Supervised and unsupervised machine learning are two important streams of machine learning (there are others also like reinforcement learning, semi-supervised learning etc., but here we need not to bother about those). In supervised learning we are given, what is called a ‘labelled’ data, which is generally in the form of input-output pairs and the task of machine learning is to learning the mapping between these input-out pairs. Linear regression, in which we the output linearly depends on the fitting parameters, is the most commonly known type of supervised learning. Other examples are logistic regression, support vector machine (svm), decision trees and neural network.
Clustering is the most basic and common example of unsupervised learning, in which unlabelled data (only input given) is grouped into a user defined numbers of clusters on the basis of some proximity criteria. Clustering plays an important role in many practical applications such as dimensionality reduction and outlier and anomaly detections.
The idea and algorithm behind K-means clustering is quite simple : we partition the data into ‘K’ number of clusters, where ‘K’ is supplied by the user.
The steps involved in K-means clustering are as follows:
- Chose k number of random points as centers (centroids) of k-clusters.
- Associate each point to one of the clusters on the basis of its proximity to the centers of the clusters.
- Recompute centroids on the basis of the data point belonging to different clusters.
- Keep repeating the procedure till centroids do not stop changing their values.
The full code is given here and here I just want to make some comments about the code. The code does not use any library and builds the logic from the scratch, however, it does need you understand the use of the following three python libraries.
- Numpy — Numpy is used for generating random numbers, computing mathematical functions and doing some simple array mathematics like finding the maximum/minimum points in an array.
- Pandas — Pandas data frames are used to represent the data which makes it very easy to move around and manipulate data. You can appreciate the use of pandas data frame once you start using those. Here I add one extra columns in the data frame for the cluster membership of the data points.
- Matplotlib — This library is used for showing the scatter plot of the data points.
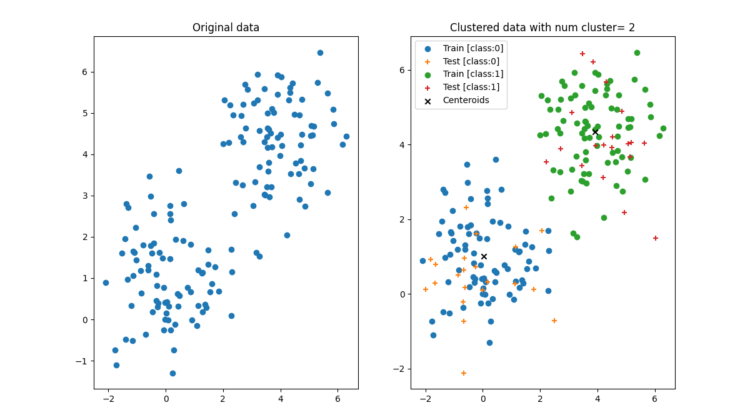
Figure 1: The left panel shows a set of data points scattered over a two-dimensional plane and the right panel shows the k-means clustering with k=2. Note that the cross ‘x’ in the right panel show the centroids of the clusters.
The left panel shows a set of data points which are represented by a pandas data frame with two columns — ‘x’ and ‘y’. The k-means clustering adds once extra column ‘cid’ in the data frame that has the id of the cluster a data point belongs.
We split the data points into group one for training (shown by the filled circles in the right panel) and another for testing (shown by ‘+’ in the right panel).
Let us first focus on the training data. The algorithm is able to split the training data points into two clusters represented by two different colours. Now once our model is trained (we have found the centroids of the two clusters) we can use that to find the membership of the training data set points, as is shown by the different colours for the ‘+’ points. From the right panel we can see that the algorithm is able to cluster the test data points also very well.
Here the most important issue is to decide how many clusters one should use and the clue for that is as follows.
Let us define residue r(i) for a point ‘i’ by its distance from the center of the cluster it belongs. Now if we compute the sum of the squares of the residues for all the points (let us call this quantity S2) then it will be different for the different number of clusters. It is a common practice to plot it in a curve called the ‘Elbow plot’. Here, the code I am giving does not have any elbow plot but you can use to compute S2 for different number of clusters and can see the value. Below is the clustering shown for k=3,4,5 and 6.
If you find the article please like / clap and comment.
For the full code click here.