For ease of business customers, we have to increasingly digitize customer journeys. Thereby there is vast data that is generated from customer channels and service touchpoints. This data is either information willingly provided by customers or vast data generated as logs from systems and their processing.
Progressively, in the world of IoT, we are seeing decisions made by machines. These decisions either churn-up insights on what’s better for customers or reducing their anxiety in their service-relationship. For the machine-models to generate actionable insights, diverse data of good quality, is required in real-time to be available.
In1960’s data was supposedly managed in silos, often physically while there were also limited skillsets to churn insights. However, people who were investing in curating good quality information reaped better revenues.
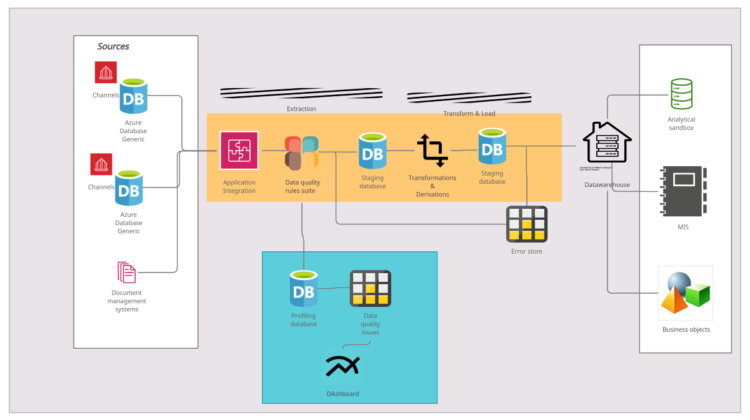
Then there is an onset of business Intelligence solutions which can be termed as a vintage capability today. Yet, is an effective way of consuming data for reports and analytical models. For years, organizations have focused on moving data into a single reference store like a warehouse with a capability like Extract-Transform-Load (ETL). This is the Gen-1 data quality model popularly embraced by firms.
Before data is loaded into a warehouse, the quality of data is assessed for contextual dimensions of quality like validity. Such models can be termed as generation-1 data quality management models.
From a need to deal with datasets that are often too large and diverse in structure to handle — bigdata as a capability has evolved. Though a lake uses the concept of Extract Load & Transform, data is assessed for quality while extracting and loading data into landing storage.
We cannot stress less on the quality of data in motion that is constantly used to serve real-time artificial intelligence models including fraud detection and other consuming campaign and analytical processes. The first Data Quality challenge is most often the acquisition of the right data for Machine Learning Enterprise Use cases.
Wrong Data — Even though the business objective is clear, data scientists may not be able to find the right data to use as inputs to the ML service/algorithm to achieve the desired outcomes.
As any data scientist will tell you, developing the model is less complex than understanding and approaching the problem/use-case the right way. Identifying appropriate data can be a significant challenge. You must have the “right data.”
the term Coverage is used to describe whether all of the right data is included. For example, in an investment management firm, there can be different segments of customers as well as different sub-products associated with these customers. Without including all the transactions (rows) describing customers and associated products, your machine learning results may be biased or flat out misleading. It is acknowledged that collecting ALL of the data (often from different sub-entities, point of sale systems, partners, etc.) can be hard, but it’s critical to your outcome.
It is imperative to look for the quality of data that is being streamed into the landscape by external actors including customers, external partners, and sensors to name a few. The approach to finding data quality issues can be specifically associated with certain dimensions.
- Completeness — Is data as per your expectations of what’s complete?
- Consistency — ensuring structural, semantic consistency and enforcing business-policy
- Timeliness — Is data having a system or manual lag?
- Validity — Is data streamed in a designated format and is it usable as per standards
- Uniqueness — Does similar data exists already as an instance within the ecosystem?
Let us look at an architecture that automatically processes data for quality even before it lands. This is quite different from the choice where data is piped into a landing zone and traditionally assessed for quality. Often data comes in at higher velocity as it deserves processing in real-time. At the same time, characteristics of high velocity can be coupled with quality management.
- Create a customer application that captures customer demography details
- Declare 2 consuming applications — one for MDM and the other for the analytical sandbox.
- Run an incremental quality analysis on arriving data from the online portal where customers are registering themselves for a product
- Run a data quality test on arriving data using ksql using consistency and validity data quality rules
- Send notifications back to customers, based on validation results
- Capture the metrics in the dashboard for visualization
Note — The choice of the stack has been chosen to be native rather than using Kafkaconnect.
- Instantiate a stream of customer data using Python
I am using Faker to generate customer data while also using attributes name, address, phone number, job, email, date of birth. I have used IntelliJ to run the scripts.
Note: In the project -structure, modify the Project SDK to Python 3.6. Also install the packages — Faker 5.8.0, coverage 5.4, kafka-python 2.0.2, pip 21.0.1, pymongo 3.11.2, python-dateutil 2.8.1, setuptools 52.0.0, six 1.15.0, text-unidecode 1.3 1.3
Start a new Python script named data.py and import Faker
from faker import Fakerfake = Faker()
def get_registered_user():
return {
"name": fake.name(),
"address": fake.address(),
"phone": fake.phone_number(),
"job": fake.job(),
"email": fake.email(),
"dob": fake.date(),
"created_at": fake.year()
}
if __name__ == "__main__":
print(get_registered_user())
2. Install Confluent Kafka & create Topic
Confluent platform trial can be downloaded from the link — https://docs.confluent.io/platform/current/quickstart/ce-quickstart.html
confluent local services start
Your output should resemble something like below
Starting Zookeeper
Zookeeper is [UP]
Starting Kafka
Kafka is [UP]
Starting Schema Registry
Schema Registry is [UP]
Starting Kafka REST
Kafka REST is [UP]
Starting Connect
Connect is [UP]
Starting KSQL Server
KSQL Server is [UP]
Starting Control Center
Control Center is [UP]
The first step upon getting the services up is to create a topic custchannel.
kafka-topics — bootstrap-server localhost:9092 — topic custchannel — create
3. Create a producer using Python, that sends data continuously
Create a new Python script named producer_cust_ch.py and import JSON, time.sleep, and KafkaProducer from our brand new Kafka-Python library.
from time import sleep
from json import dumps
from kafka import KafkaProducer
Then initialize a Kafka producer
- bootstrap_servers=[‘localhost:9092’]: sets the host and port the producer should contact to bootstrap initial cluster metadata.
- value_serializer=lambda x: dumps(x).encode(‘utf-8’): a function that states the way data is to be serialized before sending to the broker. Here, we convert the data to a JSON file and encode it to utf-8.
producer = KafkaProducer(bootstrap_servers=['localhost:9092'],
value_serializer=lambda x:
dumps(x).encode('utf-8'))
The code below will create customer records from the method defined earlier using Faker in step-1. Let us generate customer records in an infinite loop, while you can terminate the producer anytime from the UI. In the same loop, data will be piped to the producer using the send method.
if __name__ == "__main__":
while 1 == 1:
registered_user = get_registered_user()
print(registered_user)
producer.send("custchannel", registered_user)
time.sleep(10)