Custom In-App Voice Assistants
Want to build a custom Voice Assistant for your app? Do NOT build one from scratch. It’s harder than it looks
Voice as an interface is becoming more mainstream. Most likely the reader has experienced Voice interfaces when interacting with general-purpose Assistants like Alexa or Google Assistant or Siri. More and more brands are also adding custom In-App Voice Assistants to their mobile and web apps to enable their users to access their services faster and a lot easier. But building a custom In-App Voice Assistant is deceptively complex and requires multiple people working with different skill sets, working together for many months. Flipkart took 2 years to build its In-App Voice Assistant, even after acquiring a specialist Voice company, Liv.ai. ConfirmTkt took almost 18 man-months to get their In-App Voice Assistant built for the ticketing app.
Flipkart took 2 years to build its In-App Voice Assistant, even after acquiring a specialist Voice company, Liv.ai
Why does it take so long? What are the various things that one should consider when building their own custom In-App Voice Assistant? This blog tries to dissect the process of building one and argues why the world needs Voice Assistants to be delivered as a service rather than everyone needing to build out their own from scratch.
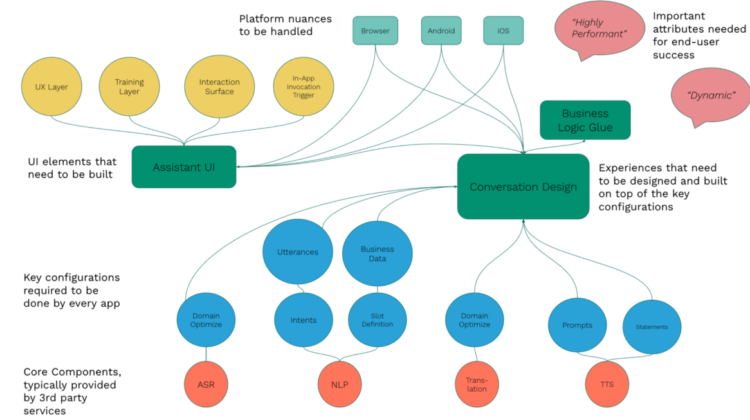
At the core of any In-App Voice Assistants are 4 fundamental technology components.
Automatic Speech Recognition (ASR)
The speech to text service converts the speech captured via the microphone on the device to text in the language spoken by the user. Google is the pioneer in this service and provides both platform-specific (Android APIs) and a more powerful cloud-based service as part of its GCP offerings.
Natural Language Processing (NLP)
This service takes as input the text representing the user’s speech, classifies it based on the intent, and also extracts data from it. E.g. when the user says
“Book a ticket from Bangalore to Chennai for tomorrow” or “Cancel my ticket”
the app needs to understand the action that it should trigger to fulfill the user request. The NLP system, if configured correctly, can help determine this. The alternative is to perform a simplistic string pattern matching inside the app itself, but that is very fragile and very hard to maintain. Google’s Dialogflow, Amazon’s Lex, Facebook’s wit.ai, and the open-source project Rasa are some of the services that can be used for this purpose.
Translation
If the app wants to support multi-lingual input, it typically does in one of two ways. The NLP system itself can be configured for every language or the app can employ translation to get this right. If you are using translation, there are 3rd party services like Google Translate services, that do a decent job.
Text to Speech (TTS)
A Voice Assistant should ideally be a duplex system. That is, it should not just allow users to talk to the app, but also the Assistant should be able to speak back to the user at the appropriate times. One can use the platform native APIs for doing this or a 3rd party service like Amazon Polly.
Once you have identified the providers of the 4 key components, the next thing that is needed is to ensure that you can use them in a way that is suited for your app.
ASR Domain Optimization
Typically, the service can be used out of the box with no configurations as it would come with its own pre-trained models. But it may not be good enough for your app or domain. For E.g. if you are a car company app, and if your user says “corolla”, the ASR might potentially recognize it as “gorilla”, as it has no explicit context about your app. It is using a probabilistic model and based on how it recognizes the speech patterns, it might potentially pick a word that it thinks is the best globally. Some ASR engines allow you to augment the language model used by the ASR to be “biased” towards words or phrases that are more relevant to you.
NLP Intents and Slots/Entities Configurations and utterance training
As mentioned above, an NLP system needs to be configured and trained well for it to work efficiently. This normally one of the hardest things to do and requires a specialist conversational designer to configure and train it correctly.
Intents and Entities (or Slots as they are called by some) are the basic building blocks here. Intents are used to classify the actual utterances that the user speaks (is he or she trying to book a ticket or cancel it?). And the Entities (or Slots) are used to identify/extract the data/parameters/entity inside that utterance (e.g. extracting the source, destination, and travel date when the user says “book a ticket from Bangalore to Chennai for tomorrow”)
Translation Optimizations
Again this mostly would work out of the box, until it doesn’t :). The translations that the generic 3rd party services provide are optimized for the common case and might not be applicable to your needs. Here are some common examples of failures that are not optimized say for a grocery search
TTS Prompts and Statements configuration
There are fundamentally 4 reasons why Voice Assistants need to speak out.
- Speak out a greeting message (“Welcome to Big Basket”)
- Clarify something if it’s not able to understand (“Sorry I did not understand what you are saying”).
- Ask a question (“Which is the travel date?”)
- Convey some information (“Your balance is 200 Rs”)
In a typical application, there could be hundreds of such sentences that need to be spoken out by the Assistant, and these need to be configured, with the ability to be changeable dynamically at runtime.
This is usually the most involved part: How should the application react to the various Intents that are recognized and unrecognized? What happens when some entities are recognized and some are not? After one intent is recognized, how do you trigger the next user-journey? This, more often than not, is coded explicitly inside the app in most cases and leads to a lot of complex “if/else” and complex programming logic.
I am glossing over this concept, even though it’s the hardest. But this is roughly equivalent to handling various UI events in Android and Web apps, after having designed the various page layouts and rendered them on-screen, and then connecting them with the business logic which triggers the actual functionality. Just that, here, instead of UI events, you deal with intents and entities as your inputs. But unlike UI events which are definitive in nature (you can only click on things that you can see on the current screen), voice is unconstrained and the user can refer to things that are outside the scope of the current screen too.
The next big puzzle is the Visual experience that has to go along with the Assistant. Think of it like the Google Assistant or Siri like UI elements that you need to add to your app to get the feel of having a Voice Assistant. While this is slightly more straightforward than the previous points, it has a bunch of nuance to it. Since most developers are less familiar with this part of the Assistant building, I will get a bit more specific for this section.
Invocation Trigger
This is the first step of the puzzle. How will the user initiate the interaction with the Assistant? The Assistant should have a “single” point of entry (unlike traditional UI elements where different functionalities have different UI elements). This is done in one of two ways (or both in some cases) —
- A microphone button is placed strategically on the screen that users can click to start the interaction. This is again kept in one of three places —
- At the bottom of the screen, which is easier for the thumb to get to
- At the top of the screen, typically inside the nav/action bar
- Right next to the functionality that has voice-enabled, if voice enablement is very localized
- A hotword that triggers the Assistant. For E.g when using Alexa inside the Amazon app, you can start it by just speaking “Alexa”. This is a double-edged sword in my view. While it might seem quite convenient, hotwords are ideal for far-field interactions (like with an Echo device or talking to Siri or Google Assistant when the phone is kept away from you). But as we have seen with those devices, it can have a lot of false positives and also is a potential battery drain and a security loophole.
Assistant Interaction Surface
Once the Assistant has been invoked, it needs its own surface where it can interact with the user. There are two ways in which apps have implemented this —
- A full-screen “conversational screen” that overlays on top of the traditional app interface.
- A partial screen (normally at the bottom) that allows the user to interact with both the traditional app interface or with the Assistant simultaneously
User Training
When a user is interacting with the Voice Assistant, it’s quite natural for him or her to not know what exactly to say, even after they have invoked the Assistant. Because Voice is so open-ended, it puts a cognitive overhead on the user. We have all been through this. That’s why it’s important for the Assistant to be able to educate the user on what are the various things they can say that an Assistant can reliably understand. Over time, the user becomes more accustomed to the system that they wouldn’t need it, but this is important initially.
This can be done by one of two means.
- Showing contextual hints when the Assistant is active. Contextual hints give clues to the user about possible answers when the Assistant is prompting them to speak. This helps train the user about the correct way to speak back to the Assistant.
- Showing contextual coach-marks to inform the user when is a good time to use the Assistant. For Eg when the user tries to do a textual search and if Voice Search is enabled in that app, the app can inform the user that they can use the Voice Assistant to do the same immediately after the search results have been shown. This contextual help message is more useful than showing them a coachmark at the beginning and we have seen higher conversions happening because of this.
Assistant UX
A key aspect of Assistant design is setting the amount of time it should wait for the user to speak before timing out. Wait too long and it would feel like the system is too slow. Timeout quickly and you would end up missing out on the user’s thoughts. The Assistant needs to have two different timeouts —
- Initial wait timeout — This is the time the Assistant will wait for the user to begin speaking. This should be higher and in the range of at least 5 to 10 seconds.
- End of speech timeout — This should not have a fixed time but rather be dynamic. When speaking a short sentence and the user pauses, it can timeout quickly. But when the user is speaking for longer initially, it’s better to keep waiting for him to gather his or her thoughts. For Eg. if the user spoke something that is lesser than 10 characters and there was a 1-second pause, it probably means he is done. It was most likely a short answer (eg: “help” or “done” etc). But if the user spoke a bigger sentence, it might be okay to wait for a bit more (say 2-second pause).
The next challenge is making sure that the UI elements and the conversational design elements and the business logic are all well connected.
For example:
- When the trigger is shown, the surface should not be visible at the same time.
- When the user has finished speaking and the app is trying to determine the intent behind the speech, the UI should indicate it’s processing
- After the user’s intent is understood and if the screen changes, the Assistant surface should inform the user about the outcome and get out of the way for the user to be ready to interact with the app
- When the Assistant is asking the user for an input and if the same can be provided by just clicking on the UI, the Assistant should react to this multi-modal input and move to the next steps, instead of forcing the user to give input only by voice.
There are lots of nuances of connecting the visual experience and the conversational experience when building the In-App Assistant. This is what makes the experience smooth and pleasing to the user.
Next up. Platform specificity. Every platform has its own nuances, especially when it comes to getting access to the microphone and also access to the speaker.
For instance, in browsers and specifically in multi-page apps (like non-React apps), when you move from one page to another, the app cannot, without any user input, automatically speak out something. Also, the way to get the microphone permission is not very intuitive.
Similarly for Android and iOS. The app has to make sure every time that the permission for the microphone is available and, if not, prompt for it at the right time and in a very tactful way.
When a user interacts via voice, since it’s a very unique human experience (even animals can potentially use a touch interface), we intuitively have a higher level of expectation. While the most common thing that people assume here is that it should be “intelligent” enough to understand what is being spoken, what we have seen in our experience is that users understand that finally they are talking to a machine and it has some predefined constructs. As long as there is some flexibility there, most users are fine to use almost similar sounding commands.
But what they cannot tolerate is a lack of responsiveness. If you say something and if the system takes a long time to respond back or even tell you it got what you spoke, it is very off-putting. It’s equivalent to having a touch interface where you touched something on the screen and it does not even give you an indication of response. So a Voice Assistant has to be –
Responsive. It should show on the screen what the user spoke, as soon as they spoke it out, so that they feel reassured that the system got their input
Quick. And after the Assistant determines the user speech has ended, it should strive to respond back (do some UI transitions) typically within a second. This sub-second response time is what made Alexa so loved by everyone. It felt so natural when it responded back within a second. The bar is now high for users when it comes to performance.
Dynamic and contextual. The Assistant should not feel too monotonous in its interactions. When it comes to visual outputs, it’s fine if the same sequence gets played out every time and in fact, we want that. But when it comes to voice responses, humans tend to get bored if the response from the Assistant is very repetitive. So it’s important that the Assistant is dynamic. And also it should be contextual. Depending on which screen the user is interacting with the Assistant, it should change the way it drives the conversation with the user
Building a good custom In-App Assistant has typically needed a lot of investment, both in terms of the number, kind of people needed, and also the time it would take to get it right. That is why it has taken many of the brands quite a bit of time and investment to roll out their own custom Assistants.
Mobile and Web apps are the dominant channels for businesses today and they will continue to be. But if it takes a lot of effort and time for brands to embrace this technology, it’s going to be a big deterrent to many of them to embrace this technology.
But this does not have to be like this. There has to be a better way if we are to democratize this notion of Voice interfaces.
The time has now come for this technology to be made available to brands as a simple service that they can connect to and embed inside their apps. It’s time for Voice Assistants to become a service.
In our next blog, we will talk about how Slang is doing exactly that via its unique Voice Assistant as a Service (VAaaS) platform.