During my time as a consultant working in the analytics space I have had the opportunity to work on both AWS and Azure environments to implement analytic solutions.
Below is my thoughts on the similarities and differences between the two machine learning services provided by the two biggest cloud vendors (as at 10 December 2020).
Similarities
- Estimators: Model training, inference is done through the use of estimators. Under the hood they are Docker containers that are deployed to 1 or more VMs/EC2 instances to do training/inference. As a result the script that actually does the model training/ pre/post processing is quite easily migrate-able from one vendor to the other. There are, however, some slight differences.
- Deployment: Both vendors provide the option to deploy the model to API endpoints or some kind of batch transform/scoring. The endpoints seem to use a similar stack (looks like Flask and Gunicorn).
- Hyperparameter Tuning: Both vendors provide hyper-parameter tuning as a service. As at 10 December 2020 SageMaker provides Random Search and Bayesian Search. Azure Machine Learning provides Random Search, Grid Search and Bayesian Sampling.
- ML Pipelines: Both vendors enable the creation of ML pipelines to “chain” together steps that are required for an ML project. An example is a feature/data engineering step, training step, model registry step, model deployment step. How it is actually implemented by the two vendors are quite different.
Differences
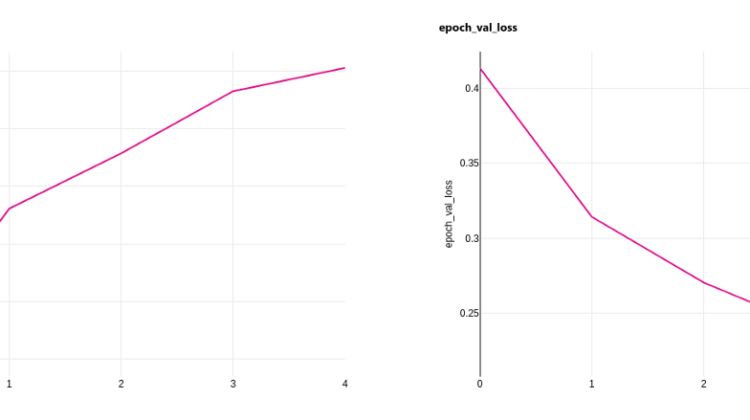
- Logging: AWS SageMaker logs model metrics to CloudWatch. Azure seems to make use of MLFlow’s logging functionality and can be called via run.log(). Overall, I found the logging of Azure to be more intuitive and easier to use and the visualisations were more appealing (looks like it is using Plotly). I found the logging to CloudWatch and the metric visualisation to be less desirable in AWS. Below is a sample visualisation of logging in Azure Machine Learning:
2. Artifact Logging: In this case I found the resources and artifacts that SageMaker logged and saved to be more easily traceable and found. It will be within a single bucket (however in potentially many different paths). Whereas, in Azure Machine Learning I was often getting confused and frustrated with all the different locations in blob that were related to a single model run.
3. Ease of Use: From my experience, I found that Azure Machine Learning was quite easy to pick up and get productive. There is an option for a drag and drop UI (which I have not used) which may simplify things further, however, at the cost of flexibility. With AWS SageMaker it requires a bit more coding, however, I like that things have been thought out in the Estimators. For example, the SM_MODEL_DIR environment variable that is available in the estimator is where to save your model artifacts which will be made available in S3 etc. In Azure Machine Learning, this needed to be done either explicitly in the training script, or via the Model Registration step. Overall, once you have the experience, SageMaker is quite flexible and customisable in my opinion.
4. Data Input: In SageMaker it is almost enforced that prior to running a training job data must be split into train, val and test in S3 (for certain algorithms/frameworks). Whereas in Azure Machine Learning, you can kind of get away and do the splitting inside the training script.
Caveats
Above is by no means a complete and exhaustive list. Just some of my thoughts based on my experience implementing algorithms and analytic solutions through the two services. Feel free to leave a comment of things I have missed out that are worth mentioning.
I am interested to see how the machine learning landscape evolves and changes over time. Google Cloud Platform is also entering this space. In a rapidly evolving field, with new services coming frequently, I cannot wait to see what new services and functionality will be provided to aid in the implementation of analytical solutions in the future.