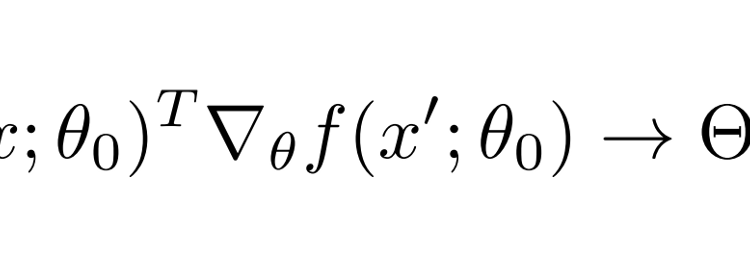
How do neural networks behave when the hidden layers are very large? A new research direction in machine learning studies network behavior in the limit that the size of each hidden layer increases to infinity. Surprisingly, in this limit the behavior of the network dramatically simplifies and we can understand what the network is doing theoretically. Why does this happen and what can we say?
The fundamental reason that wide networks have a simpler behavior is that they are close to their linear approximation:
where the linear approximation to the network is defined by
This is simply the first two terms of the Taylor series expansion of f with respect to the parameters θ around their initial values θ₀. Importantly, the linearized function depends only linearly on the parameters of the network. Therefore, this model can be thought of as feature regression model, where the model is simply a linear combination of these features determined by the input x. In our case, reading the coefficients of θ from the definition of the linearized network, the feature vector is simply
The feature regression model is a simple model you might study in a statistics class and has a nice analytically tractable solution. There is a single mathematical object called a kernel that characterizes the behavior of this linear regression. The kernel function, which has two inputs, is simply defined in terms of the features as
In any feature regression model, the kernel K does two things simultaneously:
- It controls how the model evolves during training
- It specifies the distribution of the model on initialization
Combining these two properties, you can explicitly write the output of the feature regression problem as a simple function in terms of the kernel K and the training data.
In our neural net problem, the kernel is random because it depends on the random initialization of the parameters θ₀. The formula for our kernel is
However, as the number of parameters in the networks gets larger, a minor mathematical miracle occurs! In the limit that the number of parameters goes to infinity, the randomness is averaged away! The resulting limit is a non-random kernel. This occurs for the same reason that the fraction of “heads” in a random sample of n coinflips is random, but nevertheless approaches a non-random limit as n grows to infinity. In the case of coinflips, the limit is ½. In the case of the neural networks, the kernel converges to a limit called the neural tangent kernel which is (somewhat confusingly) denoted with a capital letter ϴ.
The neural tangent kernel controls the training dynamics of the network in this limit. This is therefore a powerful tool which can be used as alternative way to train networks or as a tool to theoretically analyze the behavior of neural networks.
For more mathematical details on the random feature regression model and the neural tangent kernel, I wrote some introductory notes available here and made some accompanying YouTube videos which go over them here (each video from the playlist covers one subsection of the notes)
Here is the introduction video and the video with the summary of results on wide neural networks