As humans, a quantum computer doesn’t play chess at a grandmaster level by birth. Humans have to train very hard to become better and ultimately beat their opponents.
On the one hand, they train by thinking of possible moves and evaluate which advantages and disadvantages every move has. They rank the different moves by value and build up a set of desired moves in their head. During time humans change their thinking and tend to come up with the better moves more often (supervised learning).
On the other hand, they train by playing against other players. Sometimes they loose. Sometimes they win. A player becomes better by replaying winning moves of successful games and avoiding loosing moves of unsuccessful games (reinforcement learning).
We try to replicate both human training methods when training our quantum computer .
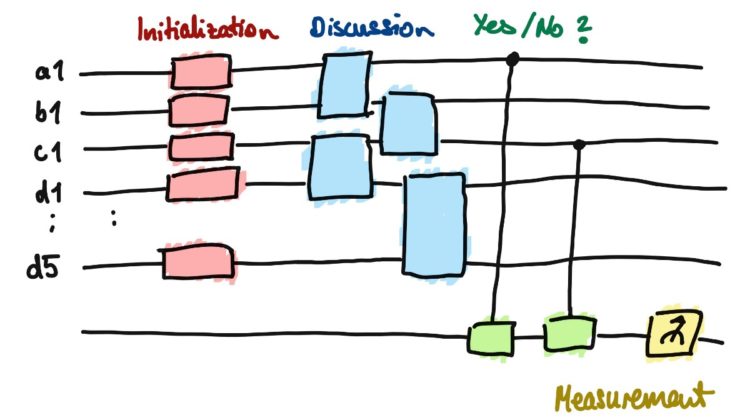
Supervised learning. We define a rather easy success metric for each legal move and train our variational quantum circuit to choose the best move, respectively. For this, we optimize the parameters which define the operations within our parametrized circuit to yield the best possible result. (We do this by an optimization technique called Gradient Descent).
Reinforcement learning. The problem with supervised learning is that the student (quantum computer) can only become as good as its teacher (quantum nerds, yes, but chess newbies as well). We want the quantum computer to be better than us. To beat us. So we can start learning from it. Thus, we let the quantum computer play a slightly modified version of itself. That way it (hopefully) never stops learning as it either loses against itself or wins. Either way, it learn to play better next time.