Implementing the popular classification algorithms in Golang from scratch
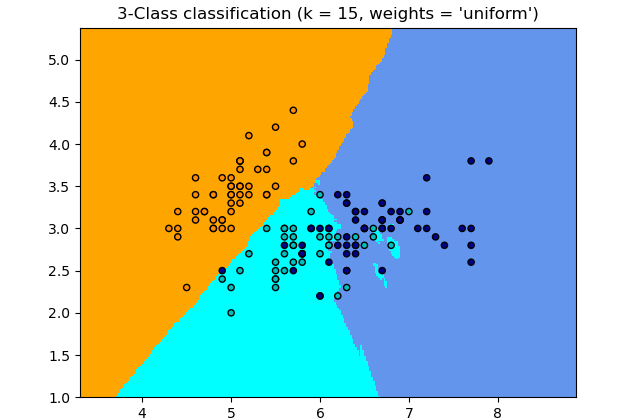
KNN stands for k-nearest neighbor and is an algorithm based on a simple idea and can be used for both classification and regression. The boundary becomes smoother with increasing value of k. With k increasing to infinity it finally becomes all blue or all red depending on the total majority.
KNN works by iterating through the data and calculating the Euclidean distance and for the k nearest neighbor of the given point, the point falls into one of several categories.
Okay, now that you’re familiar with how the KNN algorithm works in theory, let’s dig into the code.
I have based my code on a previous plotting library I created which will make it easy to implement and plot. The basic interface is a point with three variables, the x and y coordinates and the boolean, which represents the category.
DefineRandomPoints function is from the plot package and return a 100 random points between 0 and 10. Pretty straightforward, right?
he Euclidean distance between two points in Euclidean space is the length of a line segment between the two points. It can be calculated from the Cartesian coordinates of the points using the Pythagorean theorem, therefore occasionally being called the Pythagorean distance.
The Euclidean distance is calculated as the square root of sums of differences between each dimension.
My KNN implementation works like this:
- From a given point p calculate the TopKEuclideans, meaning you calculate the points that are closest to the point p but do not exceed the length of k.
- The KNN puts it all together by assigning the points based on their boolean to the appropriate cluster.
Let’s plot the following clusters to see the results.
Unlike the KNN algorithm, K-Means chooses a different approach to get the classification right. At the beginning you choose the number of clusters you want your data to be represented in.
{kind=link}
Note: in KNN you choose the k nearest neighbor value, here you choose the number of clusters.
K-Means is an iterative algorithm and therefore I though it’d be appropriate to use recursion.
The implementation follows a rather simple two-step trick.
- the algorithm goes through each of the data points and depending on which cluster is closer, It assigns the data points to one of the three cluster centroids.
- move the centroid by the average of each cluster
For the sake of understanding, the category holds the category to which each data point belongs to. Keep in mind that we used a binary KNN with a simple boolean before. Objects holds all the categories along with their IDs so that it’s easier for implementation. The cluster is as always a set of points, loss will come in handy when calculating the average distance from the centroid.
And the infamous K-means:
First step is encapsulated in the for loops that assign each data point to the right cluster and the second one is as simple as moving the centroid.
A recursive call assures the algorithm’s performance.
Both of these algorithms are simple at its core, but nonetheless provide great performance on classification tasks. Being able to implement them in my favourite language instead of calling scikit-learn reassures me with confidence that Go is just as capable of running machine learning algorithms on its own.
Feel free to find me on Linkedin, GitHub or Gmail.
Happy codding !!! 🙂
Further references: