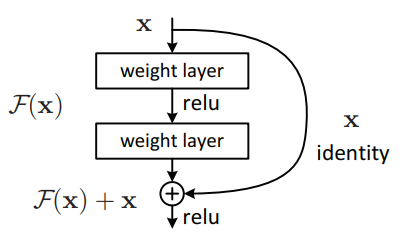
ResNet owes its name to its residual blocks with skip connections that enable the model to be extremely deep. Even though including skip connections is a common idea in the community now, it was a revolutionary architectural choice and allowed ResNet to reach up to 152 layers with no vanishing or exploding gradient problems during training.
For the previous posts, please visit:
Introduction
With the developments in hardware technology and the variety of design techniques in deep learning deeper and deeper models became popular in ImageNet competition. Unlike LeNet and AlexNet, VGG and GoogLeNet managed to deal with larger structures. However, training deeper networks requires some kind of intuition of how gradients flow in the models and a heuristic about how to train models. As models get deeper, research groups needed to push their imaginations and come up with more creative designs. After the Inception module[2] in GoogLeNet, another interesting breakthrough came with the residual learning mechanism of ResNet. Other notable improvements were 1×1 convolutions, dropout layers, and ReLU[3], yet none of them were as daring as these two.
While it is mentioned in detail in the earlier posts, it is still needed to go through the problem of vanishing or exploding gradients. In gradient-based learning procedures, gradients are calculated in terms of the final loss and the weight space. “In machine learning, an artificial neural network is a model that consists of a directed graph, with weights (real numbers) on the edges of the graph. The parameter space is known as a weight space, and “learning” consists of updating the parameters, most often by gradient descent or some variant.”[4] In the final layer, the loss is partially differentiated with respect to each of the weights, and the weights are updated in the reverse direction of the differentiation in order to decrease the loss. The step size of this update can be constant or adaptive and it is controlled by the learning rate of the training procedure. For the prior layers, the gradient flowing backwards from the following layer is multiplied by the input of the layer. As the gradient flows backwards it is multiplied with weight matrices over and over again, which may result in vanishing or exploding gradients. The risk grows as the number of layers increases since the gradient traverses a longer path. Although exploding gradients can be controlled by batch normalization[6] and gradient clipping, vanishing gradients is much bigger of a problem.
ResNet introduces bypass connections in the network and allows the gradient to flow without getting multiplied with weight matrices several times.
In a branched network structure, if a layer leads to multiple modules, the gradient coming from all the modules are summed up and backpropagation continues with the chain rule. In the figure above, if the weight layers tend to have very small numbers (in the order of 10^-5 or smaller) at least some of the gradient would be decreased to a millionth of the gradients in the upper layer. But the idea of ResNet is providing identity connection by bypassing some of the layers, thus making the gradients flow without being subject to any multiplications. That method is a very common architectural choice in recent networks having hundreds of layers.
Even though skip connections make it possible to train extremely deep networks, it is still a tedious process to train these networks and it requires a huge amount of data. It is also covered in VGGNet post that, trying these kinds of networks with MNIST data may not lead to convergence and acceptable accuracies. ResNet is originally trained on ImageNet dataset and using transfer learning[7], it is possible to load pretrained convolutional weights and train a classifier on top of it.
First, needed libraries are imported.
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.keras import datasets, layers, models, losses, Model
The Data
Then, the data is loaded as in the LeNet implementation. One important notice is that the original ResNet model receives images with the size 224 x 224 x 3 however, MNIST images are 28 x 28. The images are padded with zeros and the third axis is expanded and repeated 3 times to make image sizes 32 x 32 x 3. When loading the model from Keras, it is possible to indicate input shape, which will be 32 x 32 x 3, instead of 224 x 224 x 3.
(x_train,y_train),(x_test,y_test) = datasets.mnist.load_data()
x_train = tf.pad(x_train, [[0, 0], [2,2], [2,2]])/255
x_test = tf.pad(x_test, [[0, 0], [2,2], [2,2]])/255
x_train = tf.expand_dims(x_train, axis=3, name=None)
x_test = tf.expand_dims(x_test, axis=3, name=None)
x_train = tf.repeat(x_train, 3, axis=3)
x_test = tf.repeat(x_test, 3, axis=3)
x_val = x_train[-2000:,:,:,:]
y_val = y_train[-2000:]
x_train = x_train[:-2000,:,:,:]
y_train = y_train[:-2000]
The Model
The ResNet model consists of lots and lots of convolutional layers each having 3×3 masks(except the first layer with has 7×7 masks). There are a few variations of the model but ResNet-152 was the model that won ILSVRC in 2015 and it will be implemented in this post. Yes, you guessed it right, 152 is the number of layers the model has. The network is over eight times larger than VGGNet while still having lower complexity.[5] The reason for that is using many small kernels in the layers instead of fewer large kernels and having one fully connected layer with 1000 neurons instead of two fully connected layers with 4096 neurons. In many models, most of the parameters are coming from fully connected layers, since convolutional layers have weight sharing property.
The design is pretty monotonous with only convolutional layers and skip connections other than max-pooling at the beginning and global average pooling at the end.
As you can see in the visuals above, ResNet-152 is absurdly deep and it is usually a good idea to load the model using Keras or any other library. We do not include the top, because that is what we want to train. We only load convolutional weights that are trained on ImageNet data. After loading the model the layers are set “not trainable”, thus frozen.
base_model = tf.keras.applications.ResNet152(weights = 'imagenet', include_top = False, input_shape = (32,32,3))for layer in base_model.layers:
layer.trainable = False
The top is added as follows:
x = layers.Flatten()(base_model.output)
x = layers.Dense(1000, activation='relu')(x)
predictions = layers.Dense(10, activation = 'softmax')(x)
The computational graph is constructed such that it begins with the inputs of the base model and ends with a vector having the size of 10, indicating the probabilities of each category of MNIST. The model is compiled such that it will be trained using Adam optimizer for adaptive learning rate and sparse categorical crossentropy loss.
head_model = Model(inputs = base_model.input, outputs = predictions)head_model.compile(optimizer='adam', loss=losses.sparse_categorical_crossentropy, metrics=['accuracy'])
Model is trained as the backbone layers are frozen. Thus, only fully connected layers that were added afterwards will be trained.
history = head_model.fit(x_train, y_train, batch_size=64, epochs=40, validation_data=(x_val, y_val))Epoch 1/40 907/907 [==============================] - 44s 33ms/step - loss: 1.2104 - accuracy: 0.5902 - val_loss: 0.4982 - val_accuracy: 0.8450
Epoch 2/40 907/907 [==============================] - 28s 31ms/step - loss: 0.6148 - accuracy: 0.8014 - val_loss: 0.3869 - val_accuracy: 0.8955
...
Epoch 40/40
907/907 [==============================] - 28s 31ms/step - loss: 0.2082 - accuracy: 0.9326 - val_loss: 0.1713 - val_accuracy: 0.9495
Even after two epochs, validation accuracy arrives near 90%. After 40 epochs the model comfortably converges. It is possible to reach up to higher accuracies by adding a couple of more fully connected layers. The successful results with only one hidden fully connected layer mean that ResNet-152 does a pretty good job while extracting features for the classifier even though ImageNet and MNIST contain fairly distant image samples.
fig, axs = plt.subplots(2, 1, figsize=(15,15))axs[0].plot(history.history['loss'])
axs[0].plot(history.history['val_loss'])
axs[0].title.set_text('Training Loss vs Validation Loss')
axs[0].set_xlabel('Epochs')
axs[0].set_ylabel('Loss')
axs[0].legend(['Train','Val'])axs[1].plot(history.history['accuracy'])
axs[1].plot(history.history['val_accuracy'])
axs[1].title.set_text('Training Accuracy vs Validation Accuracy')
axs[1].set_xlabel('Epochs')
axs[1].set_ylabel('Accuracy')
axs[1].legend(['Train', 'Val'])
Test accuracy came out at 92.75%.
head_model.evaluate(x_test, y_test)313/313 [==============================] - 7s 20ms/step - loss: 0.2287 - accuracy: 0.9275
[0.22868101298809052, 0.9275000095367432]
resnet_transfer_learning_tensorflow.ipynb
Conclusions
ResNet-152 had a valuable contribution to the literature by being the first model to employ residual learning principles. While many other research groups were looking for ways to train deeper models, ResNet managed to do it with adding skip connections to the architecture and swept competitions in 2015 including ILSVRC. Nowadays, skip connections are being used in not only CNNs but in many other types of networks. Moreover thanks to its impressive learning capacity, it becomes a preferable feature extraction module in many tasks from object recognition to autoencoders. In the ImageNet competition with a 3.6% error rate by even surpassing human performance.
Hope you enjoyed it. See you in the following Deep Learning articles.
Best wishes…
mrgrhn
References
- He, Kaiming & Zhang, Xiangyu & Ren, Shaoqing & Sun, Jian. (2016). “Deep Residual Learning for Image Recognition”. 770–778. 10.1109/CVPR.2016.90.
- Szegedy, Christian & Liu, Wei & Jia, Yangqing & Sermanet, Pierre & Reed, Scott & Anguelov, Dragomir & Erhan, Dumitru & Vanhoucke, Vincent & Rabinovich, Andrew. (2014). “Going Deeper with Convolutions”.
- Krizhevsky, Alex & Sutskever, Ilya & Hinton, Geoffrey. (2012). “ImageNet Classification with Deep Convolutional Neural Networks”. Neural Information Processing Systems. 25. 10.1145/3065386.
- https://www.wikiwand.com/en/Parameter_space
- https://web.cs.hacettepe.edu.tr/~aykut/classes/spring2016/bil722/slides/w04-ResNet.pdf
- Ioffe, Sergey & Szegedy, Christian. (2015). “Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift”.
- Bozinovski, Stevo & Fulgosi, Ante (1976). “The Influence of Pattern Similarity and Transfer Learning upon Training of a Base Perceptron B2.” (original in Croatian) Proceedings of Symposium Informatica 3–121–5, Bled.