Content provided by Zhuoran Shen, co-author of the paper Fast Video Object Segmentation using the Global Context Module.
We developed a real-time, high-quality semi-supervised video object segmentation algorithm. Its accuracy is on par with the most accurate, time-consuming online-learning model, while its speed is similar to the fastest template-matching method with sub-optimal accuracy. The core component of the model is a novel global context module that effectively summarizes and propagates information through the entire video. Compared to previous approaches that only use one frame or a few frames to guide the segmentation of the current frame, the global context module uses all past frames. Unlike the previous state-of-the-art space-time memory network that caches a memory at each spatio-temporal position, the global context module uses a fixed-size feature representation. Therefore, it uses constant memory regardless of the video length and costs substantially less memory and computation. With the novel module, our model achieves top performance on standard benchmarks at a real-time speed.
What’s New: A novel module that effectively and efficiently propagates information through an arbitrarily long video, with constant complexity w.r.t. number of frames and linear complexity w.r.t. resolution.
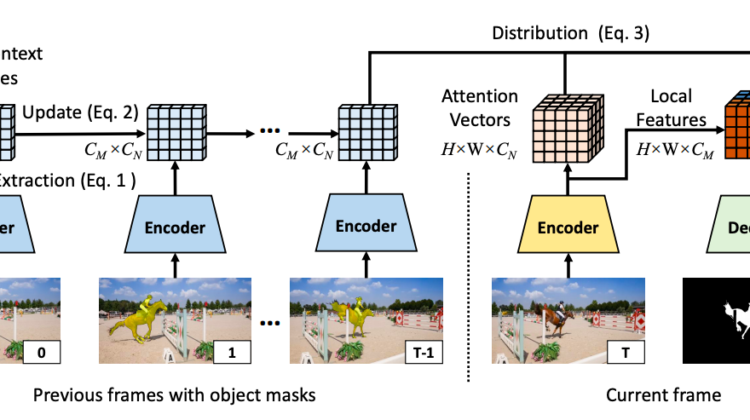
Traditionally, semi-supervised video object segmentation models make trade-offs between which past frames to use to guide the processing of an incoming frame. Recent methods eliminated the trade-off by using the attention mechanism to utilize all past frames as guidance. However, using attention on all frames incurs rapidly increasing costs as the video gets longer. This work proposes the novel global context (GC) module which builds a compact, fixed-size global context representation for all past frames. It enables the model to take all past frames as guidance at a constant complexity with respect to the video length. This module serves as the central component that enables a novel video object segmentation algorithm, which is the first to achieve state-of-the-art accuracy and a real-time processing speed at the same time. In addition, the GC module generalizes as a generic-purpose efficient attention mechanism for any video task for temporal alignment or context modeling.
How It Works: The global context (GC) module maintains a compact, fixed-size global context representation for all frames in a video or a subsequence of a video. For an incoming frame, it first creates a pair of feature maps, the keys and the values, from the output features of the final layer or an intermediate layer of the encoder. Then, it performs global summarization, which converts the keys and values into a fixed-size frame context representation. The final step is a simple averaging of the frame contexts for all frames to generate the global context. Despite its simplicity, the paper presents a proof that this mechanism is mathematically equivalent to the significantly more costly dot-product attention mechanism, which is present in the prior state-of-the-art space-time memory (STM) networks and many other works on video understanding.
Key Insights: The popular memory modules, which are highly beneficial to tasks including video object segmentation, can be substantially optimized in terms of speed and memory cost.
The global context module uses an efficient formulation of attention. Attention and its efficient variants have been taking off in computer vision. I reasonably expect that attention-based models will have a similar degree of success in vision in the near future as it has in NLP right now.
The paper Fast Video Object Segmentation using the Global Context Module is on arXiv.