In this article, I will try to demystify the concept of Ensemble Learning. People familiar with Machine Learning will have heard of a very popular algorithm called Random Forest, which is an example of ensemble learning. I will try to provide examples and with the help of them, we will build up the basics of ensemble learning, ending by discussing a few algorithms.
So, what does the word ensemble mean? According to google, ensemble is defined as a “group of items viewed as a whole rather than individually” . The definition is quite self explanatory, but for the purpose of Machine Learning, we will look at an example.
Say you want to learn Machine Learning. You have two resources, a book and a video based course. Both of the resources are good in their own right. You have a decision to make here but as you are a beginner, you don’t know which resource to pick. So, you ask a professor from your University about it. He tells you to take the course. Similarly, you ask a friend of yours and he prefers the book. In the same manner you asked, say 15 people and different people have different opinions. You will also have a choice.
The example isn’t complete yet, but let us correlate it with Machine Learning. It is clear that this is a classification problem with the target variable having one of the two choices Book or Course. Let us think of each of the people you asked as Machine Learning models from M1 through M15 . Each model Mi will have an output, which corresponds to the choices of the people. Now, say the 5th person or model M5 is the one you trust blindfolded and you choose the resource which he had chosen. So, in that case you would choose based on one model only.
What you could do differently is you could take the output or decisions of each of the 15 Machine Learning models and somehow try to summarize them and finally make a decision yourself, taking into account those 15 outputs. And that is what ensemble learning is at its core. Your goal is to make the best decision. So, let’s say when you are making a decision based on multiple outputs, you are becoming a stronger decision maker in that field with respect to the other 15 decision makers. So, you will be called the strong learner while the 15 models you took inspiration from will be called weak or base learners.
What is the workflow then? First the weak or base learners give their outputs. Then, the strong learner aims at making a prediction based on the outputs of the weak learners. Finally, the strong learner gives its output.
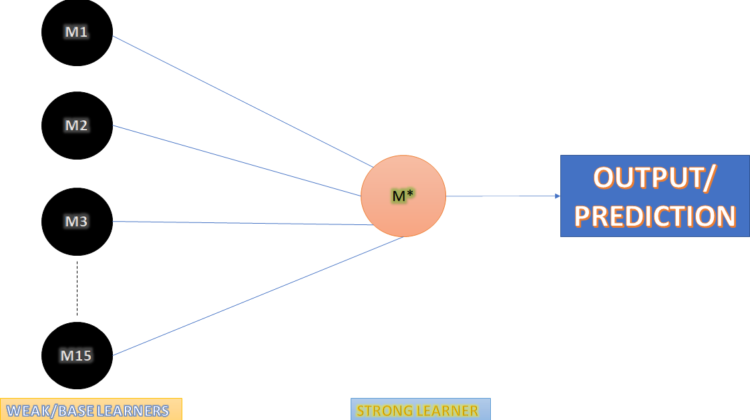
So, let’s get technical with Ensemble Learning. Below is a diagram which explains the concept of Ensemble learning. Now that you know what base learners and strong learners are, we can move ahead. So, take a look at the picture below. On the left is a stack of circles, labelled as base learners. These are the 15 models you will take the output from. The blue lines show that the outputs are being received by the circle on the right, which is the strong learner. Finally, the strong learner makes a prediction. One important thing to note here is that the dataset is shown to each and every model, including the strong learner.
So, why Ensemble Learning? And when do I use Ensemble Learning? In the process of answering when, we will get an answer to why. So, firstly, in our daily life, if we ask a question to more than one person, we get different perspectives which help us to answer that question ourselves better. If we ask only one person, we will get only one viewpoint. So, usually, we can say that getting more perspectives gives us a wider view and is generally better. Similarly, using the results of several models is better than using the results of one model, especially when the models have lower accuracy then expected. In that case, ensemble learning can combine the models to create a new model which will have a higher accuracy. Ensemble learning basically follows either of the two principles or both — “Unity in diversity” and “Unity is strength”.
You might think why do we have to use weak learners and not strong learners from the beginning? Well, the thing about weak learners is that, in layman terms, they are sure about a particular part of the problem we are aiming to solve. So, it will be fair to say that they have low variance and high bias. Hence, they don’t overfit the training data. A strong base learner on the other hand might overfit the data, which will lead to worse performance on any metric in the testing phase. So, to avoid this problem we use weak learners as base learners.