一般而言機器學習無論是經典學習還是深度學習,都可以大致分為三種學習任務:
- 監督學習: Supervised Learning
- 半監督學習: Semi-Supervised Learning
- 無監督學習: Unsupervised Learning
本篇文章會大略的討論一下三種學習的差別以及實務上的適用時機。
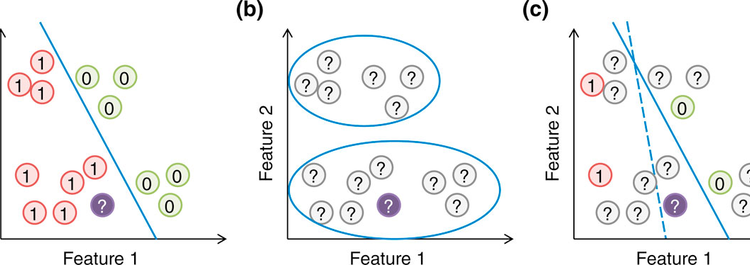
Supervised Learning如圖1(a)所示,每一筆資料(data)都會有對應的標註(label),學習的目標就是求出一個預測函數來預測未知的data對應的label。
在視覺任務領域裡面,Supervised Learning常用的任務包含:
- 圖像分類 Image Classification
- 目標檢測 Object Detection
- 特徵點檢測 Keypoint Detection
- 實例分割 Instance Segmentation
- 圖像描述 Image Captioning
機器學習就要記得一件事:資料與標註越多效果越好。因此如果要求最佳的預測精度而不考慮其他因素的情況下,監督是學習永遠是第一選擇。
監督學習的評估方式也是最簡單直接的,試想在缺少標註數據的情況下評估學習效果會變得更加困難。
監督學習的缺點很明顯:需要標註。標註需要時間與金錢。以標註成本最低的圖像分類為例,圖像分類Open Source數據集ImageNet包含1,281,167的訓練集+50,000的驗證集。如果尋求外部的數據標註公司,分類任務都是以張數計價;越困難的任務標註成本也越大,例如目標檢測的估價大多是以標註框來計算,在同樣的圖片量級會比分類任務貴出好幾倍。
- Labeled data容易取得的任務,例如:銷量預測、機台故障預測
- Labeled data必須取得的任務,例如:生物認證、道路檢測
- 需要高精度的任務,例如:晶圓瑕疵檢測、生物認證
Unsupervised Learning如圖1(b)所示,數據集中只有未標註的資料(unlabeled data),學習目標通常是要預測資料背後的真實分布情況,最經典無監督學習算法就是K-mean分群。
無監督學習在圖像領域有以下經典應用:
- 圖像生成 Image Generation
- 風格遷移 Style Transfer
- 圖像編輯 Image Edition
無監督學習有另一個著名子領域是強化學習(Reinforcement Learning)。在強化學習的目的是學習一個決策函數,可以根據當前的狀態(state)決定最好的行動(action)。強化學習中雖然也沒有標註,但是會存在客觀的模擬環境來產生報酬(Reward)來評估決策系統的好壞。
以下應用都是強化學習的經典應用:
- AI遊戲:AlphaGo、Atari
- 自動駕駛 Self-Driving
- 內容推薦 Content Recommendation
順便列舉無監督學習在圖像領域常用的深度學習算法:
- GAN (Generative Adversarial Network)
- Auto-Encoder
- VAE (Variational Auto-Encoder)
對於不可能標註的任務而言,無監督學習是你唯一的選擇。對於極具前瞻性的任務或研究,無監督學習結合其他機器學習方法極有可能是你需要探索的方向。
無監督學習的資料成本很低。試想如果你的機器學習服務能夠一直收集數據而不標註,同時還能保證精度持續上升,對你跟老闆都是多麼輕鬆寫意的一件事情。
無監督學習對資料的要求比較高。例如對贓數據的容忍較低,也對數據對齊(Data Alignment)有較大的要求。以人臉生成任務為例,所有的人臉中心線都是垂直的。
無監督學習通常需要更複雜的建模以及算力要求。
- 可以做沙箱實驗時,例如:推薦系統、博奕遊戲
- 隨機生成類的任務,例如:人臉生成、海報生成、詞曲生成
- 只需區分正常/異常的任務,例如:視頻異動檢測、信號處理領域
Semi-Supervised Learning如圖1(c)所示,只有部分的data有label,而其他的data則是未標註的(unlabeled)。半監督學習的目標與監督學習完全相同,差別在資料集中存在部分的標注缺失。
半監督學習的方法有很多,但總歸就是用某種特殊的規則或是方法來估計unlabeled data的真實類別。一般最經典的策略是Self-Training:
- 先利用labeled data去訓練一個預測函數
- 逐步去預測剩下的unlabeled data(稱為psudo label),並更新預測函數
- 直到所有data都變成labeled data為止
需要注意的是,套用Self-Training方法的資料本身需要符合Low-Density Seperation假設。用白話文來解釋的話,通常越簡單的任務越符合這個假設。
標註成本較低,並且可以適用於大部分的任務。對於監督學習來說曠日廢時標註,切換到半監督學習就可以大量減少成本。對於線上需要持續優化的機器學習系統來說,只需要少量標注是非常吸引人的。
對於Self-Training類的方法,需要符合Low-Density Seperation假設才能成立;但是大部分的應用很難符合這個假設。
如果你的任務要切換成半監督學習但無法簡單套用Self-Training的話,你的機器學習演算法可能需要引用並嘗試各種創新方法,很可能是修改到足以發論文的地步。
- 符合Low-Density Seperation假設的任務,例如:交通號誌分類(Maybe)
- 如果有少量的標注人力,可以結合Active Learning來使用
- 當資料標註成本無法被滿足,但是資料取得成本很低的時候