본 논문이 발표되기까지의 몇 년 간 instance segmentation은 object detection으로부터 큰 발전이 있었습니다. Instance segmentation의 sota를 달성한 Mask R-CNN과 FCIS 경우는 object detection인 Faster R-CNN과 R-FCN으로부터 발전이 되었습니다. 하지만 이러한 방식들은 성능에만 치중을 한 나머지 SSD나 YOLO와 같은 real-time한 작업은 전혀 고려하지 않았습니다. 본 논문은 one-stage의 instance segmentation 모델을 통해 SSD나 YOLO와 같은 real-time한 작업이 가능한 방법을 제시합니다.
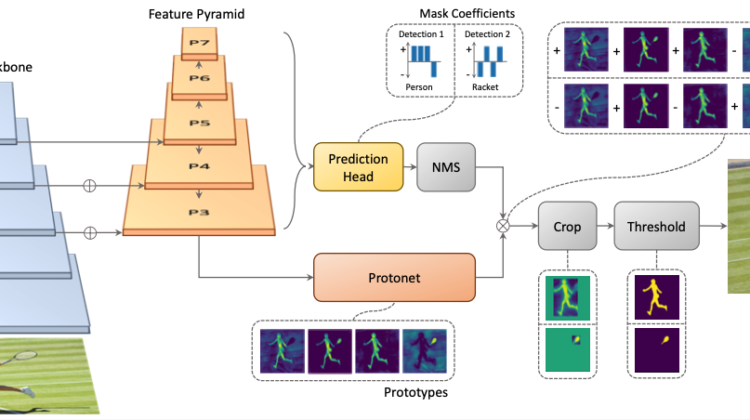
YOLACT의 핵심 method는 Faster R-CNN에 mask branch를 더한 Mask R-CNN과 같이, one-stage object detection model에 mask branch를 추가하는 것입니다. Mask R-CNN과 다른 점은, YOLACT는 repooling(e.g., RoIPool, RoIAlign)과 같은 외부 localization step이 존재하지 않는다는 것입니다. 이를 위해 YOLACT는 mask branch를 두 개의 subtask branch로 나누고 해당 subtask들은 final mask로 assemble이 됩니다.
- FCN을 사용하여 어떠한 하나의 instance에 의존하지 않는 prototype mask들을 생성
- object detector의 branch에 instance정보를 갖는 mask coefficient들을 예측하기 위한 head 추가
그림과 같이 두 subtask는 병렬적으로 수행이 됩니다. 위에서 확인할 수 있듯이 prototype mask들과 coefficient를 assemble 하여 두 개의 detection을 만들어 냅니다.
본 논문에서는 mask coefficient는 semantic한 정보들이 중요하기 때문에 fc layer를 사용하고, prototype mask는 spatial한 정보들이 중요하기 때문에 conv layer를 사용하였다고 합니다.
Prototype Generation
Prototype generation branch(protonet)는 전체 이미지에 대해 k개의 prototype mask를 생성합니다. Mask를 생성할 때는 FCN을 사용하였으며 protonet의 마지막 layer는 k개의 channel을 가집니다.
이러한 prototype mask는 deeper한 backbone으로부터 생성하기 위해 FPN을 사용하였습니다. 또한 작은 object에 대해서도 좋은 성능을 내기 위해 prototype mask의 크기를 4배 upsample 해주었습니다. 마지막으로 activation function으로 ReLU를 사용하였습니다.
Mask Coefficient
전형적인 anchor-base object detector(e.g., RetinaNet)은 prediction head에 2개의 branch를 갖습니다. 따라서 4+c개의 coefficient를 만들게 됩니다. 하지만 본 논문의 head에는 mask coefficient을 위하여 prototype의 개수인 k개 만큼의 coefficient를 추가로 생성하여 총 4+c+k개의 coefficient를 생성합니다.
Final mask에서 prototype에 subtract를 하기 위해서는 nonlinearity가 중요합니다. 이를 위해 k개의 coefficient에는 tanh 연산을 해줍니다.
Mask Assembly
Instance mask를 만들기 위해, prototype branch와 mask coefficient branch로부터 생성된 값들을 linear combination해주어야 합니다. 그 후 final mask를 생성하기 위해 sigmoid 함수를 수행합니다.
P는 h x w x k의 prototype mask matrix이고, C는 n x k의 mask coefficient matrix입니다. 이 때 n은 instance의 개수를 뜻합니다.
Losses
본 논문에는 세가지 loss가 존재합니다.
- L_{cls}
– classification loss
– softmax cross entropy 사용 - L_{box}
– box regression loss
– box regression coordinate들을 train하기 위해 SSD와 같은 smooth-L1 loss 사용 - L_{mask}
– mask loss
– ground truth mask와 assembled mask로 pixel-wise binary cross entropy를 계산
Cropping Masks
Final mask에 대해, evaluation할 때는 predicted bounding box로 crop을 합니다. 반면 training동안에는 ground truth bounding box로 crop을 하고, 작은 물체를 위해 ground truth bounding box area를 L_{mask}로 나눕니다.
Emergent Behavior
Input의 위치와 관계없이 동일한 output을 내는 것을 translation invariance라고 합니다. FCN같은 경우는 translation invariant하기 때문에 위치 정보를 위해 추가적인 task가 필요합니다. Mask R-CNN, FCIS같은 경우는 translation variant하지만, 외부적으로 추가적인 작업(e.g., directional maps, position-sensitive repooling)을 수행합니다. 본 논문에서는 translation invariant하게 만들어주기 위해 cropping을 수행하지만 중간이나 큰 크기의 object들은 이러한 cropping 없이도 translation variant함을 보였습니다.
위는 a~f 이미지에 대한 1~6 prototype의 그림입니다. a열의 빨간 이미지처럼 모든 pixel에 대해 같은 값을 갖는 이미지도 위치에 따라서 다르게 activation이 됨을 볼 수 있습니다.
1~3행의 prototype같은 경우에는 partition에 중점을 두고 있습니다. 게다가 각 prototype은 compressible하여 하나의 기능만 가지고 있는 것이 아닙니다. 2행은 partition 뿐만 아니라 좌하단에 중점을 두고 있고, 3행의 prototype은 우측에 중점을 두고 있습니다. 이렇게 하나의 prototype이 여러 기능을 가지고 있기 때문에, 적은 수의 prototype을 가져도 큰 성능저하가 없습니다.
Prototype의 개수(k)가 32인 경우는 성능과 속도 측면에서 가장 뛰어나지는 않지만 모든 부분에서 준수한 성능을 보이고 있습니다. 오히려 k가 커질수록 coefficient의 계산이 어려워지기 때문에 성능이 감소함을 볼 수 있습니다. 또한 prototype을 늘릴수록 불필요한 prototype들이 추가될 수 있습니다.
본 논문은 prototype과 coefficient이 매우 어려운 task이기 때문에 feature가 풍부하며 빠른 속도를 갖는 backbone detector가 필요했습니다. 속도적인 측면으로 인해 RetinaNet과 매우 구조가 유사합니다.
YOLACT Detector
기본 backbone으로는 FPN을 적용한 ResNet-101을 사용하였습니다. FPN을 수정하여 P5에서 크기가 줄어든 P6, P7을 추가로 만들었습니다.
그리고 각 Pi마다 위 그림과 같은 prediction head를 가지고 있습니다. 본 논문의 prediction head는 앞서 말했듯이 RetinaNet과 비교하여 mask branch를 추가로 가지고 있으며, 각 branch의 task는 병렬적으로 수행이 됩니다. 또한 3개의 branch로 나누어지기 전까지의 layer는 공유되기 때문에 RetinaNet에 비해 경량화 되어 있습니다.
본 논문은 성능에 적은 영향으로 속도를 향상시키거나, 속도의 페널티 없이 성능을 향상시킨 방법들을 소개하고 있습니다.
Fast NMS
기존의 NMS는 다음과 같습니다.
- 각 class들에 대해 confidence가 높은 순으로 anchor들을 정렬
- 순차적으로 anchor 선택
- 가장 confidence가 높은 anchor와 threshold t 이상의 IoU를 갖는 경우 같은 object를 detection 하는 것으로 여기고 해당 anchor 제거
반면에 Fast NMS는 다음과 같습니다.
- 각 class들에 대해 confidence가 높은 n개의 archor 정렬
- 다른 anchor들과 서로 pairwise하게 c x n x n 크기의 IoU matrix X 계산
- 우상단의 값들만 두고 나머지 값들은 제거
- 각 column에서 큰 값들만 갖는 K matrix 생성
- K matrix에서 threshold t보다 작은 value들만 두고 큰 value들 제거
기존의 NMS는 순차적으로 진행된 반면, Fast NMS는 병렬적으로 진행이 됩니다. 따라서 속도가 빨라지게 됩니다. 물론 버려지는 anchor가 많아서 성능의 저하는 생길 수 있으나, 속도의 증가에 비하면 무시할 만한 수준입니다.
위 표에서 보시는 것과 같이 속도의 증가는 폭이 큰 반면, 성능의 저하는 미미합니다.
Semantic Segmentation Loss
Fast NMS를 통해 약간의 성능 저하로 속도가 크게 빨라졌지만, test time이 아닌 training time에만 loss 계산이 되는 module을 통해 속도의 저하 없이 성능의 향상을 이뤄낼 수 있습니다.
Backbone에서 가장 큰 feature map (P3)에 c의 output channel을 갖는 1×1 conv layer를 붙힙니다. 해당 layer는 training time에만 evaluate됩니다. 본 논문은 semantic segmentation과 달리 pixel마다 하나의 class가 있을 필요가 없기 때문에 c개의 channel과 sigmoid function을 사용합니다.
이를 통해 0.4 mAP만큼의 성능 향상이 이루어졌습니다.
MS COCO와 Pascal 2012 SBD로 측정을 하였습니다.
Mask Results
MS COCO에 대한 결과이며 다른 모델들에 비해 월등한 속도를 보여줍니다. YOLACT 뒤의 숫자는 이미지의 크기를 의미합니다. YOLACT-550 같은 경우에는 550×550 크기의 이미지를 사용한 것입니다. 이미지의 크기가 커질수록 속도가 오래 걸리지만 성능 역시 좋아짐을 볼 수 있습니다.
ResNet-50 모델을 backbone으로 사용한 Pascal 2012 SBD 역시 월등한 성능을 보여주고 있습니다.
Mask Quality
FCIS와 Mask R-CNN과 비교하여 깔끔한 mask를 뽑아내고 있습니다. Repooling과 같은 작업이 mask quality를 떨어뜨림을 알 수 있습니다.
Temporal Stability
본 논문의 모델은 정적인 image들에 대해서만 train이 되고, 어더한 temporal smoothing도 적용되지 않습니다. 하지만 video의 가만히 있는 물체에 대해 mask가 흔들리는 Mask R-CNN에 비해 안정적인 mask를 생성합니다. 이는 mask quality가 더 좋은 이유도 있지만, one-stage의 영향이 더 큽니다. First stage의 region proposal에 영향을 받는 two-stage에 비해 본 논문의 모델의 prototype은 box에 영향을 받지 않기 때문입니다.