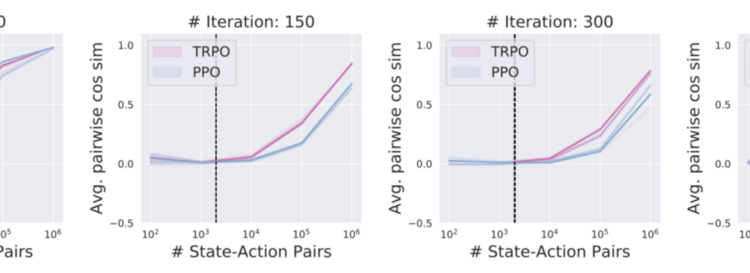
저자들은 위 3가지 기준을 Policy optimization 알고리즘들이 만족하는지를 테스트하기 위해 TRPO, PPO 2가지의 알고리즘으로 실험을 진행하였다.
Policy gradient method들의 핵심은 Policy gradient theorem을 이용하여 충분히 많은 샘플이 있다는 가정 하에 true gradient를 sampled gradient 식으로 바꿔치기 할 수 있다는 것이다. 저자들은 이 ‘충분히 많은 샘플’의 개수가 어느정도인지 대략적으로 세어 보기로 하였다.
Fig. 1, 2에서 볼 수 있듯이, 일반적으로 True gradient estimation에 사용되는 2k개의 샘플로는 True gradient를 거의 반영할 수 없었다. (cosine distance가 0.2라는 것은 평균적으로 True gradient와의 각도가 평균 80도 정도라는 것이다 — Random gradient와 Avg. cos distance가 0인 것을 생각해 보면 얼마나 gradient estimation이 부정확한지를 알 수 있을 것이다.)
많은 Policy gradient method들은 Q(s,a) 대신 Variance를 낮추어 줄 수 있는 Advantage function을 사용한다. 그리고 이를 Value function V(s)만으로 근사할 수 있게 해주는 GAE(General Advantage Estimator)의 등장 이후로 V(s)의 역할은 더욱더 중요해졌다. 과연 이 V(s)는 제대로 학습이 되고 있는가? 더 나아가 Advantage function은 얼마나 Variance를 낮추어주는가?
Fig. 3에서 볼 수 있듯이, Value function의 학습은 상당히 안정적이다. Policy의 stochasticity와 environment의 불확실성을 고려해보면 적어도 Value function은 True value function를 어느 정도 근사할 수 있음을 알 수 있다.
Fig. 4에서 볼 수 있듯이, True value function과는 많은 gap이 있지만 그래도 어느정도 variance를 줄여주고 있다. Value function의 계산이 어렵지 않은 점을 감안하면, variance reduction을 공짜로 얻을 수 있는 Value prediction을 안 쓸 이유는 없어 보인다 (실제로 돌려보면 Value prediction의 유무는 최종 algorithm의 performance에 엄청난 영향을 미친다). 다만 이론적으로 기대되는 (True value function) variance reduction에는 훨씬 미치지 못한다.
Supervised Learning과는 다르게, Policy gradient method에서 policy loss function의 값은 실제 cumulative reward값은 아니지만 gradient가 같은 방향으로 되는 proxy function의 역할을 수행한다. 다시 말해, 이론적으로는 policy loss function을 maximize 시키면 reward도 maximize되어야 한다.
하지만, Fig. 5에서 볼 수 있듯이 학습이 진행되면서 학습에 사용되는 surrogate loss function와 True reward 사이의 간극은 경향성이 바뀔 정도로 커진다. 학습이 진행되기 전에는 loss function이 reward landscape을 잘 반영하지만, 학습이 진행되면서 보통 사용되는 2k정도의 sample로는 아예 경향성이 바뀐다는 것을 보여준다. 이는 에이전트를 학습시킬 때 중간에 학습이 이상하게 삑나는(?) 상황을 설명해준다.