Since their launch in November, Apple Silicon M1 Macs are showing very impressive performances in many benchmarks. These new processors are so fast that many tests compare MacBook Air or Pro to high-end desktop computers instead of staying in the laptop range. It usually does not make sense in benchmark. But here things are different as M1 is faster than most of them for only a fraction of their energy consumption.
Apple is working on an Apple Silicon native version of TensorFlow capable to benefit from the full potential of the M1. On November 18th Google has published a benchmark showing performances increase compared to previous versions of TensorFlow on Macs.
As a consequence, machine learning engineers now have very high expectations about Apple Silicon.
But we should not forget one important fact: M1 Macs starts under $1,000, so is it reasonable to compare them with $5,000 Xeon(R) Platinum processors? or to expect competing with a $2,000 Nvidia GPU ?
Setup
In this article I benchmark my M1 MacBook Air against a set of configurations I use in my day to day work for Machine Learning.
On the M1, I installed TensorFlow 2.4 under a Conda environment with many other packages like pandas, scikit-learn, numpy and JupyterLab as explained in my previous article.
This benchmark consists on a python program running a sequence of MLP, CNN and LSTM models training on Fashion MNIST¹ for three different batch size of 32, 128 and 512 samples.
It also uses a validation set to be consistent with the way most of training are performed in real life applications. Then a test set is used to evaluate the model after the training, making sure everything works well. So, the training, validation and test set sizes are respectively 50000, 10000, 10000.
Workarounds for issues with TensorFlow 2.4 0.1alpha1 on M1
Today this alpha version of TensorFlow 2.4 still have some issues and requires workarounds to make it work in some situations.
Eager mode can only work on CPU. Training on GPU requires to force the graph mode. This is performed by the following code
from tensorflow.python.compiler.mlcompute import mlcompute
from tensorflow.python.framework.ops import disable_eager_execution
disable_eager_execution()mlcompute.set_mlc_device(device_name='gpu')
print(tf.executing_eagerly())
Evaluating a trained model fails in two situations:
- In graph mode (CPU or GPU), when the batch size is different from the training batch size (raises an exception)
- In any case, for LSTM when batch size is lower than the training batch size (returns a very low accuracy in eager mode)
The solution simply consists to always set the same batch size for training and for evaluation as in the following code.
model.evaluate(test_images, test_labels, batch_size=128)
Models
The three models are quite simple and summarized below.
MLP
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=X_train.shape[1:]),
tf.keras.layers.Dense(512,activation='relu'),
tf.keras.layers.Dropout(rate=0.2),
tf.keras.layers.Dense(64,activation='relu'),
tf.keras.layers.Dense(10,activation='softmax')
])
CNN
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(32,(3,3),activation = 'relu',input_shape=X_train.shape[1:]),
tf.keras.layers.MaxPooling2D((2,2)),
tf.keras.layers.Conv2D(64,(3,3),activation = 'relu'),
tf.keras.layers.MaxPooling2D((2,2)),
tf.keras.layers.Conv2D(64,(3,3),activation = 'relu'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64,activation='relu'),
tf.keras.layers.Dense(10,activation='softmax')
])
LSTM
model = tf.keras.models.Sequential([
tf.keras.layers.LSTM(128,input_shape=X_train.shape[1:]),
tf.keras.layers.Dense(10,activation='softmax')
])
They are all using the following optimizer and loss function.
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
Fashion MNIST from tf.keras.dataset has integer labels, so instead of converting them to one hot tensors, I directly use a sparse categorical cross entropy loss function.
Results
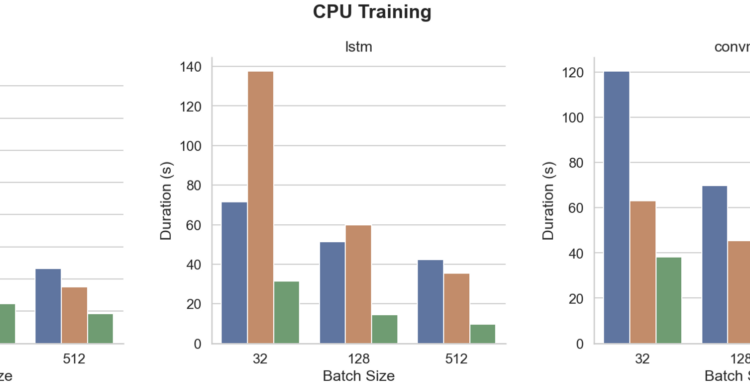
The following plots shows the results for trainings on CPU.
In CPU training, the MacBook Air M1 exceed the performances of the 8 cores Intel(R) Xeon(R) Platinum instance and iMac 27″ in any situation.
The following plot shows how many times other devices are slower than M1 CPU.
For MLP and LSTM M1 is about 2 to 4 times faster than iMac 27″ Core i5 and 8 cores Xeon(R) Platinum instance. For CNN, M1 is roughly 1.5 times faster.
Here are the results for M1 GPU compared to Nvidia Tesla K80 and T4.
In GPU training the situation is very different as the M1 is much slower than the two GPUs except in one case for a convnet trained on K80 with a batch size of 32.
The following plot shows how many times other devices are faster than M1 CPU (to make it more readable I inverted the representation compared to the similar previous plot for CPU).
Here K80 and T4 instances are much faster than M1 GPU in nearly all the situations. The difference even increases with the batch size. K80 is about 2 to 8 times faster than M1 while T4 is 3 to 13 times faster depending on the case.
So does the M1 GPU is really used when we force it in graph mode ?
The answer is Yes. When looking at the GPU usage on M1 while training, the history shows a 70% to 100% GPU load average while CPU never exceeds 20% to 30% on some cores only.
Now we should not forget that M1 is an integrated 8 GPU cores with 128 execution units for 2.6 TFlops (FP32) while a T4 has 2 560 Cuda Cores for 8.1 TFlops (FP32). The price is also not the same at all.
We should wait Apple to complete its ML Compute integration to TensorFlow before drawing conclusions but even if we can get some improvements in the near future there is only a very little chance for M1 to compete with such high-end cards. But we can fairly expect the next Apple Silicon processors to reduce this gap.
An interesting fact when doing these tests is that training on GPU is nearly always much slower than training on CPU. The following plots shows these differences for each case.
As we observe here, training on the CPU is much faster than on GPU for MLP and LSTM while on CNN, starting from 128 samples batch size the GPU is slightly faster.
The last two plots compare training on M1 CPU with K80 and T4 GPUs.
Conclusion
From these tests it appears that
- for training MLP, M1 CPU is the best option
- for training LSTM, M1 CPU is a very good option, beating a K80 and only 2 times slower than a T4, which is not that bad considering the power and price of this high-end card
- for training CNN, M1 can be used as a descent alternative to a K80 with only a factor 2 to 3 but a T4 is still much faster
Of course, these metrics can only be considered for similar neural network types and depths as used in this test.
As a machine learning engineer, for my day-to-day personal research, using TensorFlow on my MacBook Air M1 is really a very good option.
My research mostly focuses on structured data and time series, so even if I sometimes use CNN 1D units, most of the models I create are based on Dense, GRU or LSTM units so M1 is clearly the best overall option for me.
For people working mostly with convnet, Apple Silicon M1 is not convincing at the moment, so a dedicated GPU is still the way to go.
Apple is still working on ML Compute integration to TensorFlow. If any new release shows a significant performance increase at some point, I will update this article accordingly.
Thank you for reading.
Sources
[1] Han Xiao and Kashif Rasul and Roland Vollgraf, Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms (2017)