“In classic terms, machine learning is a type of artificial intelligence that enables self-learning from data and then applies that learning without the need for human intervention. In actuality, there are many different types of machine learning, as well as many strategies of how to best employ them.”
– Fran Fernandez, head of product at Espressive
“At its heart, machine learning is the task of making computers more intelligent without explicitly teaching them how to behave. It does so by identifying patterns in data — especially useful for diverse, high dimensional data such as images and patient health records.”
–Bill Brock, VP of engineering at Very
“Broadly, ML is a subset of computer science which involves applying statistics over observed data to generate some process that can achieve some task. This encompasses both the structure of ML (taking data and learning from it using statistics) and the impact of ML (use cases like facial recognition and recommender systems).”
–Michael McCourt, research scientist at SigOpt
Here’s why machine learning is the next big thing
Throughout the world, there is researchers and machine learning enthusiasts who are using their creativity and technology to make this world a better place. Today, power grids, logistics, companies and more aspects of people welfare sectors have started using data to make smarter autonomous decisions. There are apps and algorithms in the Internet of Things that connect to your power supply and give you real-time information on the amount of energy you have consumed and compare it with that of your neighbours’. The system also gives you an idea of the equipment consuming more electricity so that you can decide and restrict their energy consumption. Starting from a smaller scale, these ideas influence the biggies like smart power grids, supply-chain systems, automated machines that can sense probable malfunctions and more.
A broad understanding of ML will probably improve your odds of AI success — while also keeping expectations reasonable.
You can start reading about machine learning from basics with an clear understanding: https://machinelearningmastery.com/start-here/
Use of Statistics in Machine Learning
Let’s understand this. Suppose, I need to separate the mails in my inbox into two categories: ‘spam’ and ‘important’. For identifying the spam mails, I can use a machine learning algorithm known as Naïve Bayes which will check the frequency of the past spam mails to identify the new email as spam. Naïve Bayes uses the statistical technique Baye’s theorem( commonly known as conditional probability). Hence, we can say machine learning algorithms uses statistical concepts to execute machine learning.
Additional Information: The main difference between machine learning and statistical models come from the schools where they originated. While machine learning originated from the department of computer science and statistical modelling came down from department of mathematics. Also any statistical modelling assumes a number of distributions while machine learning algorithms are generally agnostic of the distribution of all attributes.
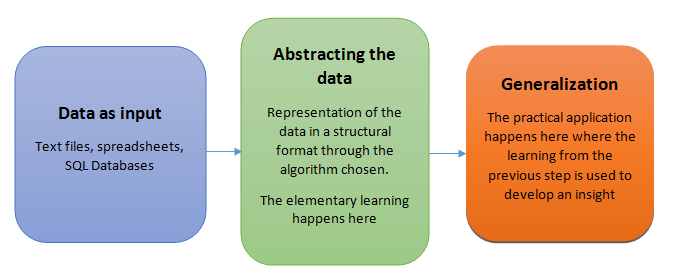
Teaching the machines involve a structural process where every stage builds a better version of the machine. For simplification purpose, the process of teaching machines can broken down into 3 parts:
I shall be covering each of these 3 steps in detail in my subsequent write-ups. As of now, you should understand, these 3 steps ensures the holistic learning of the machine to perform the given task with equal importance. Success of machine depends on two factors:
1. How well the generalization of abstraction data take place.
2. How well the machine is able to put it’s learning into practical usage for predicting the future course of action.
There are 5 basic steps used to perform a machine learning task:
- Collecting data: Be it the raw data from excel, access, text files etc., this step (gathering past data) forms the foundation of the future learning. The better the variety, density and volume of relevant data, better the learning prospects for the machine becomes.
- Preparing the data: Any analytical process thrives on the quality of the data used. One needs to spend time determining the quality of data and then taking steps for fixing issues such as missing data and treatment of outliers. Exploratory analysis is perhaps one method to study the nuances of the data in details thereby burgeoning the nutritional content of the data.
- Training a model: This step involves choosing the appropriate algorithm and representation of data in the form of the model. The cleaned data is split into two parts — train and test (proportion depending on the prerequisites); the first part (training data) is used for developing the model. The second part (test data), is used as a reference.
- Evaluating the model: To test the accuracy, the second part of the data (holdout / test data) is used. This step determines the precision in the choice of the algorithm based on the outcome. A better test to check accuracy of model is to see its performance on data which was not used at all during model build.
- Improving the performance: This step might involve choosing a different model altogether or introducing more variables to augment the efficiency. That’s why significant amount of time needs to be spent in data collection and preparation.
Be it any model, these 5 steps can be used to structure the technique and when we discuss the algorithms, you shall then find how these five steps appear in every model!
Here in this Blog we got an basic idea about Machine Learning and for more blogs subscribe to my Blog channel for more updates on Topics of computer Science