what are all dimesion reduction techniques ,why do we need those technique..??
Dimensionality Reduction-according to Wikipedia Dimension reduction is the transformation of data from a high-dimensional space into a low-dimensional space so that the low-dimensional representation retains some meaningful properties of the original data.
According to a study, by 2020, it’s estimated that 1.7MB of data will be created every second for every person on earth.few of the data collection methods mentioned below:
1.Social media collects data of what you like, share, post, places you visit, restaurants you like, etc.
2. Smartphone apps collect a lot of personal information about you.
3. E-commerce site collects data of what you buy, view, click, etc.
As data generation and collection keeps increasing, visualizing it becomes more and more challenging. One of the most common ways of doing visualization is through charts(with limited features)
let’s consoder a case where we do have 10000 Variable we can have 10000(10000 –1)/2=49995000 different plot, there is no meanings to visualize each of them separately, better to select a subset of these variables which captures as much information as the original set of variables.
Why is Dimension Reduction technique required?
1. Less dimensions lead to less computation/training time.
2. Some algorithms do not perform well when we have a large dimensions.
3. Less chance that multicollinearity can occurs.
4. Helps in visualizing data.
Few Dimension reduction technique listed below:
1. Missing Values Ratio
2. Low Variance Filter
3. High Correlation Filter
4. Random Forests/Ensemble Trees
5. Backward Feature Elimination
6. Forward Feature Construction
7. Principal Component Analysis (PCA)
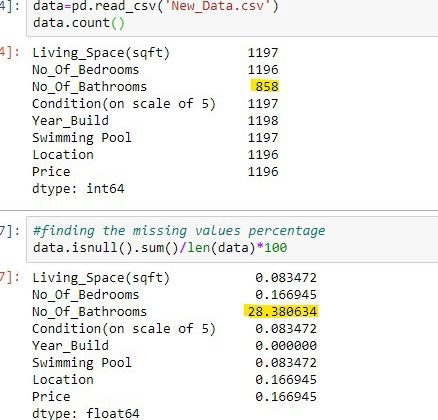
Missing Value Ratio: In a dataset, if a column with many missing values is unlikely to contain much useful information, if data columns with more missing values than a specified threshold can be dropped. The higher the threshold, the more aggressive the decline.
As you can see in the screenshot above, there is only one variable that has more than 20% missing values. Now should we assign the missing values or discard the variable (column)? I would discard this variable. We can set a threshold, and if the percentage of missing values in any variable exceeds that threshold, we’ll discard the variable.
Low Variance Filter: As with the missing ratio, data columns with small changes in the data provide little information. Therefore, it is necessary to remove all data columns with variance below the specified threshold.
Now you can see in the screenshot above that the variance of “Condition (on a scale of 5)” is less compared to the other variables, so now we can remove this column as part of the dimensionality reduction technique.
High Correlation Filter:A high correlation between the two variables means that they have similar trends and are likely to contain similar information. This can impact the ( decrease) performance of some models and also cause of multicollinearity. We can calculate the correlation between independent numerical variables that are numerical in nature. If the correlation coefficient crosses a certain threshold value, we can discard one of the variables.
Note: In general, we should keep those variables that show a decent or high correlation with the target variable.
As you can see in the screenshot above, there are no highly correlated variables in our dataset.
Note: If the correlation between a pair of variables is greater than 0.7–0.8, we must seriously consider.
Random Forests/Ensemble Trees:One of the approach to dimensionality reduction is to create a large and carefully constructed set of trees for the target attribute and then use usage statistics for each attribute to find the most informative subset of characteristics. In particular, we can generate a large set (1000) of very small trees (2 levels), with each tree learning a small part of the total number of attributes. If an attribute is often chosen as the best partition, a score calculated from the statistics on the attribute’s usage in a random forest tells us, relative to other attributes, which attributes are the most predictable.
Random Forest comes with a built-in feature importance, so no external programming is necessary.
Note: if we have categorical data, we need to convert the data to numeric by applying one hot encoding, get_dummies, etc.
Based on the graph above, we can select the top-most important functions to reduce dimension in our dataset.
Backward Feature Elimination: In this method, in a given iteration, the selected classification algorithm is trained on n input attributes, then, we remove one input function at a time and train the same model on n-1 input attributes n times,input function whose removal resulted in the smallest increase in the error rate is removed, leaving us with n-1 input functions. Then the classification is repeated using n-2 attributes and so on. Each iteration k creates a model trained in n-k functions and an error rate error(k).Select the maximum tolerable error rate.
Forward Feature Construction: This method is the opposite of Backward feature Elimination. Initially, we start with just 1 function, gradually adding one function at a time, that is, the function that provides the greatest performance gain.
in the above screenshot we will get to know the top most variables based on the forward feature selection algorithm.
Note : Both Backward Feature Elimination and Forward Feature Selection are time consuming and computationally expensive
For “Principal Component Analysis (PCA)” topics please follow my next post.