Key words: Python, Web Scraping, API, BeautifulSoup, Clustering, BOI, WordCloud
Note: Detailed coding of this subject can be found on my GitHub account — Click Here!
Starting a new business is a big decision to make as it requires in-depth planning and execution. This project attempts to map out, segment and explore the neighborhoods in the city of Calgary, AB Canada. The goal will be to help entrepreneurs and prospective business owners in this city decide optimum locations to start a new business. Several factors will govern location selection such as the type of business, target customer base, population density and proximity to public transit, to name a few.
Several data sets and tools will be exploited to tackle the subject. To start off, a comprehensive list [1] showing the breakdown of the neighborhoods, their physical size and population across Calgary will be scraped and structured into a pandas data frame. Next, geospatial information (latitude and longitude) will be extracted using geocoder package in Python for each neighborhood. Foursquare location data will be the main API server leveraged to explore the different venues and types of businesses that currently exist in those neighborhoods. Several data science skills will be utilized in this project, such as data wrangling, exploratory data analysis and use of Machine Learning, namely K-Means Clustering algorithm to cluster and analyze the neighborhoods and help in selecting the best location for a business start-up.
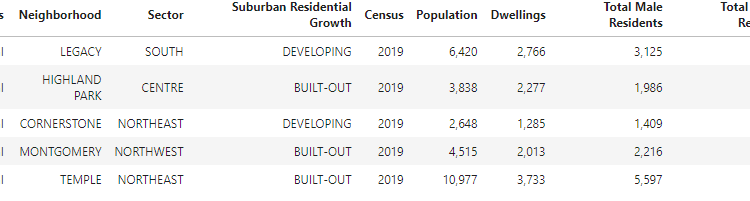
The raw data provides a comprehensive data set on each of the communities (which will be referred to as neighborhoods from this point on) in Calgary. For the intents and purposes of this study, we will select the most significant features from this data set that will help answer our question, as displayed in the snapshot in Table 1. Definition of each of these features is also provided. The data shows that Calgary has a total of 306 neighborhoods.
Table 1: 2019 Census Data (Source: City of Calgary’s Open Portal)
- Class — Indicates the category of the neighborhood, which are Residential, Industrial, Residual Sub Areas and Recreational Parks.
- Neighborhood — Indicates name of the community.
- Sector — Indicates the high-level geographical location of the neighborhood (This will become especially important later in the analysis).
- Suburban Residential Growth — Reflects the yearly development capacity or housing supply, categorized as Built-Out (i.e. Fully Developed neighborhoods), Developing (neighborhoods still under development) and non-residential.
- Census — Indicates the year the data was collected.
- Population — Indicates the total population per neighborhood.
- Dwellings — Refers to the number of living quarters in which a person/family resides [2].
- Total Male Residents — Shows the total number of male residents per neighborhood.
- Total Female Residents — Shows the total number of female residents per neighborhood.
The next step was to extract the geospatial coordinates (latitude/longitude) for each neighborhood. This was done using the geocoder API location library package. It is worth noting that this package has a limited number of daily API requests that a user can make to call for data. Therefore, it is wise to mine the data set once and save it to a CSV file to be casted into a pandas data frame for convenience. A snapshot of the resulting data frame is displayed in Table 2 below.
Table 2: Geospatial Information for each Neighborhood in Calgary
Table 2 was then integrated into Table 1 to produce one comprehensive data set showing all desired features required for the study. Data wrangling was applied to clean, manipulate and transform the data to a format that can be properly handled in Python’s machine learning library (sci-kit learn). A snapshot of the processed, clean data set ready for analysis is tabulated in Table 3 below. Our final sorted data set has been reduced from 306 total neighborhoods to 199 effectively populated neighborhoods valid for analysis. The next step is to create a map using folium library to display the neighborhoods’ distribution in the city of Calgary, shown in Figure 1 below.
Table 3: Final Sorted Feature Set
Figure 1: Total Neighborhoods’ Distribution in the city of Calgary
Now that we have successfully mapped out the neighborhoods. Let’s split the data based on the “Suburban Residential Growth” feature (or yearly development capacity), to gain insight into the split of fully developed and currently developing neighborhoods in the city. Similarly, folium maps showing the 31 developing and 168 built-out (or fully developed) neighborhoods were generated as illustrated in Figure 2 and Figure 3, respectively.
Figure 2: Developing Neighborhoods’ Distribution in the city of Calgary
Figure 3: Built-out Neighborhoods’ Distribution in the city of Calgary
There is a total of 31 developing neighborhoods, with potential of growth and 168 fully developed neighborhoods in Calgary as of Dec 2019. As an entrepreneur, it is intuitive to launch your new business, say a restaurant, supermarket or cafe, in a developing neighborhood since there is potential room for growth as more people move into those communities. To add, it will also be less capital-intensive since property developers will be in need of new business owners to establish the commercial footprint in such neighborhoods. This will lead to providing incentives that are otherwise non-existent in saturated neighborhoods.
Now that we decided to focus on the developing neighborhoods, it is important to mention that they are mainly clustered in the north, west and south sectors, away from the city center. Therefore, the following steps will be taken into account to strategically select the optimum neighborhood to establish a business in:
- Segment the “Developing” neighborhoods data frame into sectors (West, North, North-East, North-West, South and South-East).
- Leverage Foursquare API location data to fetch the top 100 venues in each neighborhood within a 1 KM radius.
- Identify the total number of unique venues in each sector.
- Compute the “Business Opportunity Index (BOI)”, which is the population-to-venues ratio, for each neighborhood in each sector. This new parameter will assist in effectively distinguishing neighborhoods with high population density but low number of facilities and services. Such communities will be the primary targets for prospective business owners.
- Select sector(s) with highest BOI and lowest number of unique venues.
- Apply K-Means clustering ML algorithm to segment the neighborhoods in the chosen sector and to highlight the top 10 venues in each cluster in order to finalize selection of the optimal neighborhood to start a business in.
- Selected neighborhood will also need to have easy access to public transit and available parking spaces to attract as many customers as possible.
The Business Opportunity Index (BOI) was calculated to identify neighborhoods of interest in each sector. Figure 4 shows a graphical representation of the results in the form of bar charts.
Figure 4: Business Opportunity Index (BOI) for each Developing Neighborhood in Calgary
· West Calgary’s Developing Neighborhoods have 35 unique venues
· North Calgary’s Developing Neighborhoods have 56 unique venues
· North-East Calgary’s Developing Neighborhoods have 22 unique venues
· North-West Calgary’s Developing Neighborhoods have 4 unique venues
· South Calgary’s Developing Neighborhoods have 18 unique venues
· South-East Calgary’s Developing Neighborhoods have 50 unique venues
Bar charts reveal that the Southern part (South + South-East) of the city have the highest BOI within the range of 3000–4000 people-to-venue ratio in communities such as Auburn Bay (South-East — BOI = 4000+), Evergreen (South — BOI = 4000+) and Legacy (South — BO = 3000).
In the North, Evanston neighborhood came in second with BOI score = 3000, while other neighborhoods ranged up to 2000 taking into account the North-East and North-West sectors.
Developing neighborhoods in the West came in last place of the priority table, with its highest scoring community (Springbank Hill) having a BOI = 2000.
Another interesting statistic to report is that collectively, the Northern sectors of the city have 20% more venues compared to their Southern counterparts. In particular, South Calgary has the lowest number of 18 unique venues compared to the rest of the sectors (excluding the North-West, which only has one developing neighborhood).
Looking at this data, we will focus on South Calgary and carry it forward to the clustering stage using k-means algorithm since it represents the highest growth opportunity.
K-Means Clustering Algorithm
At this point, it is useful to provide some background information on K-Means clustering algorithm to better understand how it segments the data [3].
It is a partitioning-type of clustering method, where it divides the data into non-overlapping subsets (or clusters) without any cluster-internal structure.
· Examples within a cluster are very similar
· Examples across different clusters are very different
The algorithm works as follows:
1) Initialize K (number of centroids for each cluster) randomly (e.g. 3 Clusters).
2) Calculate the euclidean distance of all data points to the random centroids.
3) Assign each point to the closest centroid, calculate the Residual Sum of Squares (RSS) between each point and its centroid.
4) Compute new centroids for each cluster. The new location of centroids will be the new mean of data points in its cluster.
5) Re-calculate euclidean distance of all data points to the new centroids.
6) Repeat steps 1–5 until centroids no longer move (i.e. when the least RSS or most dense clusters are obtained).
It is vastly used in Data Science applications, especially useful to quickly discover insights from unlabelled data.
Some real-world applications of K-Means Clustering include:
· Customer Segmentation
· Pattern Recognition
· Understand what visitors of a website are trying to accomplish
· Machine Learning
· Data Compression
Before we proceed to clustering, let’s check the optimum number of clusters (K) for our problem. A plot of Residual Sum of Squares (RSS) vs. Number of Clusters (K) is presented in Figure 5.
Figure 5: Residual Sum of Squares (RSS) vs. Number of Clusters (K)
The Residual Sum of Squares (RSS) continues to decrease with increasing number of clusters. However, it does not significantly drop after k = 3. Therefore, we will segment our neighborhoods into 3 main clusters.
Figure 6: Clusters in South Calgary generated by K-Means Clustering Algorithm
Examine Clusters
Now, each cluster will be examined to determine the discriminating venue categories that distinguish each cluster. This will be done using wordcloud library. Word clouds (also known as text clouds or tag clouds) work in a simple way: the more a specific word appears in a source of textual data (such as a speech, blog post, or database), the bigger and bolder it appears in the word cloud. This Python package was developed by Andreas Mueller. You can learn more about the package by following this link.
Figure 7: Word Cloud (Cluster 1)
Figure 8: Word Cloud (Cluster 2)
Figure 9: Word Cloud (Cluster 3)
The comprehensive analysis demonstrated that, in general, the South sector of Calgary offers tremendous opportunities for future entrepreneurs to start their business. Based on the factors listed in the Methodology section, calculated BOI and clusters generated, Evergreen in Cluster 2 (BOI Score = 4300 people-to-venue ratio) and Legacy in Cluster 3 (BOI Score = 3210 people-to-venue ratio) stand out as the most potential neighborhoods to be targeted by aspiring Business owners.
In addition, both neighborhoods have easy access to public transit and contain free parking space, deeming them favorable to attract as many visitors as possible. One down-side is long commuting time for people who live in city center or other sectors in the city. With that said, such drawback is evident in every major city in the world.
The two neighborhoods selected offer unlimited possibilities for the types of businesses to be considered that can cater for diverse types of customer base. Table 4 and Table 5 below shed some light on some suggestions.
** 50% of neighborhood residents is Female
Table 4: Recommended Business Types in Evergreen
** 50% of neighborhood residents is Female
Table 5: Recommended Business Types in Legacy
This study provided a lot of insight into what Calgary, AB has to offer to Investors and Entrepreneurs. There is a total of 199 effectively populated neighborhoods, classified into 31 developing and 168 built-out communities as of the latest Census data collected by the City of Calgary council in Dec 2019. The focus was on developing communities as they have better potential to grow in the future and thus are prime targets for Business owners.
Moreover, it will also be less capital-intensive since property developers will be in need of new business owners to establish the commercial footprint in such neighborhoods. This will lead to providing incentives that are otherwise non-existent in saturated neighborhoods.
Statistical analysis identified South Calgary as the most favorable target, since it ranked first in terms of the calculated Business Opportunity Index (BOI) and contains the least number of only 18 unique venues (excluding the NW region which only has one neighborhood).
From the neighborhoods in the South, Evergreen and Legacy contained within Clusters 2 and 3, respectively showed the most potential. A list of possible business types was also identified in the Results and Discussion section of this study.
The model used in this study is highly flexible. It can be used to investigate other neighborhoods located in different sectors based on their calculated BOI. Therefore, it can serve all types of potential business owners and city officials to help them pin-point opportunities for economic growth and prosperity.
Latest updates on development projects in both neighborhoods can be found in sources [4] and [5] in the References section.
· Optimum location to open a Daycare Center (Data about number of children per house-hold in each neighborhood is available)
· Optimum location to open a Pet Store (Data about number of pets per house-hold in each neighborhood is available)
· Optimum location to open a Senior Home (Data about Residents’ age demographics in each neighborhood is available)
[1] — City of Calgary’s Open Data Portal
[2] — Statistics Canada
[3] — IBM Coursera — K-Means Clustering Video
[4] — Evergreen.ca
[5] — Legacylife.ca
Thank you for completing this article!