
#2. Basic Exploration And Preprocessing
Before moving on to visualizing, it is common to take a high-level overview of the dataset. In a small sub-section, get to know your data by using common pandas functions such as head, describe, info, etc.
In this way, you can identify basic cleaning issues that violate data constraints like data type, uniqueness, and range.
What I recommend is to first highlight all the issues and deal with them separately. Data cleaning is stressful and boring, so finding an issue and immediately diving into solving it makes the process even worse.
Try to find all the issues with a clear state of mind without worrying about how to fix them.
I like recording all issues in a single cell like this:

This allows me to cross off each issue as I fix them. While fixing each one, I usually follow this pattern:
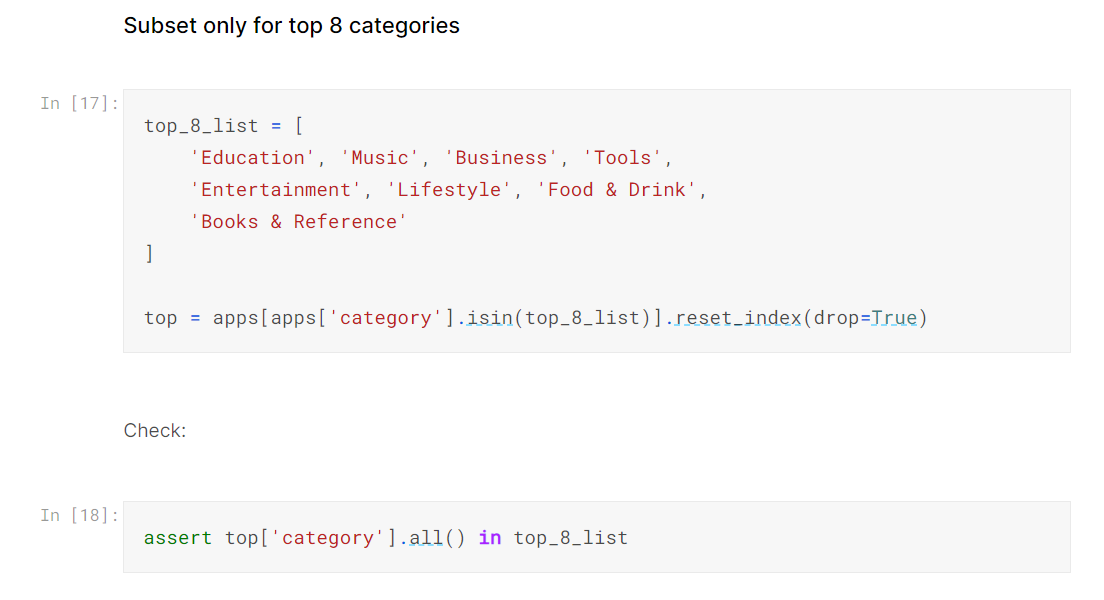
I declare the issue with a heading and fix it in a single cell. To check for mistakes, I use assert statements that return no output if the check is successful. Otherwise, it throws an AssertionError.
For massive datasets, even the smallest of operations can take a long time. When you think something is taking much longer than expected, it is likely you are doing it the slow way. Try searching for faster methods of what you are doing.
In the example notebook I prepared for this article, I noticed that pd.to_datetime was taking almost 2 minutes for a million rows just to convert a single column to datetime. I searched this on StackOverflow and found out that providing a format string to the function significantly reduces the execution time:
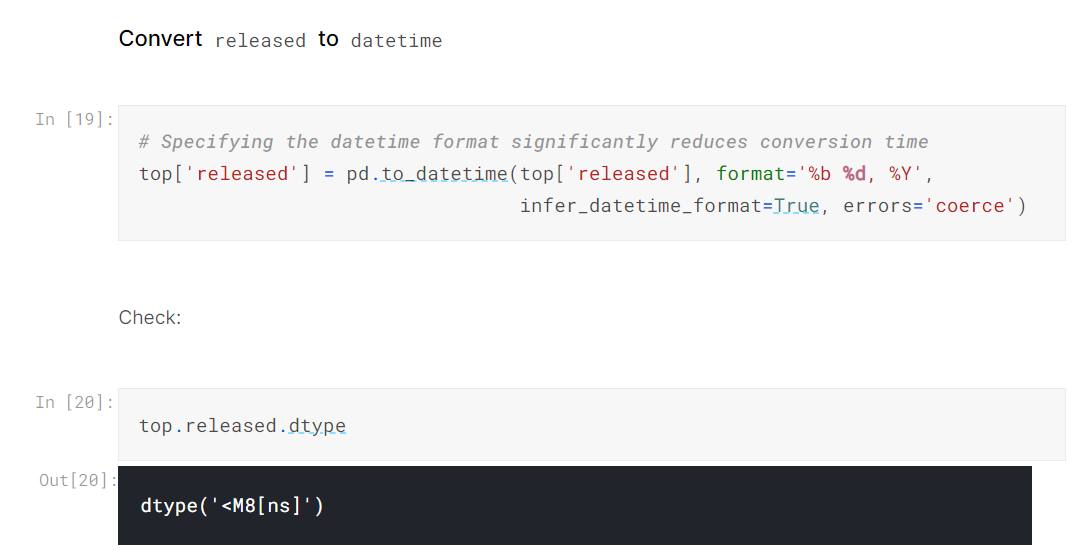
The solution took a few seconds for a million-row dataset compared to a couple of minutes.
I am sure there are many such speed tricks for cleaning, so make sure your search for them.