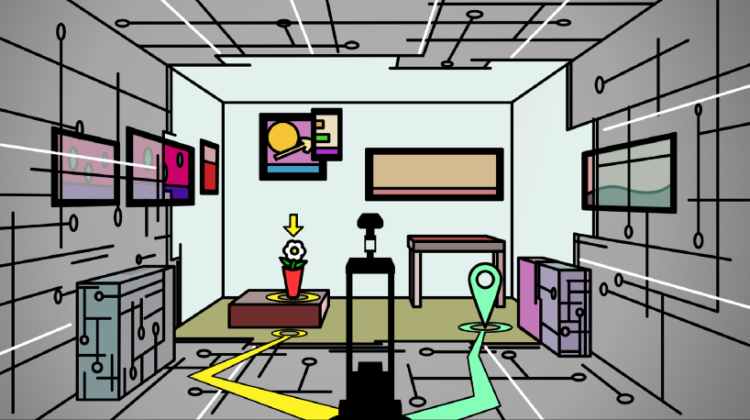
The agent may be spawned anywhere in the environment and may not immediately ‘see’ the pixels containing the answer to its visual goal (i.e. the car/goal may not be visible). Thus, the agent must move to succeed — controlling the pixels that it will perceive. The agent must learn to map its visual input to the correct action based on its perception of the world, the underlying physical constraints, and its understanding of the question. The observations that the agent collects are a consequence of the actions that the agent takes in the environment. The agent is controlling the data distribution that is coming in. The agent controls the pixels it gets to see. This is unlike static datasets, which have been curated online and there’s less control over viewpoint variations of objects, etc. One of the challenges of active perception is to be generally robust to visual variation.
Unlike object detection or image recognition (supervised learning), these agents do collect immediate rewards for each action. Agents in an environment often experience sparse rewards (reinforcement learning). The aim of a reinforcement learning (RL) algorithm is to allow an agent to maximize the rewards from the environment. In some environments, the rewards are supplied to the agent continuously. In others, a positive reward is only provided when the agent completes the goal (e.g., “walk to car”), but it leads to sparse rewards. Sparse rewards can make learning the intended behavior more challenging. It can also make exploration more challenging. For more information on Reinforcement Learning, feel free to read our Overview of Reinforcement Learning.
There are several tasks that can be accomplished in the field of Embodied AI. Here are some of the existing tasks.
1) Visual Odometry. Odometry is using any sensor to determine how much distance has been traversed, so visual odometry is just clarification that the particular sensor to be used for odometry is visual (e.g., camera). Traversed distance in odometry is relative to the starting position. So visual odometry assumes the initial position is known. Visual odometry (VO), as one of the most essential techniques for pose estimation, has attracted significant interest in both the computer vision and robotics communities over the past few decades. It has been widely applied to various robots as a complement to GPS, Inertial Navigation System (INS), wheel odometry, etc. In the last thirty years, enormous work has been done to develop accurate and robust VO systems.
2) Global Localization. Localization is the problem of estimating the position of an autonomous agent given a map of the environment and agent observations. The ability to localize under uncertainty is required by autonomous agents to perform various downstream tasks such as planning, exploration and navigation. Localization is considered as one of the most fundamental problems in robotics. Localization is useful in many real-world applications such as autonomous vehicles, factory robots and delivery drones. The global localization problem assumes the initial position is unknown (as compared to VO which assumes that the initial position is known). Despite the long history of research, global localization is still an open problem.
3) Visual Navigation. Navigation in three-dimensional environments is an essential capability of robots that function in the physical world (or virtual robots in a simulated environment). Animals, including humans, can traverse cluttered dynamic environments with grace and skill in pursuit of many goals. Animals can navigate efficiently and deliberately in previously unseen environments, building up internal representations of these environments in the process. Such internal representations are of central importance to Artificial Intelligence. For more information on Visual Navigation, feel free to read our Overview of Embodied Navigation. (Coming Soon)
4) Grounded Language Learning. We are increasingly surrounded by artificially intelligent technology that takes decisions and executes actions on our behalf. This creates a pressing need for general means to communicate with, instruct and guide artificial agents, with human language the most compelling means for such communication. To achieve this in a scalable fashion, agents must be able to relate language to the world and to actions; that is, their understanding of language must be grounded and embodied. However, learning grounded language is a notoriously challenging problem in artificial intelligence research.
5) Instruction Guided Visual Navigation. The idea that we might be able to give general, verbal instructions to a robot and have at least a reasonable probability that it will carry out the required task is one of the long-held goals of robotics, and artificial intelligence. Despite significant progress, there are a number of major technical challenges that need to be overcome before robots will be able to perform general tasks in the real world. One of the primary requirements will be new techniques for linking natural language to vision and action in unstructured, previously unseen environments. It is the navigation version of this challenge that is referred to as Vision-and-Language Navigation (VLN).
6) Embodied Question Answering. EmbodiedQA is where an agent is spawned at a random location in a 3D environment and asked a question (e.g., ‘What color is the car?’). In order to answer (e.g., ‘Orange!’), the agent must first intelligently navigate to explore the environment, gather information through first-person (egocentric) vision, and then answer the question. This challenging task requires a range of AI skills — active perception (e.g., agent must move to perceive the car — controlling the pixels that it will perceive), language understanding (e.g., what is the question asking?), goal-driven navigation, commonsense reasoning (e.g., where are cars generally located in the house?), and grounding of language into actions (e.g., associate entities in text with corresponding image pixels or sequence of actions).