Gathering The Data
In addition to standard real-estate features like bedrooms, bathrooms, area, etc., the data also includes:
- 3 images per property (also contained in the Github repo)
- 2 published flood risk ratings, one from FEMA, and one from First Street’s Flood Score
- Each property is/was listed for sale with a published asking price on realtor.com, as of the 3rd week in February, 2021 (last week)
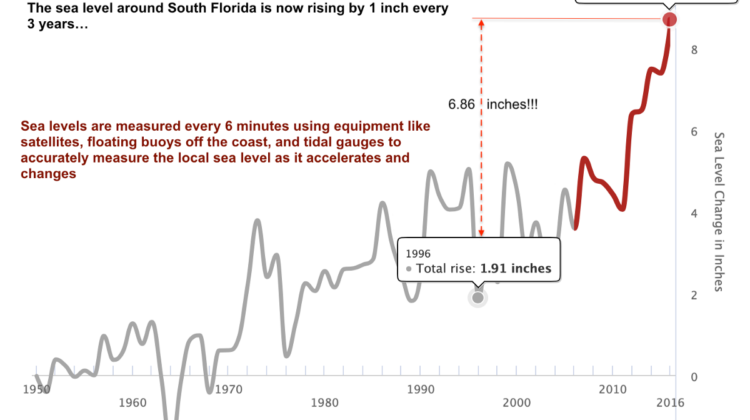
- Each property is appended with the closest matching Zillow Home Value Index ZHVI (aggregated and merged on Zipcode + number of bedrooms), resulting in a monthly time-series index price of nearby homes, dating back to 1996
- Additionally, many other public datasets, such as the relevant area Census data demographics, were appended for each property
This dataset includes records of over 1600 south Florida real estate properties, each with over 650 columns, and includes flood risk information, demographic information, listing images, listing descriptions, how long the property has been listed, sales history, and lots of other related information.
Load the Property Data
Scraping data is a bit messy. Many values available on one real estate listing, might not also be found on another listing. The scaper easily gets confused with AJAX loading and other complications, therefore, we need to clean up things before we can build the model. Because it’s time-consuming to clean-up everything, we will do a “quick-pass” here, but there will be additional data that could be cleaned in order to obtain more training data. Please feel free to do this and provide a link!
import pandas as pd
import evalml
from evalml.preprocessing import load_dataproperty_data = pd.read_csv('../data/raw/property.csv').reset_index()
Load the Demographic Data
Geocodio provides a few data sets we can easily append to our property data, for additional studies and usage:
The US Census BureauLocal city, county, and state datasets from OpenAddressesOpenStreetMapGeoNamesCanVecPlus by Natural Resources CanadaStatCanLegislator information from the UnitedStates project on GitHub
demographics_data = pd.read_csv('../data/raw/demographics.csv', low_memory=False).reset_index()
Merge the Data
The data has been presorted, and reindexed, therefore we can simply merge on the index id.
merged = pd.merge(property_data, demographics_data, on='index')
Note that the word sqft is contained within the column Area, therefore we will identify all rows which contain sqft, and disregard rows that dont. NOTE: rows that do not contain sqft would need to be cleaned in a seperate workflow. For no, we will focus on cleaning the bulk of the data only, and later on we can come back to clean the stragglers.
word = 'sqft'
new_df = merged[merged["Area"].str.contains(word) == True]
Other columns need similar cleaning, such as Beds, FloodInfo, and YearBuilt.
word = 'bed'
new_df = new_df[new_df["Beds"].str.contains(word) == True]word = 'Year Built'
new_df = new_df[new_df["YearBuilt"].str.contains(word) == True]word = 'Flood Factor'
new_df = new_df[new_df["FloodInfo"].str.contains(word) == True]
The Style column is a total mess because many/most listings do not include this information. For now, we will simply drop it to save time parsing the mess.
new_df = new_df.drop('Style',axis=1)
Using Featuretools to speed up data cleaning.
The Featuretools library has a few great data cleaning tools we will use to save time. Specifically:
remove_low_information_features: Keep only features that have at least 2 unique values and that are not all nullremove_highly_null_features: Removes columns from a feature matrix that have higher than a set threshold of null values.remove_single_value_features: Removes columns in feature matrix that are highly correlated with another column.remove_highly_correlated_features: Removes columns in feature matrix that are highly correlated with another column.
from featuretools.selection import remove_low_information_features, remove_highly_null_features, remove_single_value_features, remove_highly_correlated_featuresdf = new_df.copy()"""Select features that have at least 2 unique values and that are not all null"""df_t = remove_low_information_features(df)"""Removes columns from a feature matrix that have higher than a set threshold"""df_t = remove_highly_null_features(df_t)"""Removes columns in feature matrix where all the values are the same."""df_t = remove_single_value_features(df_t)"""Removes columns in feature matrix that are highly correlated with another column."""df_t = remove_highly_correlated_features(df_t)
Clean up the Flood Risk Data
The Flood Risk Data is a prominent feature of this study, so we want to clean up the formatting a bit.
df_t[['FemaInfo','FloodFactorInfo']] = df_t.FloodInfo.str.split(' • ', expand=True)
df_t['FloodFactorInfo'] = df_t['FloodFactorInfo'].astype(str).str.replace('/10 New','').str.replace('Flood Factor ','')
df_t['FemaInfo'] = df_t['FemaInfo'].astype(str).str.replace('FEMA Zone ','').str.replace('(est.)','')
We cannot reformat things like Area and Baths and Year Built and Days on Realtor.com as long as they contain text characters, so we need to remove these in order to correctly format the dataset for training our model.
df_t['Beds'] = df_t['Beds'].str.replace('bed','')
df_t['Baths'] = df_t['Baths'].str.replace('bath','')
df_t['Noise'] = df_t['Noise'].str.replace('Noise:','')
df_t['PropertyType'] = df_t['PropertyType'].str.replace('Property Type','')
df_t['DaysOnRealtor'] = df_t['DaysOnRealtor'].str.replace('Days on Realtor.com','').str.replace('Days','')
df_t['Area'] = df_t['Area'].str.replace('sqft','').str.replace(',','')
df_t['Price'] = df_t['Price'].str.replace('$','').str.replace(',','').str.replace(',','')
df_t['PricePerSQFT'] = df_t['PricePerSQFT'].astype(str).str.replace(',','')
df_t['YearBuilt'] = df_t['YearBuilt'].astype(str).str.replace('Year Built','')
Split up the LastSoldAmt and LastSoldYear features
These columns were included together in the scraped data, so we need to split them up accordingly, in order to properly format them as model features.
df_t[['LastSoldAmt','LastSoldYear']] = df_t.LastSold.str.split(' in ', expand=True)
Cleanup the LastSoldAmt
The LastSoldAmt data used text characters to indicate thousands and millions, however, for our purposes we need to replace these with their numerical kin.
df_t['LastSoldAmt'] = df_t['LastSoldAmt'].astype(str).str.replace('k','000')
df_t['LastSoldAmt'] = df_t['LastSoldAmt'].astype(str).str.replace('M','000000').str.replace('.','').str.replace('Last Sold','').str.replace('$','').str.replace('000000','0000')
Drop Unecessary Columns and Save the Preprocessed Data
df_t = df_t.drop('LastSold',axis=1)
df_t = df_t.drop('index',axis=1)
df_t = df_t.reset_index()
drop_cols = [col for col in df_t.columns if 'url' in col.lower() or ' id' in col.lower()]
X_t = df_t
X_t = X_t.drop(drop_cols,axis=1)
t_datapath = '../data/processed/preprocessed.csv'
X_t.to_csv(t_datapath,index=False)
Download the Property Images for Later Use
Each property in the dataset comes with 3 urls conatining listing images. While these images are not immediately of concern, we will be using them in a later blog post. For now, we will simply download them.
import requestsdef download_images(indx):
file_name = str(indx)+'.png'
urldata = df_t[df_t['index']==indx]
url1 = df_t['Image_URL'].values[0]
url2 = df_t['Image_URL1'].values[0]
url3 = df_t['Image_URL2'].values[0]
urls = [url1,url2,url3]
ct=0
for url in urls:
response = requests.get(url)
with open('../data/images/_'+str(ct)+'_'+file_name, "wb") as file:
file.write(response.content)
file.close()
ct+=1df_t['index'].apply(download_images)
Merge the Zillow Data
ZHVI User Guide
One of Zillow’s most cited metrics is ZHVI, the Zillow Home Value Index. It tells us the typical home value in a given geography (metro area, city, ZIP code, etc.), now and over time, for specific property types and sizes. For general information about ZHVI, please refer to this methodology guide and this lighter-hearted video.
We will merge on the key created which concatenates the area Zip code and the property bedroom count in zipbeds:
zillow1beds = pd.read_csv('../data/raw/zillow1bed.csv')
zillow1beds['zipbeds'] = zillow1beds['RegionName'].astype(str)+'_'+str(1)zillow2beds = pd.read_csv('../data/raw/zillow2bed.csv')
zillow2beds['zipbeds'] = zillow2beds['RegionName'].astype(str)+'_'+str(2)zillow3beds = pd.read_csv('../data/raw/zillow3bed.csv')
zillow3beds['zipbeds'] = zillow3beds['RegionName'].astype(str)+'_'+str(3)zillow4beds = pd.read_csv('../data/raw/zillow4bed.csv')
zillow4beds['zipbeds'] = zillow4beds['RegionName'].astype(str)+'_'+str(4)zillow5beds = pd.read_csv('../data/raw/zillow5bed.csv')
zillow5beds['zipbeds'] = zillow5beds['RegionName'].astype(str)+'_'+str(5)zillowdata = pd.concat([zillow1beds, zillow2beds, zillow3beds, zillow4beds, zillow5beds])# load preprocessed data
t_datapath = '../data/processed/preprocessed.csv'target = 'Price'#set to None for production / actual use, set lower for testing
n_rows=None#set the index
index='index'X, y = load_data(t_datapath, index=index, target=target, n_rows=n_rows)y = y.reset_index().drop('index',axis=1).reset_index()[target]
X_t = X.reset_index().drop('index',axis=1).reset_index()
X_t[target]=ydf_t['LastSoldDate'] = '1/31/' + df_t['LastSoldYear'].astype(str).str[2:4]
df_t['zipbeds'] = df_t['Zip'].astype(str).str.replace('zip_','')+'_'+df_t['Beds'].astype(str)
zipbeds = list(set(df_t['zipbeds'].values))
zillowdata['zipbeds'] = zillowdata['zipbeds'].astype(str)
df_t['zipbeds'] = df_t['zipbeds'].astype(str)Number of Features
Categorical 60
Numeric 640Number of training examples: 1071
Targets
325000 1.49%
450000 1.21%
350000 1.21%
339000 0.93%
349900 0.84%
...
245000 0.09%
5750000 0.09%
74995 0.09%
2379000 0.09%
256000 0.09%
Name: Price, Length: 567, dtype: object
Columns (5,9,23,700) have mixed types.Specify dtype option on import or set low_memory=False.df_t = pd.merge(df_t, zillowdata, on='zipbeds')
Calculate the rate of change for each Property, and its comparables
In real estate, a comparable is a nearby property with similar features, such as the same number of bedrooms. In our case, for each property we merged on zipbeds we want to train a model to predict the difference in the rate of change of the price vs the rate of change in price for nearby comparables. To do this, we will find the LastSoldDate column for the target property, and lookup the corresponding ZHVI rate of change from that date until now.
X_t = df_t.copy()time_series_cols = [col for col in X_t.columns if '/' in col and 'Percentage' not in col and 'Value' not in col and 'Margin of error' not in col and 'Metro' not in col and col != '1/31/21']l = []
for ct in range(len(X_t)):
try:
indx = X_t['index'].values[ct]
last_sold_date = X_t['LastSoldDate'].values[ct]
zillow_price = X_t[last_sold_date].values[ct]
X_ts = X_t[X_t['index']==indx]
X_ts['zillow_price'] = zillow_price
X_ts['zillow_price_change'] = X_ts['1/31/21'].astype(float) - X_ts['zillow_price'].astype(float)
X_ts['zillow_price_change_rate'] = X_ts['zillow_price_change'].astype(float) / float(2021.0 - X_ts['LastSoldYear'].astype(float))
X_ts['zillow_price_change_percent'] = X_ts['zillow_price_change'].astype(float) / X_ts['zillow_price'].astype(float)
l.append(X_ts)
except: passdf = pd.concat(l)
df['last_sold_price_change'] = df['Price'].astype(float) - df['LastSoldAmt'].astype(float)
df['last_sold_price_change_percent'] = (df['Price'].astype(float) - df['LastSoldAmt'].astype(float)) / df['LastSoldAmt'].astype(float)
df['last_sold_price_change_rate'] = df['last_sold_price_change'].astype(float) / float(2021.0 - X_ts['LastSoldYear'].astype(float))
df['yearly_price_delta'] = df['last_sold_price_change_rate'].astype(float) - df['zillow_price_change_rate'].astype(float)
Defining the Target Variable we will train our model to predict.
For our initial blog entry, we will use the feature yearly_price_delta_percent as our target variable. It is defined as follows:
df['yearly_price_delta_percent'] = df['last_sold_price_change_percent'].astype(float) - df['zillow_price_change_percent'].astype(float)
Final Cleanup & Save
A few straggler text characters remain in some numerical columns, so remove them then save.
df = df.drop(time_series_cols, axis=1)
df =df[df['LastSoldAmt'] != 'Property TypeTownhome']
df = df[df['LastSoldAmt'] != 'Property TypeSingle Family Home']
df.to_csv('../data/processed/zillow_merged.csv',index=False)
Benchmarking with AutoML
While the raw dataset is much larger, for the purposes of this post, we will be focusing on a smaller sample of features.