Kaggle was the first data science platform that I joined when I began studying data science. The site has micro-courses to help people learn the basics while embarking on their machine learning journey. At some point, after taking courses and doing tutorials, people wanting to break into the field will need to begin working on projects. Some data scientists decide to enter competitions to help them to hone their skills, and Kaggle has many competitions that are well suited for this purpose.
What I have found with Kaggle, however, is that people for the most part are required to learn the basics of data science on their own and then they can look at entering competitions. The Titanic competition is the first competition that people are asked to enter because it is considered the easiest one. There are other competitions on the Kaggle site that a person can enter that, once a person has learned the basics of data science, are just as easy to complete as the Titanic competition. One such competition is the Recognize the Digits competition.
I have therefore decided to go through the solution to this competition question to show that it is not as scary as one might imagine. This program has been written in Kaggle’s Jupyter Notebook, which is entirely free for people who have signed up to the site to use. It has many libraries already installed on it, so there is no need to install or update them.
The first thing to do when entering the Recognize the Digits competition is to open a Jupyter Notebook on the page.
After I opened my Jupyter Notebook, the first step was to import the libraries that I would need to carry out mathematical and dataframe functions, being numpy and pandas:-
The next step was to read the csv files that are stored in Kaggle’s directory of this competition:-
Once the files had been read, I checked to see what kind of data was in the train and test files, and found all of the columns are numeric, so it was not necessary to carry out any encoding.
I checked for any null values. Fortunately in this instance there were no null values that needed to be imputed.
I created a variable, ImageId, by adding 1 to test.index. The reason for this is because Python’s first number starts with 0 but the ImageId starts with the number 1.
I then defined the X, y and X_test variables, which would be used to make predictions on the test file.
The y variable, being the target, is the first column of the train dataset (in Python the numbers begin with 0).
The independent variable, being X, is composed of all of the columns after the first one in the dataset.
X_test, which is the variable that would be predicted on, is composed of the entire test dataset:-
Once the X, y and X_test variables had been identified, I scaled the X and X_test data by dividing them by 255. The number 255 has been used because the original values in the datasets consist of RGB (being the three hues of light used to mix together to create different colours) coefficients in the range of 0 to 255. The data needs to be scaled to the value of the 0 to 1 range in order to adequately make predictions on it:-
Once the data had been scaled to the range of ) to 1, I split the X variable up into train training and validation datasets using sklearn’s train_test_split() function:-
I then defined the model and used sklearn’s neural network, MLPClassifier() and cored an accuracy 0f 100% using this methodology.
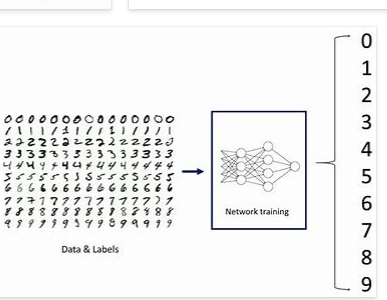
Neural networks are used to solve a lot of challenging artificial intelligence problems. They often outperform traditional machine learning models because they have the advantages of non-linearity, variable interactions, and customizability:-
I then predicted on the validation set and scored 96.74% accuracy:-
Once the validation set had been successfully predicted on, I made predictions on the test dataset:-
I then prepared the predictions for submission by creating a dataframe with the ImageId and prediction. This dataframe was then converted to a csv file, which would be used to submit the prediction:-
When I submitted my predictions to Kaggle, I had achieved a score of 96.68%, which is not bad for a first try!
The entire code for this post can be found on my personal Kaggle account, the link found here:- NMIST sklearn | Kaggle
The link for the YouTube video I made for this post can be found here:- Kaggle’s Digit Recognizer competition from beginning to end — YouTube