En, el artículo anterior (NER, Métodos supervisados I: cadenas de Markov y máxima entropía) se abarcaron los métodos de máxima entropía y cadenas ocultas de Markov, se explicó el mecanismo de funcionamiento de ambos métodos así como ejemplos de utilización. Como continuación, el presente artículo se va a enfocar en los modelos de máquina de soporte vectorial (SVM) y campos aleatorios condicionales (CRF).
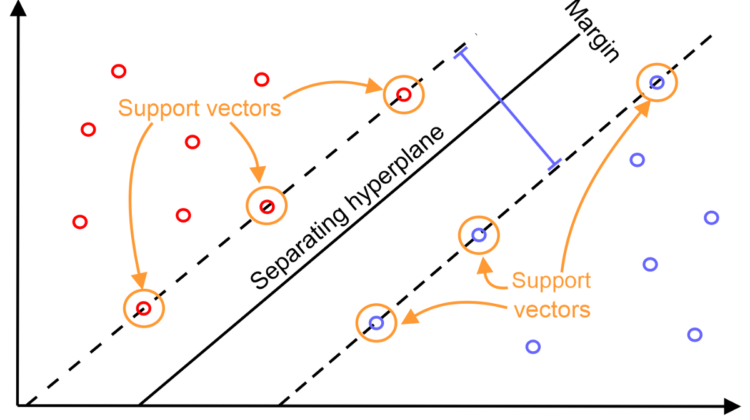
Introducido por primera vez por Cortes y Vapnik (1995), se basa en la idea de aprender un hiperplano lineal que separa ejemplos positivos de aquellos ejemplos negativos por un margen largo. Tal margen sugiere que la distancia entre el hiperplano y el punto desde cualquiera de las instancias es máxima. Los puntos que se encuentran cerca del hiperplano en ambos lados son conocidos como vectores de soporte.
La máquina de soporte vectorial es bien conocida por su gran desempeño al momento de generalizar y ha sido aplicada a muchos problemas de reconocimiento de patrones. En el campo del procesamiento de lenguaje natural, el modelo de máquina de soporte vectorial se ha aplicado a categorización de texto, donde se reporta una gran precisión sin caer en el sobreajuste tomando un gran número de palabras como características de entrada.
El clasificador lineal se basa en dos parámetros, un vector de pesos W perpendicular al hiperplano que separa las instancias y un sesgo b el cual determina el desplazamiento del hiperplano desde el origen. Un ejemplo x es clasificado como una instancia positiva si f(x) = wx + b > 0 y negativa de otra forma. Si los puntos de datos no se pueden separar linealmente, se usa una holgura para aceptar algún error en la clasificación. Esto evita que el clasificador sobreajuste los datos. Cuando más de dos clases están presentes, un grupo de clasificadores es usado para clasificar la instancia. Para este modelo McNamee y Mayfiheld (2002) abordan el problema como uno de decisión binaria, esto se refiere a que si la palabra pertenece a una de las 8 clases, en donde, B- indica el principio de la entidad, I- el interior de la entidad, donde etiqueta es un identificador para persona, organización, ubicación y etiquetas misceláneas. Debido a lo mencionado anteriormente, se cuenta con 8 clasificadores entrenados para tal propósito. Todas las funciones empleadas fueron de tipo binario. Del cual se usaron 258 características de ortografía y puntuación, así como 1000 características relacionadas con el lenguaje. El tamaño de la ventana usada en el modelo fue de 7, lo que genera un total de 8806 características. Para generar una sola etiqueta por cada token, el conjunto S de posibles etiquetas fueron identificadas. Si S es vacío se le asigna la etiqueta O, en caso contrario la etiqueta más frecuente es asignada. Si las etiquetas iniciales como las internas se encuentran presentes, entonces la etiqueta inicial es seleccionada. Para los datos de CoNLL 2002, una precisión de 60.97% y 59.52% para lenguaje Español y Alemán respectivamente fue reportada.
Ventajas SVM
La máquina de soporte vectorial tiene ventaja sobre los algoritmos de aprendizaje estadístico convencionales, como el árbol de decisión, los modelos de Markov ocultos, los modelos de máxima entropía, en los dos aspectos siguientes:
- Cuenta con un alto rendimiento de generalización independientemente de la dimensión de los vectores de características. Los algoritmos convencionales requieren una cuidadosa selección de características, que generalmente se optimiza heurísticamente, para evitar el sobreajuste.
- Pueden llevar a cabo su aprendizaje con todas las combinaciones de características dadas sin aumentar la complejidad computacional al introducir la función Kernel. Los algoritmos convencionales no pueden manejar estas combinaciones de manera eficiente, por lo tanto, generalmente se seleccionan combinaciones importantes de manera heurística teniendo en cuenta el compromiso entre precisión y complejidad computacional.
Los CRF’s son un modelo de aprendizaje relacional. El NER que usa CRF se basa en un modelo gráfico no dirigido de autómatas probabilísticos de estado finito entrenados condicionalmente. El CRF se utiliza para calcular la probabilidad condicional de valores en nodos de salida designados, dados los valores en otros nodos de entrada designados. Incorpora características dependientes y aprendizaje dependiente del contexto. Permite representar dependencias de clasificaciones previas en un discurso. La idea básica es que el contexto que rodea al nombre se convierte en una buena evidencia al etiquetar otra aparición del mismo nombre en un contexto ambiguo diferente. La mayor parte de la investigación en NER consiste en características de lenguaje y etiquetas POS, analizador morfológico, nomenclátores y corpus anotado NE.
Se introdujeron por primera vez en 2001 por Lafferty como una herramienta de modelado estadístico para reconocimiento de patrones y aprendizaje maquina usando predicción estructurada. En 2003 McCallum y Li propusieron un método de inducción de características en las entidades nombradas. Sea o = <o₁,o₂,…,oₜ> una secuencia de datos de entrada observada como una secuencia de palabras dentro de un texto (los valores de n nodos de entrada de un modelo gráfico). Sea S un conjunto de estados de una máquina de estados finita, donde cada uno es asociado con una etiqueta (por ejemplo ORG). Sea s= <s₁,s₂,…,sₜ> una secuencia de estados (los valores en los nodos de salida T). Aplicando el teorema postulado por Hammersley Clifford, los campos alatorios condicionales definen la probabilidad condicional de una secuencia de estados dada una secuencia de entrada como:
donde Z es el factor de normalización obtenido al marginar sobre toda la secuencia de estados, fₖ(sₜ₋₁,sₜ,o,t) es una función característica arbitraria y λₖ es el peso de aprendizaje para cada función característica. Mediante la programación dinámica, el estado de transición entre los estados de dos campos aleatorios condicionales puede ser calculado de forma eficiente. Los valores hacia adelante modificados , αT(sᵢ), para ser la “probabilidad no normalizada” del estado de llegada sᵢ dadas las observaciones <o₁,o₂,…,oₜ>. α0(s) cuenta con la probabilidad de comenzar en cada estado s, y se calcula recursivamente como:
El procedimiento hacia atrás y Baum-Welch han sido similarmente modificados. Zₒ es dado por ∑ₛ αT(s). El algoritmo Viterbi para buscar la secuencia de estado más probable dada una secuencia de observación ha sido modificado desde su forma de modelo oculto de Markov. Los experimentos fueron realizados con los datos CoNLL 2003 y se reporta una precisión de 84.04% para el idioma Inglés y 68.11% para Alemán.
Ventajas CRF
- Comparado con HMM: dado que CRF no tiene supuestos de independencia tan estrictos como HMM, puede acomodar cualquier información de contexto. Su diseño de características es flexible (al igual que ME).
- Comparado con MEMM: dado que CRF calcula la probabilidad condicional de los nodos de salida óptimos globales, supera los inconvenientes del sesgo de etiqueta en MEMM.
- Comparado con ME: CRF calcula la distribución de probabilidad conjunta de toda la secuencia de etiquetas cuando está disponible una secuencia de observación destinada a etiquetar, en lugar de definir la distribución de estados del siguiente únicamente las condiciones del estado actual dadas.
En este artículo de la serie de métodos supervisados en NER se presentó una breve introducción o explicación sobre cada método (máquina de soporte vectorial y campos aleatorios condicionales), su uso en NER, un caso de uso, así como los resultados obtenidos para los idiomas Inglés y Alemán. En ambos artículos de la serie resumimos la aplicación del aprendizaje supervisado al problema de NER, el cual es abordado como una clasificación multi clase o una tarea de etiquetado de secuencias, en donde la representación del vector de características es una abstracción sobre el texto donde una palabra se representa por uno varios booleanos, números o valores nominales. Basado en estas características muchos algoritmos de machine learning se han aplicado en NER supervisado, estos son: modelos ocultos de Markov, de entropía máxima, máquina de soporte vectorial y campos aleatorios condicionales. La estrategia que mejor resultado ha conseguido de estos modelos la encontramos en el etiquetador a trozos basado en HMM dando una precisión de 96.6% en los datos de MUC-6 y 94.1% en los datos de MUC-7. Por último se hace referencia a las ventajas de cada método con respecto a los anteriores. Estos dos últimos modelos nos abren la puerta para dar paso a aquellos métodos no supervisados. Si te pareció interesante comparte y permanece pendiente para los próximos artículos.