Much has been written about the transforming potential of Data Science Platforms. The optimists claim they are the disruption that will fully unlock the value of data science and turn everyone into budding citizen data scientists, the pessimist strike back saying that they are harbingers of doom and will unleash untold misery in the form of poorly designed machine learning models running around spreading bad results.
The truth lies somewhere in the middle but, in my opinion, much closer to the optimists.
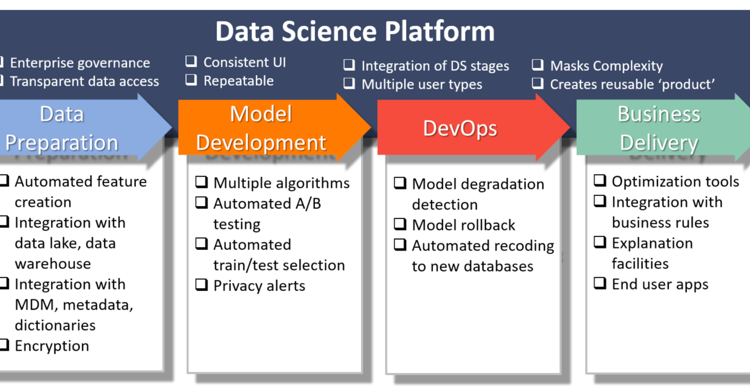
Data science platforms are software products that bring together all the required tools to perform Data science tasks. These can include but are not limited to the following functionalities:
· Data ingestion — How can I get access to the data?
· Data preparation — How can I process the data into something I can work with?
· Data exploration — What does the data show at first glance?
· Model building — How can I create a model?
· Model Deployment — How can I use my model in production?
You can see below an explanatory diagram with some of the available functionalities (taken from https://www.eckerson.com/articles/what-is-a-data-science-platform)
Data science platforms usually provide two interfaces, one based on code and another based on point&click or drag&drop.
The first one is usually richer and better fitted for the more experienced users who are willing to face more complexity in trade for more flexibility and freedom. The second one is usually targeted to less knowledgeable data scientists, who are OK with using a more standardized approach if they can take advantage of pre-built blocks that they can use without having to start from scratch. This last interface is also useful for the experts as it allows them to “outsource” the boring tasks of data science (e.g. data cleaning) to the platform with a couple of clicks and focus more on the key aspects of the problems (where their expertise generates more value)
Most of these platforms offer some form of Automated Data Science, where the platform itself can choose the best model, fit it with good parameters and provide an end model that can easily by deployed. All at the distance of one click (actually, usually it takes more than just a click but you get the point).
The market for data science platforms is very dynamic. You have large players like Microsoft and IBM and smaller more nimble competitors like Dataiku and H20.ai. As you can see in Gartner’s Magic Quadrant below (which I took from this great blog — https://www.kdnuggets.com/2018/02/gartner-2018-mq-data-science-machine-learning-changes.html — by Gregory Piatetsky , from 2017 to 2018 there have been a lot of changes. Companies are vying for the top spot because the market is approaching the stage where a couple of tools will explode and, by quickly exploring network effects, corner a large piece of market share. This means that new features are continuously being added and new functionalities are being built into the existing tools.
So, at first sight this seems amazing.
We have a tool that not only comes with everything that a data scientist can actually need to build and deploy their solution but that can also be used by both an expert and a rookie without any issue. These solutions are improving every day and seem to offer more and more every time you open them.
Detractors of these platforms say these tools can be dangerous on the hands of the inexperienced. By making it so easy to build and deploy models, these may lead people to think that they don’t have to worry about the details.
They state that this will just remove the science from “Data Science”:
· Why try to understand the problem if the platform can practically do it by itself?
· Why look into the data if the platform can clean it and pre-process it automatically
· Why look into models if it can choose the one that fits the best?
Why not treat data science like a massive black box and only deal with the results that the platform gives us?
This is, indeed, very dangerous. Data science is much more than coding. in fact, coding should be considered a necessary evil in data science. Without a clear picture of the problem, it’s very tricky to build an effective solution. Without understanding how the solution will be deployed, it is easy to let in data leaks (where data that the model won’t be able to see in production is used while in training) and that is halfway into disaster.
Take this example:
Imagine that we work for a company that sells shoes on their department stores.
We receive, at the end of the day, data with how many shoes were sold every hour during the day at each of our stores. We want to build a model to forecast how many shoes will be sold at each particular hour so that we can centrally let our stores know how to prepare.
We place all our data into the platform and we realize something interesting. The shoes we sell at hour X have a deep correlation with the shoes we sell at hour X-1 and X-2. This is great! Our model provides super good results when we use the last couple of hours as variables and seems to be able to forecast the correct amount almost to the unit! We make a couple of clicks and the model is in production. We just solved a major issue!
Obviously, this won’t work. The issue here is that, at hour X, I don’t have the records at hour X-1 and X-2, I only get them at the end of the day! I can’t use them to forecast for the following hour. We have just seen how data leaks work. We have provided the model with data it will not have during production. The model we built is useless.
This problem is a bit contrived, of course. But it is illustrative. Without proper care and attention, we can easily build a solution that does not give good results and that can actually cause harm.
You may say, of course, that a real data scientist would not make this mistake. But this is the actual point that the pessimists are making. These platforms open the gates to everyone that wants to join, some of these people may or may not have a previous experience with data science, they can easily build models that are based on false assumptions and release them into the world spreading mayhem.
These concerns are valid but, in the end, I think they are a symptom of looking at the issue from a misguided perspective.
Want it or not the platforms are here to stay. The Pandora box has been opened and there is no way it is getting closed again. More, the platforms are here, and they clearly answer a market need. Society in general needs more people to be able to work with data and most people don’t have the time or skills to become full-fledged data scientists. Arguing against a solution that clearly provides results and offers value never works in the long run.
When Kodak stumbled into the digital camera and decided to burry it in order to preserve its existing photo development business it made a critical mistake that ended up practically burying the entire company for good. Other companies got to the digital machine later, developed the solution, sold it and all but ran Kodak out of the photo market value chain.
The fight will not be against the coming of the platforms but for their correct use. And in this, the experienced data scientists can be of great assistance. By helping spread good habits and sharing best practices, data scientists can help mold a new generation of practitioners that will help institutions extract more value from their data.
By positioning themselves not as luddites but as promoters of these solutions they can not only cement their position as key elements in analytics initiatives but also make sure that things are done as they should be done. These platforms are not a risk for the data scientist profession, they are a gift that will empower these professionals and help them bring even more value to the table.
The Verdict? Definitely FRIENDS.