Note From Author:
This tutorial is the foundation of computer vision delivered as “Lesson 8” of the series, there are more Lessons upcoming which would talk to the extend of building your own deep learning based computer vision projects. You can find the complete syllabus and table of content here
Target Audience : Final year College Students, New to Data Science Career, IT employees who wants to switch to data science Career .
Takeaway : Main takeaway from this article :
- Logistic Regression
- Approaching Logistic Regression with Neural Network mindset
Logistic Regression is an algorithm for binary classification. In a binary classification problem the input (X) will be a feature vector of 1-D dimension and the output (Y) label will be a 1 or 0
The logistic regression output label lies between the range 0 and 1 .
0 ≤ Y ≤ 1, where Y is the probability of the output label being 1 given the input X
Y = P(y=1 | x) For a learning algorithm to find Y it takes two parameters W and B. Where, W is the weight associated with the input feature vector X and B bias.
To find Y . Well, one thing you could try that doesn’t work would be to have Y be w transpose X plus B, kind of a linear function of the input X. And in fact, this is what you use if you were doing linear regression. As shown below.
But this isn’t a very good algorithm for binary classification
Because you want Y to be the chance that y is equal to one Y = P(y=1 | x). So Y should really be between zero and one and it’s difficult to enforce that because W transpose X plus B can be much bigger than one or it can even be negative, which doesn’t make sense for probability. That you want it to be between zero and one.
So in logistic regression, our output is instead going to be Y equals the sigmoid function applied to this quantity.
σ is the Sigmoid function to which we pass the quantity w^T X+B
A sigmoid function would look like this,
If , Z is very large σ(z) = 1/1+0 = 1
If, Z is very small (large negative number) σ(z) = 1/1+big number = 0
where Z is the quantity w^T X+B
The loss function is given by
L(Y , y) = −y log(Y)−(1−y)log(1−Y)
Where, Y — predicted label to the y — ground truth label that comes along with the training data-set.
The loss function measures how well you’re doing on a single training example.
The cost function is given by
Which measures how well you’re doing an entire training set. So in training your logistic regression model. we’re going to try to find parameters W and B that minimize the overall costs function J .
So, you’ve just seen the set up for the logistic regression algorithm, the loss function for training example and the overall cost function for the parameters of your algorithm.
It turns out that logistic regression can be viewed as a very very small neural network.
Our goal is to find the values of parameter W that make our classifier as accurate as possible; and in order to find appropriate values of parameter W, we’ll need to apply gradient ascent/descent.
Derivative or Slope
Before understanding the gradient descent, lets try to understand what an derivative is.
Derivative means slope
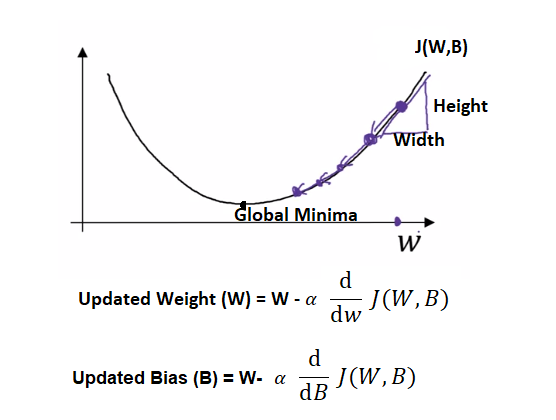
From the high school math we learnt, we understand Slope = Height/Width
Lets take a simple function f(a)=3a of a straight line as shown below
For a = 2, f(a) = 3(2) = 6 | for a=2.001 , f(a) = 3(2.001) = 6.003
Therefore, the slope / derivative of a function for straight line is height/width = 0.003/00.001 = 3. Given by,
The derivative of the function just means the slope of a function and the slope of a function can be different at different points on the function. In our first example where f(a) = 3a those a straight line. The derivative was the same everywhere, it was three everywhere.
Similarly, lets take a complex function f(a) = a² where the slope of the function can be different to different points in the function unlike the above straight line function.
For other functions like f(a) = a² or f(a) = log(a), the slope of the line varies. So, the slope or the derivative can be different at different points on the curve.
Gradient Descent
Gradient ascent and descent are very simple first-order optimization algorithms based on the derivative of an optimization function. We use gradient ascent and descent to find the local minimum/maximum of a function.
So in order to learn the set of parameters W and B it seems natural that we want to find W and B that make the cost function J(W, B) as small as possible.
In other words, with gradient descent we minimize the over all cost function J(W,B) by moving towards the global minima in a convex function. The slope towards the global minima is obtained by taking the derivative of the cost function ⅆ/ⅆw J(W,B)
So to find a good value for the parameters, we initialize W and B to some initial value, for logistic regression almost any initialization method works,usually you initialize the value to zero. But because this function is convex, no matter where you initialize, you should get to the same point or roughly the same point. And what gradient descent does is it starts at that initial point and then takes a step in the steepest downhill direction. So after one step of gradient descent you might end up towards global minima downhill as shown in the PIC above, because it’s trying to take a step downhill in the direction of steepest descent or as quickly downhill as possible. So that’s one iteration of gradient descent. And after two iterations of gradient descent you might step further towards the global minima, three iterations and so on.
This step of updating the weight and bias happens in an iterative way until the point of convergence occurs or the global minima is reached from the initial values of W and B.
The whole of factor of moving towards the global minima is driven by alpha α the learning rate, it controls how big a step we take on each iteration or gradient descent.
In this exercise, you will build a Logistic Regression, using a Neural Network mindset. The following Figure explains why Logistic Regression is actually a very simple Neural Network!
The main steps for building a Neural Network are:
- Initialize the model’s parameters W and B
- Loop: Forward and Backward propagation
- Calculate current loss (forward propagation) L
- Calculate current gradient (backward propagation) J
- Update parameters (gradient descent) θ
3. Use the learned (w,b) to predict the labels for a given set of examples
Step 1:
Initialize parameters W and B manually.
W -- initialized vector of shape (dim, 1)
B -- initialized scalar (corresponds to the bias)
Step 2:
Forward Propagation , Backward Propagation and Optimization
We obtain the cost J(W, B) and gradient of loss with respect to W and B by using the below formulas for forward propagation and backward propagation
# compute cost (Forward Propagation)
cost = -(1/m) * np.sum(Y.T * np.log(A) + (1 - Y.T) * (np.log(1-A)) )#where A is the sigmoid Activation ,A = sigmoid(np.dot(X.T,w) + b)#Gradients of loss with respect to W and B:(Backward Propagation)dw = (1/m) * np.dot(X,(A-Y.T))db = (1/m) * np.sum(A-Y.T)
The goal is to learn W and B by minimizing the cost function J. For a parameter θ, the update rule is
where alpha is the learning rate
Optimization is finding the updated parameter of W and B after minimizing the cost function J by applying the update rule.
W = W- learning_rate * dw
B = B- learning_rate * db
Step 3:
Use the learned (w,b) to predict the labels for a given set of input examples. Process of computing the cost , gradient and updated parameter by gradient descent for a set of input examples is called iteration or epoch. Typically we run such step for multiple epochs or iterations to obtain the desired result.
For a learning rate alpha of 0.005, you can see the cost decreasing. It shows that the parameters are being learned. However, you see that you could train the model even more on the training set. By increasing the number of iterations you might see that the training set accuracy goes up, but the test set accuracy goes down. This is called overfitting.
In order for Gradient Descent to work you must choose the learning rate wisely. The learning rate alpha determines how rapidly we update the parameters. If the learning rate is too large we may “overshoot” the optimal value. Similarly, if it is too small we will need too many iterations to converge to the best values. That’s why it is crucial to use a well-tuned learning rate.
Logistic Regression is a simple Neural Network. The main objective of a Logistic regression algorithm is to find the updated parameters by minimizing the cost function J, where cost function J measures how well you’re doing an entire training set.
Logistic Regression undergoes 3 steps, first we initialize parameters W and B as zeros. Next we compute cost of the entire training set (J) and obtain derivatives of parameters dw and db which is nothing but the gradient of loss with respect to W and B. Finally we apply update rule to minimize the cost function and obtain the updated parameters.
We repeat this process of updating parameters W and B for multiple iterations or epochs by taking the updated parameters from previous iterations or epochs as initial parameters in the current epochs.