From data collection to EDA, to labeling, to building sophisticated ML models for assessing road safety (with some of the world´s finest data scientists, data engineers, and ML experts).
“Incredible change happens in your life when you decide to take control of what you have power over instead of craving control over what you don’t.” — Steve Maraboli
And that is what I did. I took control of what I can. I chose to work on a two-month AI project with more than 40 collaborators from around the world.
Being an undergraduate student, managing academics with some extra co-curricular activities has always been challenging me. I had always tried to make the most out of my leisure time. This lockdown was no exception. From Learning and Exploring Machine Learning to getting selected as a Junior ML Engineer on a Computer Vision Project at Omdena to rising to Machine Learning Engineer by the end of two months was super noteworthy.
Saving Lives Together
The last two months couldn’t have been more productive than collaborating on a road safety project with a moto of #savinglivestogether and working with some of the finest ML engineers across the globe. I am delighted to have completed the AI for road safety project by Omdena in collaboration with iRAP. The project started in mid-November 2020 with 50 changemakers all across the globe. 50 #AI changemakers from 24 countries (33% women) unite to kick off the RoadSafety Challenge with iRAP.
The problem statement was Preventing Road Crashes and Saving Lives. The challenge itself fascinated me a lot so I was eager to get things started.
Our problem was to map the crash risk on every road on earth for each type of road user; identify the infrastructure design, speed, and volume features that influence that risk, and produce the data regularly to drive visibility, accountability, action, and performance tracking.
The project focused on the analysis of data and its possibilities, road feature extraction from existing data, producing Risk Maps of the historical crashes, crashes traveled for each road user, map the safety performance and deal with Star Rating as per iRAP standards. My work involved building object detection models with YOLO v3, open CV, Resnet, and COCO.
From Collecting the Data to Labelling
I had to deal with the accuracy of each of them and how we can optimize it to make it fit our data properly. I also worked with panoramic images from the tomtom dataset.
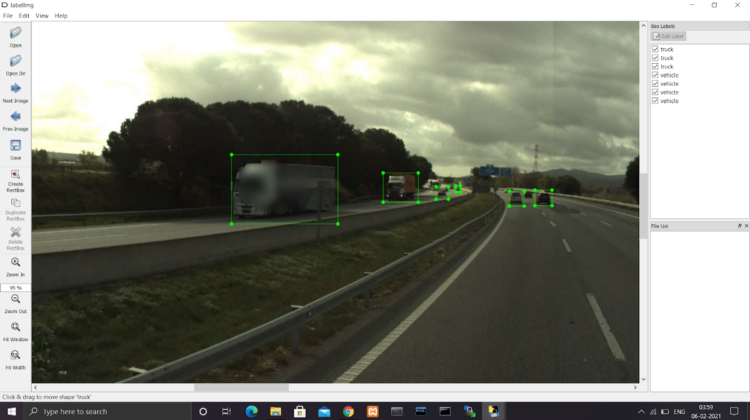
TomTom Historical Traffic Stats is a self-service product that analyzes historical location data and provides traffic insights on speed, travel time, and sample size on the road network. It basically contained all the real-world images of road and traffic. One of the images is added here. We chose this dataset because it had LiDAR(Light Detection and Ranging) as well as panoramic images which helped us analyze the road features and get comfortable with various aspects of the road which iRAP takes into consideration.
The TomTom dataset was unlabelled and our team labeled it according to the iRAP standards with around 3,964 images (10.9 GB). It included Panoramic images for ESP(Spain Road Images) and MEX(Mexico Road Images).
The first and the foremost challenge with TomTom data for me was dealing with and handling the big data using Amazon S3, which I hadn’t done before. I received good community support as and when stuck with any issue like this. The best thing was some of the other collaborators were active on slack at any point of the day whom I could reach out to.
I, along with the team, annotated the images manually, and we used a labeling tool (labelImg). We completed annotating nearly 2K images captured by TomTom. Also, I had an opportunity to work on the pipeline of the project using Spell ML.
Spell ML is a platform for building and managing machine learning projects. It is generally used for pipelining machine learning projects. Our team used this software for pipelining the work of every individual or small group to make it onto the whole final piece.
The Community, the Help, and the Sprint Calls
We did also have a few code sprints and data sprints where all collaborators working on the same part were having an interactive session with doubts solving, helping each other, and indeed building a community.
I would especially like to mention the annotation sprint, where all the collaborators involved in this task joined in and discussed labeling, the software used for annotating images. We divided the images amongst ourselves and continued annotating those. This sprint lasted almost 8–10 hours, where everyone was free to join and leave as per their timezone. We also had several other meetings where everyone shared their status of work, their doubts, and difficulties faced at any point in time, and helped each other with their fullest knowledge.
It is rightly said by Helen Keller,
“Alone, we can do so little; together, we can do so much.”
I had a great learning and working experience with all the amazing changemakers who put their entire efforts to get this done. Apart from my technical skills, I greatly enhanced my communication skills. I got to meet many new and extraordinary data scientists around the world, and I genuinely think that making friends working together is an achievement for me.
The Omdena community was the best thing I could have ever asked for.
I got to communicate with many changemakers, where I learned and explored different things that couldn’t have been possible without the community support. Learning from each other’s experience, and knowledge is the most crucial factor when it comes to team building. The best thing was all the collaborators shared their experience and knowledge, very firmly and positively about any particular task. The project had such diverse people from different regions across the world but all were united as a team.
Concluding, I would say I really enjoyed being part of this team and understood that community building is as much important as learning technical things, to make the teamwork successful!
#community #aiforgood #roadsafety #computervision #savinglivestogether #3starsorbetter