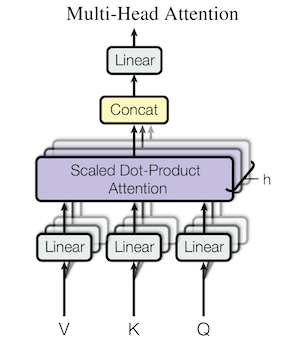
If I say transformer paper disrupted the entire AI/ML community, I wouldn’t exaggerate. We are now seeing an entire line of work based on transformers, not only in the original NLP domain but also in the computer vision domain. I’d like to list a couple of recent popular works that came out recently:
- In the NLP domain, GPT-2 [6], BERT [7], and, lately, GPT-3 [8]became state of the art. No need to mention how popular they became.
- In the computer vision domain, Image Transformer [9] and recently Vision Transformer [10] are worth mentioning.
Note: this is far from a comprehensive list, and I skipped a ton of great papers.
In conclusion, I’m sure that we’ll see a lot more work will come out based on transformers. So, if you are interested in moving the needle of state of the art, attend to self-attention and the transformer.
References
[1] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., Polosukhin, I., Kaiser, L., Polosukhin, I., Kaiser, Ł., & Polosukhin, I. (2017). Attention is All You Need. Advances in Neural Information Processing Systems, 2017–Decem, 5999–6009. https://arxiv.org/pdf/1706.03762.pdf
[2] Bahdanau, D., Cho, K. H., & Bengio, Y. (2014). Neural Machine Translation by Jointly Learning to Align and Translate. ArXiv E-Prints, arXiv:1409.0473.
[3] Xu, K., Ba, J. L., Kiros, R., Cho, K., Courville, A. C., Salakhutdinov, R., Zemel, R. S., & Bengio, Y. (2015). Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. CoRR, abs/1502.0, 2048–2057. http://arxiv.org/abs/1502.03044
[4] Mnih, V., Heess, N., Graves, A., & kavukcuoglu, K. (2014). Recurrent models of visual attention. Advances in Neural Information Processing Systems, 3(January), 2204–2212.
[5] Ba, J. L., Mnih, V., & Kavukcuoglu, K. (2015). Multiple object recognition with visual attention. 3rd International Conference on Learning Representations, ICLR 2015 — Conference Track Proceedings, 1–10. http://arxiv.org/abs/1412.7755
[6] Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language Models are Unsupervised Multitask Learners.
[7] Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of the 2019 Conference of the North {A}merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 4171–4186. https://doi.org/10.18653/v1/N19-1423
[8] Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., … Amodei, D. (2020). Language models are few-shot learners. In arXiv. arXiv. http://arxiv.org/abs/2005.14165
[9] Parmar, N., Vaswani, A., Uszkoreit, J., Kaiser, L., Shazeer, N., Ku, A., & Tran, D. (2018). Image transformer. 35th International Conference on Machine Learning, ICML 2018, 9, 6453–6462. http://arxiv.org/abs/1802.05751
[10] Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., & Houlsby, N. (2020). An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale. http://arxiv.org/abs/2010.11929