จากรูปที่ 2 เราก็จะทราบข้อมูลคร่าว ๆ ว่าประกอบด้วย features อะไรบ้าง และมีตัวแปรเป็นประเภทไหนอย่างไรบ้าง โดยจะเห็นว่าจากข้อมูลประกอบด้วย 10 features ได้แก่ longtitude, latitude และอื่นๆ โดย feature median_house_value คือ target ที่เราต้องการจะ predict
หลังจากนั้นเราลองใช้คำสั่ง .info() เพื่อดูว่าแต่ละ features เป็นตัวเลขหรือตัวแปรอื่น และ feature นั้นประกอบด้วยค่า null เยอะน้อยแค่ไหน เพื่อประกอบการตัดสินใจในการจัดการ missing value ถัดไป
โดยจากรูปที่ 3 จะเห็นได้ว่า total bedroom มี missing value เล็กน้อย และ feature ส่วนใหญ่เป็น numerical variable ยกเว้น ocean_proximity ที่เป็น categorical variable งั้นเราไปดูหน่อยดีกว่าว่า ocean proximity มีหน้าตาเป็นอย่างไรและมีจำนวนความต่างของ class ในข้อมูลเยอะแค่ไหนนะ
พบว่าข้อมูลใน ocean_proximity ถูกแบ่งเป็นเพียงแค่ 5 ประเภท โดยมีประเภท <1H Ocean มากที่สุดที่ 9136 instance
หลังจากนั้นเราไปดู numerical variable บ้างดีกว่าว่ามีการกระจายตัวเป็นอย่างไรโดยการใช้ histogram เพื่อหาว่าข้อมูลมีความผิดปกติหรือไม่ เป็น normal distribution หรือไม่ โดยถ้าไม่เป็น normal distribution อาจจะส่งผลต่อ model บางประเภท ทำให้เราต้องเปลี่ยนให้เป็น normal distribution ก่อนสำหรับ model นั้น โดยดังแสดงในรูปที่ 5 ด้านล่าง
โดยจากรูปที่ 5 ผลที่ได้สังเกตได้ว่า
1. ข้อมูลของ median_house_value นั้นมีเทรนด์คือ จำนวนบ้านที่มีราคาสูงจะค่อยๆลดลง แต่พอมาถึงขอบสุดที่ค่า 500,000 พบว่ากลับมีปริมาณมากสุดขึ้นมา โดยที่มาของความผิดปกตินี้มาจากตอนฝ่ายเก็บข้อมูลเค้า limit ให้ราคาทั้งหมดที่เกิน 500,000 อยู่ที่ 500,000 ครับ เลยทำให้ปริมาณมีมากจนผิดปกติ เกือบไปแล้วนะครับ ถ้าไม่ได้ทำ EDA ก่อน โมเดลเราคงเข้าใจผิดเหมือนเราแน่ ๆ ว่า ราคาบ้านไม่มีทางเกิน 500,000 ! โดยวิธีแก้ไขก็คือ การนำข้อมูลตั้งแต่มากกว่า 500,000 ออกไป หรือว่าเป็นการเก็บข้อมูลเพิ่มก็ได้ครับ
2. พบว่าช่วงของข้อมูลแต่ละ feature มีค่าต่างกันมาก ซึ่งอาจจะส่งผลให้บาง model เช่น linear regression มีปัญหาได้ ดังนั้นเราอาจจะต้องทำ feature scaling เสียก่อน
3. พบว่าข้อมูลเป็น tail heavy หรือก็คือ ไม่ใช่ normal distribution ซึ่งอาจส่งผลต่อบางโมเดลอีกเช่นกัน !!
โอโห นี่ขนาดเราพิจารณาแค่คร่าว ๆ ยังไม่ได้ลงรายละเอียดกลับพบข้อมูลที่มีประโยชน์ขนาดนี้ EDA นี่มีประโยชน์จริง ๆ นะครับ
โดยก่อนที่เราจะลงมือทำอะไรกับข้อมูลของเราไปมากกว่านี้นะครับ !! ขั้นตอนที่สำคัญมากเลย คือ เราต้องแบ่งข้อมูลเป็น train, test set ไว้ก่อนครับ ก่อนที่จะทำ data cleaning, data preprocessing เพราะอะไรถึงต้องทำก่อน ? เพราะว่าป้องกันการเกิด Data Leakage ยังไงหละครับ
Data leakage สั้น ๆ ก็คือการที่ข้อมูลใน test set รั่วไหลไปให้โมเดลเห็นและจดจำก่อนที่จะมันจะเจอ data จริง ๆ เสียอีก เหมือนการโกงข้อสอบอะครับ เอาคำตอบมาให้ดูแล้วให้โมเดลทำ ก็ว่าทำไมโมเดลมันเก่งล้ำเลิศแบบนี้ generalize well มาก ๆ ! แต่ว่าที่จริงแล้ว model ไม่ได้เก่งจริง ๆ ซึ่งปัญหานี้จะนำไปสู่ overfitting ครับ แล้วพอเจอข้อมูล unseen จริง ๆ performance ก็จะตกลงตามไปด้วย
โดยในการแบ่งข้อมูลเราอาจจะเลือกใช้ train_test_split หรือ StratifiedShuffleSplit ก็ได้ครับโดยความต่างของสองวิธีสามารถอ่านได้จากบทความนี้ Sampling Algorithm : Train_Test_Split และ StratifiedShuffleSplit ใน Scikit-Learn ต่างกันอย่างไร ??
โดยในที่นี้เราจะขอเลือกใช้ train_test_split ฟังก์ชันใน scikit learn นะครับในการสุ่มแบ่งข้อมูลดังรูปที่ 6
โดย test_size = 0.2 หมายถึงว่า กำหนดให้จำนวน data ใน test set = 20% ของทั้งหมด และ random_state = 42 คือการใส่ไว้เหมือนให้คอมพิวเตอร์จำชุดข้อมูลนี้ที่เราแบ่งไว้ได้ ไม่เช่นนั้นหากเรารันใหม่ train_set เราก็จะเปลี่ยนไปทุกรอบครับ
ขั้นตอนต่อไปเราจะเริ่มทำ feature selection & extraction กันดีกว่า โดยเราอาจจะเริ่มจากพื้นฐานโดยการดู correlation ของ feature กับ feature และ feature กับ target แต่ก่อนที่จะเริ่มทำ เพื่อไม่ให้สิ่งที่เราลองทำมั่ว ๆ ซั่ว ๆ ทำให้ data เราพังพินาศ จึงน่าจะเป็นการดีหากเราจะ copy ข้อมูล train set ก่อนที่จะลงมือทำใด ๆ ดังนี้
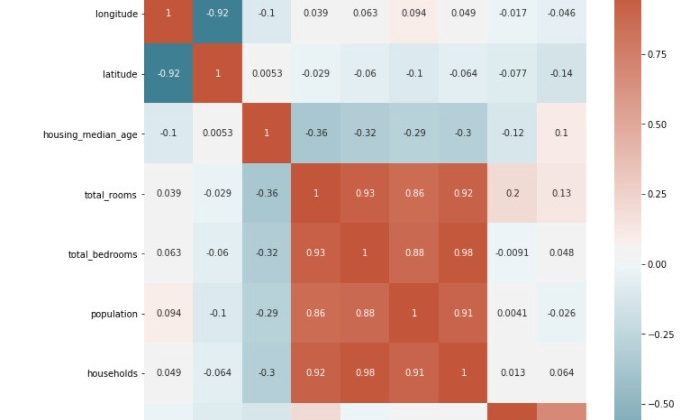
หลังจากนั้นจึงมาดู correlation ของแต่ละตัวแปรเทียบกันโดยใช้ heat map
โดย feature ที่ดีโดยทั่วไปนั้นควรจะมี correlation กับ target และไม่ควรมี correlation ระหว่างกันมากจนเกินไป เช่น หาก feature 1 และ 2 มี correlation ระหว่างกันเท่ากับ 1 เท่ากับว่า ข้อมูลสองตัวนี้ represent ในสิ่งเดียวกัน !! ดังนั้นควรจะป้อนเข้า model แค่เพียง feature เดียว
จากผลที่ได้พบว่า column ที่มี correlation กับ median_house_value คือ median_income หรือรายได้ของคนในพื้นที่นั้น ก็นับว่าเป็นอะไรที่สมเหตุสมผลทีเดียว
หากเราสนใจเพียงแค่ correlation ระหว่าง feature กับ target ก่อนจะใช้คำสั่งดังรูปที่ 9 ด้านล่าง
จากรูปที่ 9 Correlation ของ feature กับ target ยังไม่ค่อยสูงนัก เพราะหากเราลองพิจารณา total_rooms ในที่นี้หมายถึงจำนวนห้องทั้งหมดในเขตนั้น !! ดังนั้นเลขนี้เพียงตัวเดียวอาจจะบอกอะไรไม่ได้ เพราะจำนวนห้องเยอะ อาจมาจากจำนวนบ้านที่เยอะก็ได้
ดังนั้นเราจะสร้าง feature ใหม่ขึ้นมาได้แก่ rooms_per_household หรือจำนวนห้องทั้งหมดหารด้วยจำนวนบ้านทั้งหมด ก็จะได้เป็นจำนวนห้องเฉลี่ยต่อบ้านนั่นเอง
โอ้ !! ฟังดูดีทีเดียว เพราะหากบ้านนึงมีจำนวนห้องเยอะ ก็น่าจะมีราคาแพงตามไปด้วยและนอกจากนั้นเรายังลองเพิ่ม feature ค่าจำนวนห้องนอนต่อจำนวนห้องทั้งหมดเป็นค่าเฉลี่ยเพื่อมาดูเพิ่มอีกตัวแปร
จากรูปที่ 10 จะพบว่า ตัวแปรใหม่สองตัวที่เพิ่งเพิ่มเข้าไป rooms_per_household กับ bedrooms_per_room นั้นมีความสัมพันธ์กับ target มากทีเดียว เท่ากับการสร้าง feature ใหม่ของเราสำเร็จ !!
เพื่อไม่ให้บทความยาวและง่วงนอนไปมากกว่านี้ สามารถอ่านต่อ Part 2 ได้ที่ มาเริ่มต้นทำ Machine Learning โดยการใช้ Pipeline ด้วย Scikit-Learn กันเถอะ [2]