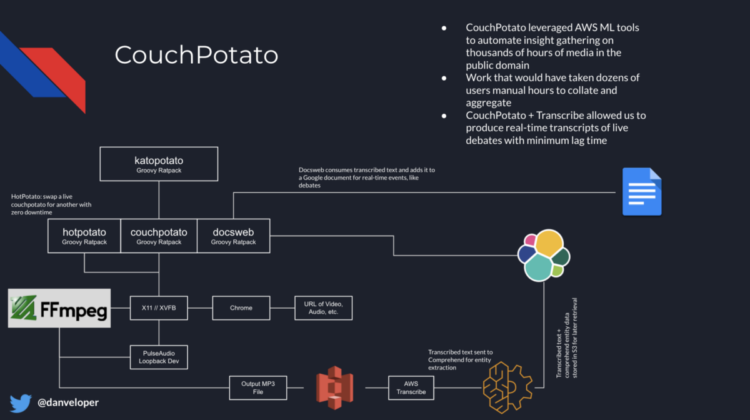
At the end of last year, I gave a presentation at QConPlus about some of the more interesting software architectures we ended up building on the Biden for President campaign. The last architecture I discussed was that of CouchPotato, which was essentially a media intelligence platform we built to quickly extract meaning from a video or body of text. CouchPotato became an important resource in our environment and serviced a number of use cases both in background automation and end user tooling. A big use case, and the original reason we built CouchPotato, was for transcribing debates in real time.
What we learned over the course of the Primary that while having a running transcript of the debate is valuable, there was still plenty of human involvement required to properly label segments of the text according to who was speaking. We grew CouchPotato’s transcription functionality to incorporate computer vision and artificial intelligence to solve that problem.
Taking a step back for a moment to touch on the role of artificial intelligence, it is important to remember where the Democratic Primary field was in early-to-mid 2019. There were 24 Democratic campaigns, which included extremely skilled, knowledgable, and inspiring candidates. This meant two very important things: the pool of talent in the campaign staffer ecosystem was spread widely across the field; and the money from donations was broadly distributed as well. On the Biden for President campaign, we knew from the outset that we would have to be a small and scrappy campaign, and we would have to make due with the resources we had available.
In practical terms, being a small and scrappy campaign meant that we wouldn’t have the fleet of interns and volunteers that could’ve been expected in years past. On the tech team, we looked at this as an opportunity to find areas where we could leverage artificial intelligence to pick up pieces of work that we normally would have been handled by human beings. Writing down what each candidate said during a debate was one such task, and since speech-to-text technology had improved so much in the last couple years, it was an easy goal for us to wire up a system to transcribe debates in real time and write the text out to a shared Google Doc. The communications and research teams needed the debate transcript in real time, so having it fast and accurate was a major design goal.
(There’s a lot to be said on how we made this work in practice, but is probably too much for this write-up. Simply put, the Google Docs API is not well suited for appended-streaming of text, so we had to automate an X11 session with Chrome logged in and on the shared document, and then programmatically send keyboard commands from an API that received the blobs of text. This was really hard to pull off synchronously, and I’ll leave it at that for now!)
While the transcriptions alone were valuable, the wall of text produced by AWS Transcribe still required somebody to go into the document and manually add who was speaking for what segment of text. We attached a clip of the video for the given segment to better help figure out who the speaker was, but for some of the debates there were dozens of candidates and they were not always immediately recognizable. We hypothesized that there existed the right set of technology in the machine learning ecosystem to solve this problem automatically, and so we set out to find the solution.
Anybody who’s done any kind of artificial intelligence with computer vision will tell you that real-time inference is extremely taxing on even the highest end computers. We wouldn’t have a fleet of high-end systems with multiple GPUs, and even if we did that’s not the level of infrastructure I was interested in building on the campaign. (I would’ve just as soon scrapped the whole project if we couldn’t make it work on relatively low-to-mid-tier system. The cost-to-benefit just wasn’t there.)
Where we decided to focus our efforts was on processing audio, since we knew we could do it relatively quickly, the overall size of the data was much smaller than video, and we were already producing an isolated audio segment that we delivered to Transcribe. However, speaker classification in audio was far from a solved problem, and not something that was reliable in cloud AI tools at this point, but we hypothesized we could build a system to extract speakers from audio and do it with fairly low-end systems.
Audio Classification with MFCCs
The best way to do any kind of classification in audio signals is by extracting a set of features known as Mel Frequency Cepstral Coefficients (MFCCs). Similar sounding audio will have computationally similar MFCCs and by processing the coefficients against pre-trained data, you can collate on a pre-defined classification. I’m not going to pretend to fully understand the science and mathematics behind all of this — I am not a digital signal engineer by any stretch of the imagination — but the python open source ecosystem is plentiful with libraries that make extracting MFCCs incredibly simple. We ended up using librosa , which integrated nicely with numpy, which we would need for the next step.
The idea from here was seemingly straight-forward. We would gather a set of training audio for each speaker we needed to recognize and train a classifying convolutional neural network on the features of the MFCCs. We could then use the trained network for inference, and we’d get back a score on who the network thinks is talking. We used tensorflow and keras to build the neural network, and trained it on the first 13 MFCC features. There was a lot of preparation work on the audio to scale the signals across the training set: reducing to single channel, background noise reduction, frequency modulation, and so forth.
We learned a lot through this process, but it’s enough to say this just didn’t work for us. The core of the problem is the differences in how speakers sound depending on the source of the broadcast. For example, radio and podcast audio was usually very clear and gave really good results. TV interviews and floor debates had differing levels of quality, and that bled through in the feature extraction. The exploration into audio-only speaker classification ended with high-confidence results when it was from the same broadcast source, but zero confidence on the trained model when running inference on a different audio source.
Personally, I’m convinced speaker classification is solvable using only MFCCs, but it will take a lot of work to figure out the edge cases of normalizing audio signals for differing input sources. That was more research and development than I was prepared to invest while building this solution on the campaign. (I give a lot of credit to engineers at companies that are solving this problem without having a complementary video source.)
Speaker Classification with Audio and Video
Since we knew our use case specifically was for debates, we knew we would have both audio and video, which we could use as complementary sources of data to solve this problem. We revisited our assumption that real-time video processing would be too taxing and require too much infrastructure for any of this to be worth it. To that end, we got started on a plan to reduce the overhead with inference.
The plan here was a little less novel than a high-speed neural network, and was actually fairly straight-forward to start with. We would take the output from Transcribe, which returned to us in structured JSON format, and we would analyze the corresponding video segments to figure out who was speaking.
Before I can dive into the specifics of how we made this work, it’s important to understand how useful the data coming out of Transcribe is to the whole process. The resulting JSON payload that looks like this:
{
"jobName": “xxx”,
"accountId": “xxx”,
"results": {
"transcripts": [
{
"transcript": “<fully transcribed text>“
}
],
"items": [
{
"start_time": "1.11",
"end_time": "1.28",
"alternatives": [
{
"confidence": "0.9521",
"content": "We're"
}
],
"type": "pronunciation"
},
{
"start_time": "1.28",
"end_time": "1.35",
"alternatives": [
{
"confidence": "1.0",
"content": "in"
}
],
"type": "pronunciation"
},
...
In addition to the full transcript text, which we had already been using to stream to the Google Doc, the items array contains objects for each individual word with qualities for confidence as well as start time and end time (in seconds) for where the word was inferred in the steam. We reasoned that when an individual was speaking they would be on camera. The idea was to correlate the time a word was being said with the same frame from the video, and we could use simple facial recognition to figure out who it was.
Facial recognition is very much a solved problem, and there are mature libraries that integrate with OpenCV to make this process virtually no development effort. The system was mostly reliable, except for three key problems to address.
First, even with multithreading it was slow to process the video frames for each word in the transcript. Where you have a broadcast video at 30 frames per seconds, our code took that down to about 9 frames per second, and this was already after the five to ten minute tax for Transcribe to return the JSON. This meant our Google Doc was nowhere near real-time, and that made it kind of useless.
Second, while it’s usually true the speaker is in frame, it’s not always true. Especially during the debates with a dozen or more candidates. They would interject at various times and the camera would whip to try to get them on screen, but there wasn’t always a clean correlation of voice and speaker. Furthermore, candidates would talk over one another, causing pandemonium for the AI to figure out what was going on.
Third and most important was how the camera framed the speakers during their segments. If Biden and Bernie were next to each other on stage, you could bet the camera would have both of them in frame while one or the other was speaking. Sometimes, all the candidates were in frame and we couldn’t get any classification confidence because the naive code could not determine which face was the speaker.
We deemed these all solvable problems with a few tweaks here and there, and even building off some of our learnings from the experiments with MFCCs. We had to build a more intelligent artificial intelligence that understood the context of political debate and could mitigate the aforementioned problems
Flappy Lips
At this point, we were using OpenCV and dlib to find people within the frame, and that part was working well enough (except for the speed issue). The dlib library worked out great for us because its human face recognition neural network was far superior in terms of inference speed when compared with alternatives. What we needed next was to figure out which of the faces in the frame represented the speaker
After some experimentation and research, we learned that we could isolate the lip movement of an individual face across two frames, and if the difference between the lips met a threshold (we chose 60%, but it worked with a range of values) we could classify that person as the speaker.
We validated this process on thousands of frames of lip movements and we came to affectionately refer to the program as “flappy lips”.
The problem of reducing all possible speakers to the one actually speaking was solved, but now we had to solve the speed problem. When we look at the video with overlay analysis (green boxes around the faces) from flappy lips, we realized it was spending a lot of compute time re-recognizing faces for each frame. Since we had already recognized each in-frame face once, it was a waste to have to redo it for every frame of the video.
What we had from dlib was a set of rectangular coordinates around the speaker’s face, and what we hypothesized was that we could use mean shift tracking between frames to follow the already-identified face. We used the object tracking feature in OpenCV for this and from there we improved processing time dramatically.
Flappy lips was now a working proof that under perfect conditions we could process the audio and video, identify the speaker, and classify the segment of transcript in near real-time. But we still had one last major problem to solve, which was the fact that the camera could not be relied upon completely to have the speaker in frame, especially when one candidate was out of frame and speaking while another candidate was already speaking. This became a common issue and led to a lot of mis-labeling.
Speech Clustering
While we knew that MFCC feature analysis alone wouldn’t be something we could (or should) properly build out, we did still have the understanding that MFCC features were reliable under the conditions of the same broadcast. To say that more simply, we could figure out who a speaker was so long as it was from the same debate because the audio would be the same throughout.
This gave us an additional data point we could use in conjunction with what flappy lips was already able to do on its own. We wouldn’t be able to train a neural network on the fly in real time to identify speakers, so we needed a different plan to narrow down who was speaking and when. We theorized a number of different ways we could use MFCCs to help better figure out who was speaking, as well as if they were in fact the person on frame, and if they weren’t the person on the frame we could figure out who they were.
A lot of trial and error got us to this: we could time bucket a segment of audio and extract MFCCs for each time bucket, then we could use a k-nearest neighbor algorithm to classify each voice in the audio segment. We used scipy for generating k-NN clusters, which gave us numbered labels for each distinct speaker.
It wasn’t a perfect solution on its own, since it would sometimes classify the same speaker under different labels depending on how vibrant they chose to speak, but it did give us distinct isolated sections in the audio segment where we could go look at the video to figure out who was the person speaking for a contiguous bucket of time.
This is all very complicated wording, so let me throw out an example: Biden would speak from 0 seconds to 3 seconds, then off camera Bernie would say something from 3 seconds to 5 seconds — the camera didn’t have time to move off Biden, so flappy lips would think he said what Bernie actually said and classify it accordingly. With our k-NN clusters, we could identify that someone spoke from 0 to 3, then someone different spoke from 3 to 5. We could then ask flappy lips to tell us who was speaking from 0 to 3 and it would tell us Biden. Then we could ask who spoke from 3 to 5 and it would tell us Biden again, but since they were different clusters we knew that wasn’t right and we could file it off for later analysis. At some point later in the segment, Bernie is on frame and speaking, so we have a validated segment of his audio, which we could then compare back to the unidentified speaker blocks, and we’d find the MFCCs aligned well and we could label it accordingly. And the process repeats.
Conclusion
The final system was a combination of AWS Transcribe, video analysis and facial recognition, and k-NN clustering of MFCC features that ended up getting us the most reliable artificial intelligence. We still had plenty of moments where the system could not figure out who the speaker was and in those cases we just had it append an “UNKNOWN” label in the transcript.
Overall the process worked extremely well to eliminate human involvement in figuring out who was speaking at which point. This allowed those people to focus on more important work (like correcting instances where Transcribe could not figure out Mayor Pete’s last name… is it “Buddha judge”?).
I’m confident a question I will get asked a lot will be: “is the code going to be open sourced?” And the answer is, I doubt it. Like most of the software we wrote on the campaign, it was built rapidly and to our specific team’s capabilities. What that means is it was riddled with hacks and bugs that we were able to quickly mitigate when problems came up. And since this wasn’t a lifeblood-critical system we didn’t invest a lot of time in project structure, testing, or really figuring out how it could run for more than a dozen or so times in its lifespan.
The truth is, although this is a lot of really interesting and complex technology, this wasn’t the primary responsibility for anybody on the team. The team just kind of picked it up when there were dips in other work, and it ended up being a really cool and useful tool, but far from an open source-able product. It goes to show what you can accomplish when you have a team of highly skilled and motivated engineers working to make a positive impact on the lives of everyone around them.