Executive Summary
There have been many attempts to predict the possibility of child abuse or the success of child/parent matching using biological parent data and other commonly available data. Termed predictive analytics, these methods have led to some success in certain states but have scared others regarding the infringement of civil and privacy rights based on the input data used. An attempt is made here to show that using the typical non-invasive metrics that are available during child intake, a predictive tool can be derived to guide social workers in their decisions for children’s outcomes.
Background
When a child comes into an emergency room with injuries or when an adopted child runs away from a foster family, a whole slew of questions are asked. Was the child’s injury/runaway an accident or a form of child abuse? Were there prior injuries or incidents that should have been seen? Were there any family-based events or trauma that should have led us to watch this child’s case more closely?
Families with a fatality or serious injury commonly occurred with multiple risk factors present (Ref. 1). Typical of the risk factors included young parents, unmarried adults in the home, intergenerational abuse, domestic violence, and substance abuse or mental health problems. With the knowledge that some or all of these issues may be present in a child’s home, how does a social worker proceed in terms of removing the child from the home, placing the child with (another) foster family, or placing the child with a relative?
Predictive analytics was thought to have solved this problem (Ref. 2). Predictive analytics is used to quantify the likelihood that a child would experience a life-threatening episode. That technology identifies cases that match certain risk factors and flags those cases for further attention.
One of the predictive analytics methods that generated the most publicity was Mindshare Technology (Ref. 3). Mindshare Technology with their Rapid Safety Feedback product initially generated a lot of praise and results. Subsequent analysis of predictive analytics, in general, provided a number of concerns for using predictive analytics for child welfare (Refs 4 and 5). Specifically, the concerns are related to unreliability, algorithm accuracy, fairness, data privacy, and transparency.
Is there anything that can be done to provide social workers another tool to help guide them in planning a child at risk’s future without duplicating previous predictive analytics drawbacks?
Methodology
This effort assumes that two evaluation questionnaires are available at a child’s evaluation. One of the most popular of the questionnaires is the ten question yes/no ACEs evaluation of a person’s trauma exposure (Ref. 6). A second useful questionnaire is the 23 question, strongly agree/agree/disagree/strongly disagree HT evaluation regarding the risk of being trafficked (Ref. 7). Both of these questionnaires are not so lengthy or cumbersome such that social workers, nurses, doctors, or patients will abandon answering them.
Both of these questionnaires have questions categorized into physiological, safety, love/belonging, and esteem categories. These four categories involved 1) physiological (adequate food, shelter, clothing), 2) safety (safety and security at home and school, lack of feelings of harm and chaos), 3) love/belonging (love, acceptance, relationships), and 4) esteem (recognition, esteem, roles). This categorization makes it easier to determine the types of resources needed for at-risk children to improve the chances of a successful outcome.
Bias in questionnaires and/or the person filling out the questionnaire can be problematic. However, neither of these questionnaires has questions related to gender or race. Thus eliminating gender/race bias that can be built into an algorithm. Neither questionnaire has direct questions about income though the physiological questions concerning lack of food, shelter, and clothing can involve income and potentially introduce income bias.
Other evaluation methods are available such as Structured Decision Making methods and Child Adolescent Needs and Strength tools. These tools can also be used in the effort described here but they tend to be lengthy questionnaires that may not be completed.
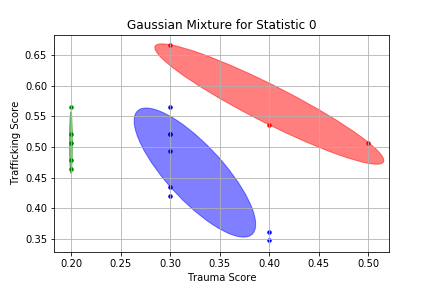
Trauma and trafficking scores for sixteen children under suspicion of being abused or having had a foster care placement that was unsuitable were used in this study. Scores were normalized to a maximum of one for both trauma and trafficking questionnaires. A Gaussian mixture model was derived for the scored results available. A Gaussian mixture model can identify subpopulations within a complete population without prior knowledge of where individuals are expected to reside. For this study, the Gaussian mixture model was used to derive individuals in a high risk, medium risk, or low risk subpopulation without user interaction. Thus no prejudices or biases of the user (i.e., social worker) is involved in deriving the subpopulations.
Results
Figure 1 shows the sixteen trauma/trafficking scores plotted against each other along with the derived subpopulations using the Gaussian mixture model. The ACEs studies indicate that scores above 0.4 start indicating trouble whereas the HT studies indicate that a score above 0.6 indicate higher risk.
The Gaussian mixture model has clustered the sixteen individuals into three clusters of risk. At the upper right in red is the high risk cluster. In this cluster, both high trauma scores and high trafficking scores contribute to the high risk level. In the middle region of Figure 1 is the blue cluster of medium risk individuals. Here some individuals are outside the blue cluster as they don’t quite fit in with the other medium risk individuals but are close. In fact, these outlier individuals are starting to have higher scores that could eventually push them into a high risk region. Finally there is a low risk green cluster of individuals all with a low trauma score of 0.2.
With more individual scoring data available, one might imagine the trauma-trafficking space to start being filled in and the risk clusters may start growing closer to each other. Nonetheless, one would want to let the Gaussian mixture algorithm guide the risk level with review and final determination made by a cognizant social worker.
Figures 2 and 3 show the trauma and trafficking category scores (i.e., physiological, safety, love/belonging, and esteem) for the three individuals in the high risk red cluster from Figure 1. The category scores could be used to determine what is causing an individual to be placed into the high risk cluster and could guide the follow-up plan of learning, therapy, and resources for the individual.
From Figure 2, for example, it can be seen that the high esteem scores within the trauma questionnaire are helping to put individual I3 into the high risk category. Though this does not come out in the trafficking scoring of Figure 3, the related category of love/bonding is high. Thus, perhaps, a recommended course of action to take for this individual would be therapy sessions to promote self-esteem as well as parental/adult therapy related to love/bonding (i.e., affection) and promoting self-esteem.
On the other hand, individual I1 in Figures 2 and 3 shows high category scores in safety. Thus resources related to promoting order and structure at home and school, elimination of threats at home or school, and solving any bullying incidents (if any) would go a long way to reducing individual I1’s risk level.
As can be seen from these examples, the data and algorithms can help to identify and crystallize risk levels as well as categories contributing to risk. The social worker can take this information and use it along with his/her experience to tailor a program to reduce risk.
Commentary
Certainly the methodology described herein was demonstrated for a very limited number of samples. Additionally the learning methods employed were unsupervised learning methods.
A trial program with any CPS agency could be started where more data is collected and results, as they come in, are used with both the current unsupervised clustering method as well as supervised learning algorithms.
Without doubt a set of algorithms is not going to replace the social worker-child interaction inherent in social work. The algorithms can guide the social worker in their evaluations of a case. They can help to eliminate any biases that a social worker has in determining a future course of action for a suspected child abuse case or a troubled foster care case.
It is proposed that the best outcomes for the child would be obtained by screening all of the adults in the household or who have frequent contact with the child. Thus capturing any additional potential sources of risk to the child.
References
1. “Within Our Reach — A National Strategy to Eliminate Child Abuse and Neglect Fatalities”, “City of Long Beach Council Districts”, Commission to Eliminate Child Abuse and Neglect Fatalities, Final Report 2016, http://eckerd.org/wp-content/uploads/2017/10/CECANF-final-report.pdf.
2. “Predictive Analytics in Child Welfare”, ASPE Webpage, 2016, https://aspe.hhs.gov/predictive-analytics-child-welfare.
3. “Saving Children, One Algorithm at a Time”, Hickey, K., GCN Technology, Tools and Tactics for Public Sector IT, 2016, http://mindshare-technology.com/wp-content/uploads/2016/07/saving_children_one_algorithm_at_a_time.pdf.
4. “Coding Over the Cracks: Predictive Analytics and Child Protection”, Glaberson, S. K., Fordham Urban Law Journal, Vol. 46, №2., 2019, https://ir.lawnet.fordham.edu/cgi/viewcontent.cgi?article=2757&context=ulj.
5. “A Child Abuse Prediction Model Fails Poor Families”, Eubanks, V., Wired, 2018, https://www.wired.com/story/excerpt-from-automating-inequality/
6. “Relationship of childhood abuse and household dysfunction to many of the leading causes of death in adults: the adverse childhood experiences (ACE) study.”, Felitti VJ, Anda RF, Nordenberg D, Williamson DF, Spitz AM, Edwards V, Koss MP, Marks JS., Am J Prev Med. 1998;14:245–258.
7. “Hidden in Plain Sight — America’s Slaves of the New Millennium”, Mehlman-Orozco, K., Praeger Publishing, 2017.
8. “Gaussian Mixture Models Explained”, Carrasco, O.C., Towards Data Science, 2019, https://towardsdatascience.com/gaussian-mixture-models-explained-6986aaf5a95.