
Conceitualmente Machine Learning em larga escala é quando processamos mais de 100 bilhões de registros. Para esse processamento ocorrer em tempo satisfatório se faz necessário o uso de cluster de computadores, onde cada máquina vai ficar a cargo do processamento de parte desses registros. Para operacionalizar esse processamento usamos algum software de processamento de dados … [Read more...] about Machine Learning em Larga Escala: Construção do Cluster Spark
Machine Learning
Customizing NetworkX Graphs
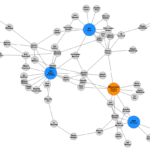
We will start by making a basic graph! There are several ways to do this. I found that the easiest way to do this was from a pandas DataFrame where you specify the edges. What’s an edge? Well, graphs are built using nodes and edges. A node represents some object, perhaps a person or organization, and an edge represents the actual connection from one node to another node. So in … [Read more...] about Customizing NetworkX Graphs
6 Essential Python Tuple Unpacking Techniques You Can Use

When working with existing tuples, sometimes we want to create new tuples that contain all the elements in the existing tuples. In this case, we can use an asterisk that precedes the tuple, which will unpack all the items in the tuple.The following code shows you such an example:Unpacking allBy placing the asterisk before grouping_factors1, we’re able to unpack all of its … [Read more...] about 6 Essential Python Tuple Unpacking Techniques You Can Use
Cognitive Computer Aided Detection of Breast Cancer

Detecting Breast Cancer with DL TechniquesEach year, 182,000 women are diagnosed with breast cancer and 43,300 die. One woman in eight (1/8) either has or will develop breast cancer in her lifetime. If detected early, the five-year survival rate exceeds 95%. Mammography is the gold standard for detecting early signs of breast cancer, which can help cure the disease during its … [Read more...] about Cognitive Computer Aided Detection of Breast Cancer
Do you need a feature store?

By: Monte Zweben, Morgan SweeneySource: alexdndz/Adobe StockA machine learning model is only going to be as good as the data it’s been fed. To be more precise, a model is only as good as the features it’s been given.A feature is a useful metric or attribute taken from either a raw data point or an aggregation of several raw data points. The specific features used in a model … [Read more...] about Do you need a feature store?
Simulated Annealing From Scratch in Python
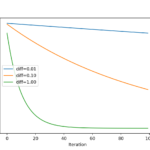
Simulated Annealing is a stochastic global search optimization algorithm. This means that it makes use of randomness as part of the search process. This makes the algorithm appropriate for nonlinear objective functions where other local search algorithms do not operate well. Like the stochastic hill climbing local search algorithm, it modifies a single solution and searches the … [Read more...] about Simulated Annealing From Scratch in Python
TF-IDF

TF : Term FrequencyIDF : Inverse Document Frequency(idf) : The formulae is log(N/No. of document in which the word appear)Here N is the total number of documents.The intuition behind IDF is: Consider we have 100 documents . The frequency of word “insurance” is 100 and the frequency of word “try” is also 100. Now the thing is that try appears in all the document 1 time whereas … [Read more...] about TF-IDF
So… How exactly is AI being used to detect COVID-19?
I’m sure many of us are curious about the mathematics behind such algorithms — how does mathematics factor into these algorithms, and how can the manipulation of mathematical systems produce such stunning results on par with detecting COVID-19?Although the mathematical terms surrounding deep learning, such as “gradient descent”, “backpropagation”, “matrix multiplication” and so … [Read more...] about So… How exactly is AI being used to detect COVID-19?
Andrew Rodrigues de Oliveira | Minha conexão com o mercado digital

Olá, me chamo Andrew Rodrigues, aluno Harve Data Science e vou contar um pouco sobre como está sendo a minha experiência com o mercado digital de Data Science.Se formos levar ao pé da letra, meu primeiro contato com Data Science foi no meu primeiro ano de faculdade, onde fazendo parte da empresa júnior elaborei algumas pesquisas em campo, desde a formulação e aplicação de … [Read more...] about Andrew Rodrigues de Oliveira | Minha conexão com o mercado digital
Text Classification: How BERT boost the performance

We will present three binary text classification models using CNN, LSTM, and BERT.Data PreprocessBecause we get our data from social network like Twitter or Facebook, there are a lot of useless or noisy data in the original dataset. Before feeding data into NLP model for training, we need to clean our text data at first. I list some steps we followed below, you can modify any … [Read more...] about Text Classification: How BERT boost the performance