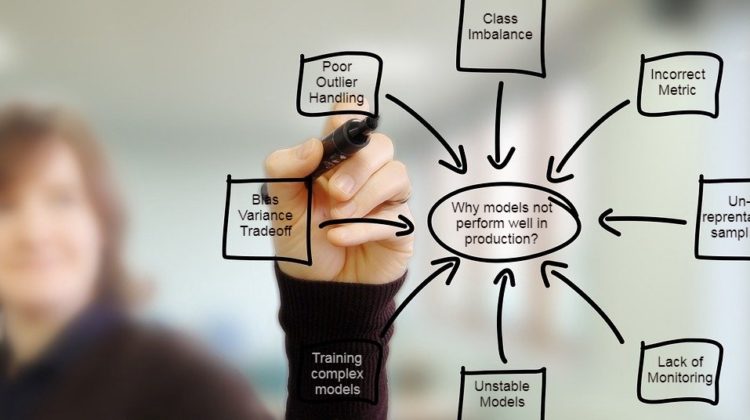
Reasons why a model starts degrading when put in production
Machine Learning models are highly dependent on the quality and quantity of the dataset. Assuming that an ML model will work perfectly without maintenance once in production is a wrong assumption and represents the most common mistake.
An example of model deployment failure is from Netflix Recommendation System Competition. The winner models winning prize money of $1 million was never deployed in production.
In this article, I have listed 9 possible reasons why a machine learning model might not perform well in production and key points that a data scientist should keep in mind while training the models.
Outlier refers to extreme observations present in the dataset, that affects the performance of the model. Poor handling of outliers influences the model estimates. There are various techniques to handle outliers in an efficient manner:
- Some ML models are less affected due to the presence of outliers, and some of the ML models are highly affected by the presence of outliers. So the choice of model should be efficient. For models like Linear Regression that are highly prone to outliers, outliers should be handled well before model training.
- The presence of Multivariate outliers affects the performance of the model in production. Data scientists often overlook multivariate outliers and handle outliers by each feature. Read this to know more about multivariate outliers.
- Read the below article to know more about how to detect and remove outliers.
The class imbalance of the target class label can influence the performance of the model. Some examples of the class imbalanced dataset are Fraud detection, cancer detection, etc. There are various techniques to train ML models for class imbalanced datasets:
- Choice of correct metric: For an imbalanced dataset, the ML model’s performance must be evaluated on metrics such as AUC-ROC score, F1, precision, or recall.
- Oversampling and Undersampling: The minority class samples should be oversampled, to increase the influence of the minority class on the training model, or the majority of class samples should be undersampled, to decrease the influence of the majority class in the training model.
- Read the below article to know more techniques to handle class imbalance.
The choice of the correct evaluation metric is very essential to evaluate the performance of the model, and the efficient performance of the model in production. There is no such one size fit metrics. Metrics chooses should be in line with the return of investment metric from the business side. The model should be trained on a certain metric in such a way the performance threshold is also met and also satisfies the business criteria.
The model in production needs to be monitored on regular basis. The data might change with time, the model that was performing well earlier, the performance will decrease with time. The response variable or the independent variable might change over time that may impact the predictors. The model must be monitored and updated on a regular interval, whether related to its variable, re-estimating the parameters, minor development, or complete new development of the model.
The bias-variance problem is the conflict in trying to simultaneously minimize these two sources of error that prevent supervised machine learning algorithms from generalizing beyond their training set.
A model having high bias and low variance assumes more assumptions about the form of the target function, and a model having high variance and low bias over learns the training dataset.
Examples of low-bias and high-variance ML algorithms: Decision Trees, k-NN and SVM.
Examples of high-bias and low-variance ML algorithms: Linear Regression, Linear Discriminant Analysis and Logistic Regression.
The parameters of the model should be tuned to get the best fit model, that performs the best in production.
In many cases, we end up training models on a population that is significantly different from the actual population. For example, for training a model on a campaign target population and there is no previous record of the previous campaign, this results in un-representative sampling.
Some of the models are often highly unstable and do not perform that well with time. In such cases, the business might demand high-frequency model revision and model monitoring. With higher lead time in model creation, businesses might start going back to intuition-based strategy.
Dynamic variables are those that change a lot with time. When a model is highly dependent on such dynamic variables and it brings a lot of predicting power to the model hence increasing the performance. Due to a change in these dynamic variables, the model performance is affected to a great extent. For example, if the model is most dependent on a feature — the number of sales per month for a retailer, and the month having the shop opened for only 10–15 days, this might affect the performance of the model.
The predictive power of an ML model is the soul of the problem solution. But, predictive power comes at a cost of the complexity of the model. More complex ensemble models have better performance compared to a simple model, but the interpretability of the model decreases. Such models might be amazing in performance, but once deployed in production the performance starts degrading.
‘Garbage In, Garbage Out’ applies to Machine Learning. An ML does not work perfectly without maintenance once in production, it requires monitoring frequently. Also, a data scientist should keep the above-mentioned points in mind before deployment of the model into production.
Other common issues are:
- Over Simplification
- Implementation Issues
- Lacking business knowledge
- Insufficient or Incorrect data
[1] https://towardsdatascience.com/why-machine-learning-models-degrade-in-production-d0f2108e9214
[2] https://towardsdatascience.com/why-90-percent-of-all-machine-learning-models-never-make-it-into-production-ce7e250d5a4a
Thank You for Reading