth and success of deep learning. In the early days of machine learning, and even as recently as a decade ago, the primary machine learning workflow involved ‘feature engineering’ as a core step. The importance of feature engineering was so well recognized that it was, at times, difficult to gauge whether an improvement in state-of-the-art performance on some task (such as sentiment analysis) was due to an algorithmic or model innovation, or due to better feature engineering.
Today, representation learning has largely (though not completely) eliminated the need to painstakingly engineer and evaluate sets of features. The core idea behind learning a representation of a ‘data item’ (whether it’s an image, a document, or even a character in a long string of text) is to ‘embed’ it in a real-valued, low-dimensional vector space using a neural architecture. The argument is that such ‘embeddings’ capture key properties of the data using a small set of real numbers, without requiring manual feature engineering. Beyond improvements in performance that have been achieved using these methods, an impressive early finding (especially in the NLP community) was that such methods could capture analogies and other abstract relations that are evident in human cognition (e.g., the word2vec model could automatically complete analogies such as King is to man as Queen is to woman, despite never having been trained explicitly to do well on such tasks)
We note that the embedding of data in low-dimensional spaces is itself not novel: previously, topic models such as Latent Dirichlet Allocation (for text), and other classic dimension-reduction methods (for data that was represented more abstractly or was otherwise vectorized already) had already achieved some breakthrough innovations in this area. Today, however, representation learning is almost exclusively associated with neural representation learning. The topic receives wide coverage in the top machine learning conferences, including NeurIPS and the International Conference on Learning Representations (ICLR).
In the NLP community, the earliest representation learning algorithms following the advent of neural networks have assumed a local definition of context. For example, the famous word2vec models (skip-gram and continuous-bag-of-words) slide a ‘window’ of a pre-specified size over the text, and use the words in the window flanking the target word as co-context. Similarly, the GloVE model uses a matrix of co-occurring words. In the data mining community, researchers have shown that the premise behind word2vec can even be applied to graphs, and have used it to learn representations for the nodes in a graph (such as a social network). At the time this was first proposed (mid-2010s), state-of-the-art performance was achieved for important data mining tasks such as link prediction, using considerably simpler systems than had been previously proposed.
Gradually, the definition of context has broadened, along with (not coincidentally) the advent of more powerful and novel neural network models such as transformers, which have led to new-age embedding models such as BERT, RoBERTa, and GPT-3. Among other capabilities, such models have the capability of retrieving different embeddings of the same word based on the sentence in which the word is situated. Context has, therefore, started to play a direct role, even after the training is finished. Transformers are inherently (and explicitly) more context-friendly than some of the other models that came before them. Research on transformers continues at a frenetic pace, and more recently, they have even been applied in computer vision, with promising results. As we learn more about these models, and continue to apply them to a wide range of problems, more technical advances in context-rich AI seem inevitable.
Commonsense Reasoning and Knowledge
Commonsense reasoning involves processing information about a scenario in the world, and making inferences and decisions by using not only the explicit information available to the senses and conscious mind, but also context and implicit information that is based on our commonsense knowledge. Commonsense knowledge is difficult to define precisely (not unlike intelligence itself) but it may be assumed to be a broad body of knowledge of how the world works. While interesting also to cognitive scientists and philosophers, commonsense reasoning is intriguing to specialists in AI because it has also revealed potential pitfalls in the manner in which such reasoning systems are traditionally evaluated (i.e., using one or more multiple choice question answering or QA benchmarks) . While such evaluations have been criticized for not being challenging enough, recently, generative QA tasks were proposed and are slated to grow in popularity. Because generative QA can result in open-ended answers, more innovation is needed on how to evaluate the ‘goodness’ of a system’s answers without always relying on human annotation that is available on-demand, such as in a crowdsourcing framework.
I believe that these dynamic strands of research, both in terms of evaluation design and the core research area of building better commonsense reasoning systems, will directly yield advances in context-rich AI that is able to navigate and reason about the real world in a more robust and human-like manner. Industry is vested in this area as well because advances in commonsense AI are expected to lead to better human-AI collaboration, including more ‘naturalistic’ chatbots.
Knowledge Graphs and Semantic Web
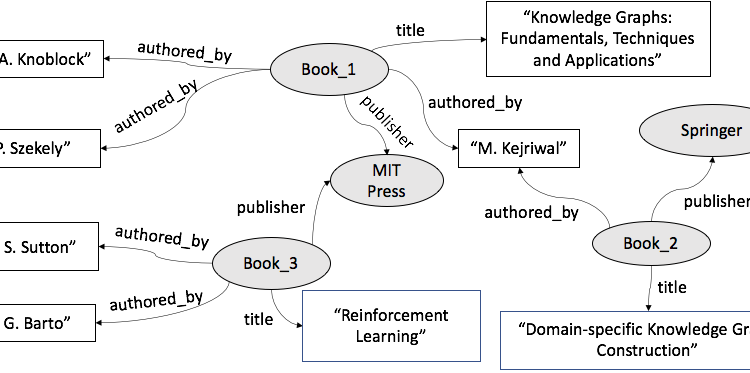
Graphs have been ubiquitous in AI since its founding, but have tended to be more associated with the planning community. With the publishing of Google’s influential post on ‘things, not strings’ in 2011, knowledge graphs (KGs) have come to be recognized as a flexible and data-driven way of modeling a domain using entities, relations, and events, rather than as collections of primitives (e.g., strings and numbers) that are lacking in semantics. The figure below illustrates a simple domain-specific knowledge graph over the Books domain. Companies like Google and Microsoft have taken this concept much further, and the Google Knowledge Graph is known to be a web-scale graph constructed in a data-driven fashion from numerous sources and over broad domains. The Google Knowledge Graph underlies at least some of the search artifacts (such as a knowledge panel) that are produced in response to queries like ‘Leonardo da Vinci’. Knowledge graphs have led to enormous advanced in both generic and domain-specific (e.g., e-commerce) search, and are being constructed in some form in almost all the big technology companies. COVID-19 knowledge graphs were even constructed in the earliest days of the pandemic.
KG research has a closer connection to context-rich AI than may initially meet the eye. First, KGs are (typically) populated according to a domain model, called an ontology, that contains the concepts, constraints and relations that serve to define both the scope and vocabulary of a domain. It would not be incorrect to say that a KG exists in the context of a domain and a task (or set of tasks), with the former defined using frameworks such as the Web Ontology Language (OWL). For example, the ontology underlying the KG in the figure may contain concepts such as ‘book’, ‘person’ and ‘publisher’ (among others), and relations such as ‘author_of’ and ‘publisher_of’. Concepts and relations may have sub-concepts and sub-relations; for example, an ‘author’ concept that is a sub-class of ‘person’ could be declared in the ontology. These relations connect the entities (which are formally instances of concepts) in the KG. Constraints, which are not visible on the surface, prevent unwanted declarations in the KG (e.g., one reasonable constraint might be that the range of the ‘author_of’ relation must be an instance of a ‘person’ concept).
The Semantic Web community has conducted much research over the years on rigorous ways to formally express ontologies and knowledge graphs, and has even developed reasoning engines to infer more facts than are explicitly declared in the KG. More recently, KG research has intersected with both representation learning and commonsense reasoning. We hypothesize that KGs will continue to play an important role in the development of context-rich AI. This claim conforms with that of several consulting companies that have mentioned knowledge graphs and ontologies in recent technological projections.
Explainable AI
Explainable AI has witnessed a resurgence in the last 5–7 years, both due to interest from the community and well-funded programs such as the Explainable AI (XAI) program that was instituted by the United States Defense Advanced Research Projects Agency (DARPA) in the mid 2010s. According to the program’s website, a central goal of the program is to ‘produce more explainable models, while maintaining a high level of learning performance.’ The definition of explainable AI is more straightforward less controversial than commonsense reasoning, where agreement on a single definition and set of tasks has been lacking (though has also converged greatly over the last two years).
While the direct connection between explainable AI, and some of the other research areas such as knowledge graphs, representation learning and commonsense reasoning, is not fully evident, the argument is that any AI system that exhibits the kind of robustness that would be expected of human intelligence should have the capacity to explain itself. For example, an explanation-capability ought to be a defining feature of a commonsense reasoner that is asked to provide a justification for an answer or action. Current language models that have achieved state-of-the-art performance in commonsense QA tasks do not seem to have this capability (at least in their current state).
Context-rich AI would be able to generate convincing explanations by leveraging its context and background knowledge. An advantage of an explanation-capability that is often under-appreciated in the computing community is that it makes the AI more trustworthy to non-developers and domain scientists who can probe the AI for the reasoning behind its decisions. The DARPA XAI program mentioned above also mentions as its the goal the development of a suite of machine learning techniques that ‘enable human users to understand, appropriately trust, and effectively manage the emerging generation of artificially intelligent partners.’ It is not hard to see that research in explainable AI will naturally complement context-rich AI, since they can both inform each other’s progress.
Beyond the rapid advances in such research areas, a much more pragmatic cause is that the attention (and accompanying resources) that is being bestowed on AI. In fact, a range of supporting ecosystems, both in industry and through governmental bodies such as national funding agencies, seem to be flourishing at the present moment. This is important, because in today’s hyper-competitive and short-attention economy, it is difficult to rally interest in a field unless there are incentives and supporting infrastructures in place. In academia, funding continues to become more competitive, and research budgets have come under strain, particularly for non-medical research. The fact that funding opportunities for developing more context-rich AI already exist (with some having been launched very recently) is an encouraging finding, suggesting that context-rich AI will get the attention it deserves. Below, I focus primarily on supporting ecosystems in the United States, though similar findings apply both in China (where AI research has accelerated immensely over the last few years) and in the European Union.
In the United States, the National Science Foundation (NSF), has instituted multiple programs where context-rich AI is going to play a key role, although the development of such an AI is not the ‘direct’ aim of the effort. One example is the relatively recent call for AI Institutes, a joint government effort between NSF, the U.S. Department of Agriculture (USDA), National Institute of Food and Agriculture (NIFA), the U.S. Department of Homeland Security (DHS) Science & Technology Directorate (S&T), and the U.S. Department of Transportation (DOT) Federal Highway Administration (FHWA). It also involves significant industry participation from the likes of Amazon and Google (among others). Simply put, these institutes are meant to facilitate ‘new and sustained research in AI to drive science and technology progress.’ Teams comprising one or more organizations can submit proposals to one of eight themes. One of these themes is ‘human-AI interaction and collaboration.’ Earlier, I argued that, for seamless human-AI interaction and collaboration to occur, an AI must necessarily (though not sufficiently) be context-rich. Some other themes also have relevance to context-rich AI, including AI-Augmented Learning. While this is the most direct and well-funded example of context-rich AI enablement (with an anticipated funding of $128 to $160 million over 8 institute selections), in recent years, other similar but smaller-scale multi-disciplinary AI programs have also been announced.
I believe that, given current progress in AI, context-aware (and its close sibling, context-rich) AI is realizable within this decade, due to a confluence of favorable factors, including sufficient maturity of underlying technologies, interest from various communities (especially those coming off of recent successes in deep learning and applied AI), and supporting ecosystems that see advanced AI research as geopolitically necessary. An exciting outcome of developing context-rich AI is that it would greatly benefit non-profits and government, especially in topical areas like disaster relief and crisis management. This would be especially remarkable considering that such bodies have not historically been associated with, or reaped the advantages of, cutting-edge computing technology. Building trustworthy and explainable AI is an especially important goal if the technology is to witness greater uptake in government agencies and the non-profit sector. However, without recognizing its proper context, it is not clear how an AI could be either trustworthy or explainable.
Despite the rosy outlook above, many challenges remain in realizing the vision of a context-aware AI. The history of AI, starting from its earliest days, has shown that we tend to be over-optimistic about AI’s capabilities, leading to AI winters characterized by disappointed expectations and a drying up of funding and other resources. Therefore, it is incumbent upon us to be vigilant about our goals, and promoting the scope and promise of context-aware AI research in measured and objective ways.