Importance of #StratifiedKfold in #machinelearningmodels
When we want to train our ML model we split our entire dataset into training_set and test_set using train_test_split() class present in sklearn. The problem we face is with using different random numbers because of which we get different accuracies and hence we can’t exactly point out the accuracy for our model.
The train_test_split() splits the dataset into training_test and test_set by #randomsampling.
?彡 𝐖𝐡𝐚𝐭 𝐢𝐬 𝐫𝐚𝐧𝐝𝐨𝐦 𝐬𝐚𝐦𝐩𝐥𝐢𝐧𝐠 𝐚𝐧𝐝 𝐒𝐭𝐫𝐚𝐭𝐢𝐟𝐢𝐞𝐝 𝐬𝐚𝐦𝐩𝐥𝐢𝐧𝐠 ?彡
Suppose you want to take a survey and decided to call 1000 people from a particular state, If you pick either 1000 male completely or 1000 female completely or 900 female and 100 male (randomly) to ask their opinion on a particular product.Then based on these 1000 opinion you can’t decide the opinion of that entire state on your product.This is random sampling.
But in Stratified Sampling, Let the population for that state be 51.3% male and 48.7% female, Then for choosing 1000 people from that state if you pick 531 male ( 51.3% of 1000 ) and 487 female ( 48.7% for 1000 ) i.e 531 male + 487 female (Total=1000 people) to ask their opinion. Then these groups of people represent the entire state. This is called as Stratified Sampling.
𝐖𝐡𝐲 𝐫𝐚𝐧𝐝𝐨𝐦 𝐬𝐚𝐦𝐩𝐥𝐢𝐧𝐠 𝐢𝐬 𝐧𝐨𝐭 𝐩𝐫𝐞𝐟𝐞𝐫𝐞𝐝 𝐢𝐧 𝐦𝐚𝐜𝐡𝐢𝐧𝐞 𝐥𝐞𝐚𝐫𝐧𝐢𝐧𝐠 ?
Let’s consider a binary-class classification problem. Let our dataset consists of 100 samples out of which 80 are negative class { 0 } and 20 are positive class { 1 }
▂ ▃ ▅ ▆ █ Random sampling: █ ▆ ▅ ▃ ▂
If we do random sampling to split the dataset into training_set and test_set in 8:2 ratio respectively.Then we might get all negative class {0} in training_set i.e 80 samples in training_test and all 20 positive class {1} in test_set.Now if we train our model on training_set and test our model on test_set, Then obviously we will get a bad accuracy score.
▂ ▃ ▅ ▆ █ Stratified Sampling: █ ▆ ▅ ▃ ▂
In stratified sampling, The training_set consists of 64 negative class{0} ( 80% 0f 80 ) and 16 positive class {1} ( 80% of 20 ) i.e. 64{0}+16{1}=80 samples in training_set which represents the original dataset in equal proportion and similarly test_set consists of 16 negative class {0} ( 20% of 80 ) and 4 positive class{1} ( 20% of 20 ) i.e. 16{0}+4{1}=20 samples in test_set which also represents the entire dataset in equal proportion.This type of train-test-split results in good accuracy.
𝐖𝐡𝐚𝐭 𝐢𝐬 𝐭𝐡𝐞 𝐬𝐨𝐥𝐮𝐭𝐢𝐨𝐧 𝐟𝐨𝐫 𝐦𝐞𝐧𝐭𝐢𝐨𝐧𝐞𝐝 𝐩𝐫𝐨𝐛𝐥𝐞𝐦𝐬?
The solution for the first problem where we were able to get different accuracy score for different random_state parameter value is to use K-Fold Cross-Validation. But K-Fold Cross Validation also suffer from second problem i.e. random sampling.
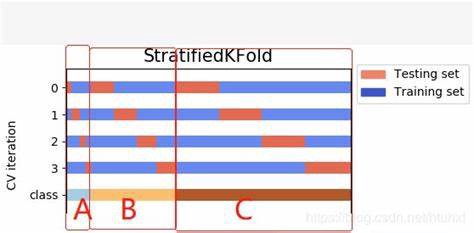
The solution for both first and second problem is to use Stratified K-Fold Cross-Validation.
𝐖𝐡𝐚𝐭 𝐢𝐬 𝐒𝐭𝐫𝐚𝐭𝐢𝐟𝐢𝐞𝐝 𝐊-𝐅𝐨𝐥𝐝 𝐂𝐫𝐨𝐬𝐬 𝐕𝐚𝐥𝐢𝐝𝐚𝐭𝐢𝐨𝐧?
Stratified k-fold cross-validation is same as just k-fold cross-validation, But in Stratified k-fold cross-validation, it does stratified sampling instead of random sampling.