Recent advances in TensorFlow and reinforcement learning environments, such as those available through OpenAI Gym and the DeepMind Control Suite, have allowed for rapid prototyping, experimentation, and deployment of reinforcement learning applications across many domains.
TensorFlow-Agents, a TensorFlow-2-based reinforcement learning framework, is a high-level API for training and evaluating a multitude of reinforcement learning policies and agents. It enables fast code iteration, with good test integration and benchmarking¹.
This article illustrates the application of tf_agents to Multi-Agent Reinforcement Learning (MARL) problems. In this article, we apply tf_agents to our novel, multi-agent variant of OpenAI Gym’s CarRacing-v0 environment. Our implementation of this MultiCarRacing-v0 environment can be found here. For more information on this environment, please check out this article.
To train our agents, we will use a multi-agent variant of Proximal Policy Optimization (PPO), a popular model-free on-policy deep reinforcement learning algorithm². In this study, we will evaluate the performance of these agents in single-agent, multi-agent, and self-play (in which a single agent is trained against itself) configurations.
For this implementation of PPO, we will use a KL regularizer², as is similarly done with Trust Region Policy Optimization (TRPO)³, which limits the amount a policy is allowed to change by through a loss term that computes the KL divergence between the old (stochastic) policy and the new (stochastic) policy over the on-policy trajectory.
The pseudocode for this algorithm is given below:
Intuitively, the training algorithm proceeds according to the graphic below:
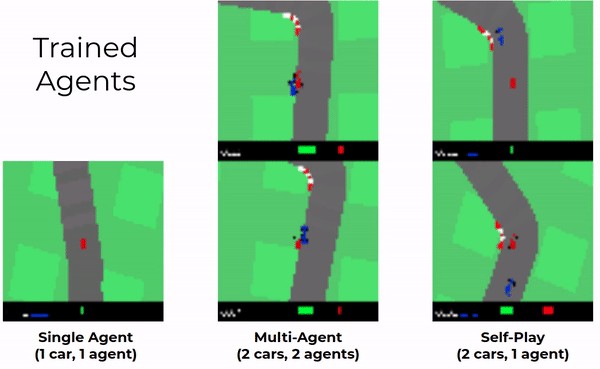
Multi-agent training configuration:
Self-play training configuration:
To train, evaluate, and visualize these agents, we used thetf_agents API. Let’s walk through some of the code together (all of the code can be found in this GitHub repository):
- Environment installation:
# Clone repo
git clone https://github.com/rmsander/marl_ppo.git
cd marl_ppo# Option A: Install requirements with pip
pip install -r requirements.txt# Option B: Install requirements with conda
conda env create -f environment.yml
2. Observation Wrapper:
Since we are working with multiple agents at a time, it is important we are able to provide agents with their appropriate observations from our gym environment. We don’t grant agents full observability of their opponents, so it is important the agents only observe their field of view in this environment.
class ObservationWrapper:
""" Class for stacking and processing frame observations."""
def __init__(self, size=(96, 96), normalize=False,
num_channels=3,num_frames=1, num_agents=2): self.size = size # Dimensions of observation frame
self.normalize = normalize # Normalize [0, 255] -> [0, 1]
self.num_channels = num_channels # 3 = RGB, 1 = greyscale
self.num_frames = num_frames # Number of frames in obs
if self.num_frames > 1: # Frame stacking
self.frames = [tf.zeros(self.size+(self.num_channels,))
for i in range(self.num_frames)] def get_obs_and_step(self, frame):
""" Processes the observations from the environment.""" processed_frame = self._process_image(tf.squeeze(frame)
if self.num_frames == 1: # Single-frame observations
return processed_frame else: # Frame stacking
concat = [processed_frame] + self.frames[:-1]
self.frames = concat # Update frames
stacked_frames = tf.concat(tuple(concat), axis=-1)
return stacked_frames def _process_image(self, image):
""" Process each individual observation image."""
if self.num_channels == 1: # grayscale
image = tf.image.rgb_to_grayscale(image) elif self.num_channels == 3: # rgb
if len(tf.shape(tf.squeeze(image)).numpy()) < 3:
image = tf.repeat(tf.expand_dims(image, axis=-1),
self.num_channels, axis=-1) input_size = tuple(tf.shape(image)[:2].numpy())
if input_size != self.size:
kwargs = dict(
output_shape=self.size, mode='edge', order=1,
preserve_range=True) # Resize the image according to the size parameter
image = tf.convert_to_tensor(
resize(image, **kwargs).astype(np.float32))
if self.normalize and np.max(image) > 1.0:
image = tf.divide(image, 255.0) return image def reset(self):
""" Method for resetting the observed frames."""
if self.num_frames > 1:
self.frames = [tf.zeros(self.size+(self.num_channels,))
for i in range(self.num_frames)]
3. Trainer Class
A customized trainer class is used to instantiate, create, and train agent(s) in the multi-agent environment. For brevity, the trainer class in full detail can be found here.
To run the trainer, please first edit the parameters in ppo/parameters.py. Then, once ready, run:
python3 ppo/ppo_marl.py
4. MultiCarRacing-v0 environment
Basic usage is provided below — for more information on this environment, please check out my article here.
After installation, the environment can be tried out by running:
python3 envs/multi_car_racing.py
This will launch a two-player variant (each player in its own window) that can be controlled via the keyboard (player 1 via arrow keys and player 2 via W, A, S, D).
Let’s quickly walk through how this environment can be used in your code:
import gym
import gym_multi_car_racingenv = gym.make("MultiCarRacing-v0", num_agents=2, direction='CCW',
use_random_direction=True, backwards_flag=True,
h_ratio=0.25, use_ego_color=False)obs = env.reset()
done = False
total_reward = 0while not done:
# The actions have to be of the format (num_agents,3)
# The action format for each car is as in the CarRacing env.
action = my_policy(obs)# Similarly, the structure of this is the same as in CarRacing-v0
# with an additional dimension for the different agents, i.e. # 1. obs is of shape (num_agents, 96, 96, 3)
# 2. reward is of shape (num_agents,)
# 3. done is a bool and
# 4. info is not used (an empty dict).
obs, reward, done, info = env.step(action)
total_reward += reward
env.render()
print("individual scores:", total_reward)
Video of trained agents racing against one another in our augmented MultiCarRacing environment can be found below:
Because PPO trains on a stochastic exploration policy and is evaluated on a greedy deterministic policy, there is an inherent domain shift in the speed of the vehicle between training and test time. This results in the evaluation policies having lower performance than the training policies. This remains an interesting open question from this study.
Training results from the training procedures above:
To compare the performance of these agents against one another, we also ran an Elo Rating tournament to determine the best competitive racing policy. Results from this tournament (run on one seed) can be found below (higher Elo Rating indicates higher performance):
In this article, we explored the application of TensorFlow-Agents to Multi-Agent Reinforcement Learning tasks, namely for the MultiCarRacing-v0 environment. You can find my GitHub repository for this environment here.
If you find these results or the multi-agent tutorial setup with tf_agents useful, please consider citing my paper:
@unknown{unknown,
author = {Sander, Ryan},
year = {2020},
month = {05},
pages = {},
title = {Emergent Autonomous Racing Via Multi-Agent Proximal Policy Optimization}
}
If you find the MultiCarRacing-v0 environment useful, please cite our CoRL 2020 paper:
@inproceedings{SSG2020,
title={Deep Latent Competition: Learning to Race Using Visual
Control Policies in Latent Space},
author={Wilko Schwarting and Tim Seyde and Igor Gilitschenski
and Lucas Liebenwein and Ryan Sander and Sertac Karaman and Daniela Rus},
booktitle={Conference on Robot Learning},
year={2020}
}
¹ Oscar Ramirez Pablo Castro Ethan Holly Sam Fishman Ke Wang Ekaterina Gonina Neal Wu EfiKokiopoulou Luciano Sbaiz Jamie Smith G ́abor Bart ́ok Jesse Berent Chris Harris Vincent Van-houcke Eugene Brevdo Sergio Guadarrama, Anoop Korattikara. Tf-agents: A library for rein-forcement learning in tensorflow.https://github.com/tensorflow/agents, 2018.URLhttps://github.com/tensorflow/agents. [Online; accessed 25-June-2019].
² John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policyoptimization algorithms.arXiv preprint arXiv:1707.06347, 2017.
³ Schulman, John, et al. “Trust region policy optimization.” International conference on machine learning. 2015.