An Autnomous car is a vehicle capable of sensing its environment and operating without human invorcement.
Now, how does this happen.
The answer lies in the explanation below.
Firstly, let’s have a short intro of “Semantic image segmentation”..
Semantic image segmentation
Semantic image segmentation is the process of mapping and classifying the natural world for many critical applications such as autonomous driving, robotic navigation, localization and scene understanding.
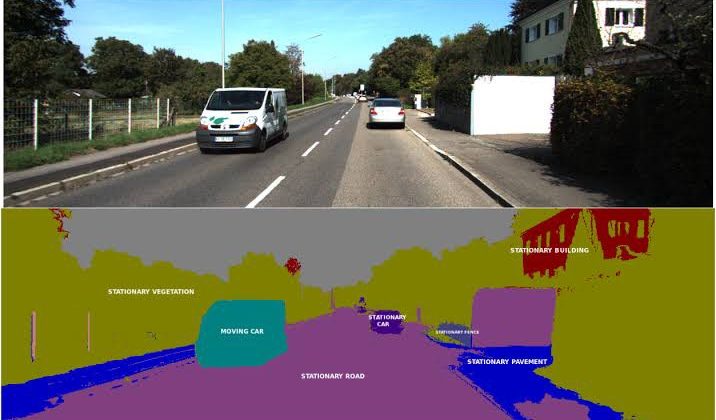
Semantic segmentation is nothing but a pixel level labeling for image classification, it is an important technique for the scene understanding. Each pixel is labeled as belonging to a given semantic class.
Let us understand with an example, a typical urban scene can be consists of classes such as street lamp, traffic light, car, pedestrian, barrier and side walk.
Semantic image segmentation and Fully convolutional network
Except where it is in the image, there are many situation that need to be learned. For eg, one should know the locations of the objects around autonomous vehicles so that we can move without hiding anywhere.
The process of detecting the locations of the objects in the image can be realized by detecting or Segmenting.
We can now easily understand that image segmentation is nothing but the operation of separating images into specific groups that show similarity and labeling each pixel in an image as belonging to a given semantic class.
In order for the image segmet process to be considered successful, it is expected that the objects are independent of the other components in the image, as well as the creating of regions with the same texture and color characteristics.
As shown in fig below, each pixel in a group corresponds to the object class as a whole. These classes may represent an urban scene that is important for autonomous vehicles; traffic signs, card, pedestrians, street lamps or sidewalks.
Why semantic segmentation is considered for autonomous vehicles?
If we consider other classification model such as AlexNet are trained with a data set consisting of more than one million imaged of only one object in the image cannot be obtained with the classification networks. The situation can be understood when they are thought to have never been trained for this aim.
The semantic image segmentation eliminates some of these deficiencies. Instead of estimating a single probability distribution for an entire image, the image is divided into several blocks and each block is assigned its own probability distribution.
How semantic segmentation work?
Very commonly, images are divided into pixel-levels and each pixel is classified. For each pixel in the image, the network is trained to predict which class the pixels belongs to. This allows the network not only to identify several object classes in the image but also to determine the location of the objects.
The datasets used for semantic image segmentation are images that are to be segmented and usually consist of label images of the same size as these images. The label image shows the ground truth limits in the image. The shapes in the label images are coded with colors to represent the class of each object.