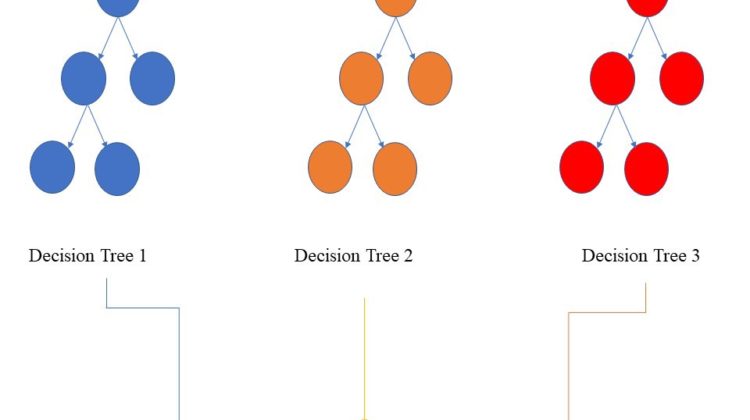
A random forest classifier represents an assembly of a number of decision tree classifiers on various sub-samples of the dataset. Random forest classifier is a part of the ensemble learning method offered by scikit-learn. Because it includes a number of decision trees, it averages the predictive accuracy of all the trees. The advantage of using a random forest classifier is, unlike the decision trees, random forest classifiers can control overfitting. Also, random forest classifiers produce reasonable predictions.
Today, we’ll see an example of the random forest classifier on a simple digit recognition problem. We’ll use Jupyter notebook for compiling, but spyder or pycharm or any other IDE should work just fine.
First, import the necessary libraries. We’ll use mostly open-cv, matplotlib and of course scikit-learn.
import os
import numpy as np
import cv2
import pickle
import matplotlib.pyplot as plt
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.externals.joblib import dump, load
from skimage.feature import hog
from sklearn import metrics
Now that we imported the libraries, let’s start working on the dataset:
X = []
y = []for i in range(1, 11):
data_folder = os.getcwd()+ f’\digits\Sample{f”{i}”.zfill(3)}\’
for images in os.listdir(data_folder):
img = cv2.imread(data_folder+images) # load a color image into greyscale image
img = cv2.medianBlur(img,5) # median blur to remove salt & and pepper noise
img = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
img = cv2.equalizeHist(img) # Equalize histogram
img_resized = cv2.resize(img,(30,30))X.append(img_resized.reshape(-1,1))
y.append(i-1)X = np.array(X)
print(X.shape)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.2)
The explanation of each command is given beside each line. ( ex.-#load a color image into greyscale image) After processing the dataset, we split it into two subsets, i.e., training and testing by the train_test_split method.
Let’s import the random forest classifier and then fit it to the dataset by the fit method.
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(n_estimators = 100, criterion = ‘entropy’, random_state = 42)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(‘Accuracy of Random Forest classifier on test set: {:.2f}’.format(clf.score(X_test, y_test)))
from sklearn import metrics
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
print(“Classification report for — n{}:n{}n”.format(clf, metrics.classification_report(y_test, y_pred)))
cm = confusion_matrix(y_test, y_pred, labels=clf.classes_)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=clf.classes_)
disp.plot()
import joblibjoblib.dump(clf,’rf2.joblib’)
print(“model saved”)
The accuracy of the model can be tested by calling out the score method on the test set and comparing it to the predicted values. Also, scikit-learn provides two very important methods. First, classification report that visualizes a summary of the precision, recall, F1 score for each class. Second, confusion_matrix, which compares the actual target values with those predicted by the machine learning model. The columns represent the actual values of the target variable. The rows represent the predicted values of the target variable.
Here, the confusion matrix shows very good prediction performance by the model. After training the model, you can save it by the dump method on joblib, so that you can use it later.
Following represents the prediction by the trained model:
Full code and the detailed information on the dataset can be found here: https://github.com/AyeshaM67/Digit-Recognition-with-RandomForestClassifier
Hope, this was helpful for you.
Reference-