In machine learning, analyzing data and preparing the data before giving it to the model is of great importance. When I say preparing data, I’m talking about filling empty data, getting rid of outliers, doing future engineering, etc. As data grows and becomes more complex, you will spend more time implementing these processes. But with Pycaret it’s quite the opposite.
Pycaret is a low-code machine learning library. Whether it’s imputing missing values, transforming categorical data, feature engineering, or even hyperparameter tuning of models, PyCaret automates all of it. You don’t need to split or normalize the data either, and Pycaret takes care of them. And it does them with just a few lines of code.
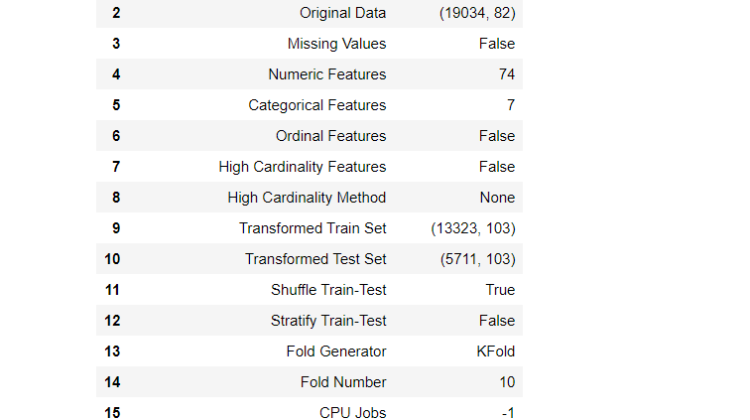
Now I will show you how to use the Pycaret library in machine learning with simple examples. So let’s start:
First, we have included our Pandas library and the Pycaret library for regression.
This function prepares data for modeling and distribution. setup () must called before executing any other function in pycaret. It takes 2 mandatory parameters: dataframe and name of the target column.
This function train all the models available in the model library. The output prints a score grid with MAE, MSE RMSE, R2, RMSLE, and MAPE (averaged across folds), determined by fold parameter.