In the last article, we evaluated Kalman filters as a tool to reduce the flood of sensor data and mollify data disparity to generate an accurate depiction of the autonomous vehicle’s (AV) environment. Likewise, we surveyed perception based machine learning algorithms that drive the decision making processes within an AV. Check out the previous article here!
The landscape of the automotive industry is changing. With consumers having a multitude of IoT devices readily available, car companies must be prepared to adapt to the modern consumer to remain competitive. But how can a car manufacturer manage and leverage the oceans of data AVs continuously generate? While a single AV is capable of ingesting its environment and making decisions, car companies must be able to efficiently connect these cars to elevate the consumer experience. More AVs on the road means more data. With a connected infrastructure, car companies can maintain and update the decision making models and effectively handle the data each AV creates at a larger scale.
Generating data is easy, but managing this data is much more demanding. With AVs predicted to generate 40 terabytes of data every eight hours, uploading and processing this data requires an advanced architecture platform. In a study by Elektrobit, it took 30 connected cars, generating roughly 20 terabytes of data each in a single test, 85 days (@1GB/s on a standard network connection) to upload their sensor data to the cloud. In a week these test vehicles can produce 4.2 petabytes of data and take years to upload. Not to mention that a single break in the connection will mean that this process would have to start over. Conventional architectures are simply not capable of uploading this amount of data quickly and this leaves absolutely zero room for data redundancies. Additionally, to build and maintain the computationally intensive algorithms in this fashion requires much more capable processing centers. Managing the data generated by a fleet of AVs can quickly become outrageously expensive and cloud computing platforms are not currently available everywhere a traditional vehicle can go. Conventional machine learning techniques simply do not cut it and training models will be afflicted by long upload and deployment times.
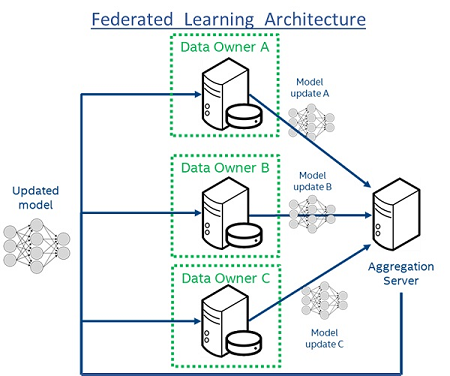
Instead of centralizing the data in a single data center for model training, most AV applications will have to turn to a federated approach to decentralize model training and compute at the edge (i.e. on board the AV). Federating learning works in iterations and the models act as both the input and the output. Taking a base algorithm (in the first iteration), each AV can fit the model to the training data they generate themselves. After so many iterations, the models from the entire fleet are sent to the master model location. Typically the master model resides in a centralized cloud provider. After the data is labeled, it is added to the training set and a new model is trained. With this new model, the process restarts and the updated model is pushed back into the autonomous vehicle. By doing so, the initial models can learn and adapt on the local data samples that are readily available to them without sharing data. After the models are combined, the updated model is fed back into the AVs and the process repeats. This can easily outperform traditional machine learning techniques and decouple’s AV’s dependencies on a network connection. By sharing model parameters instead of data, federated learning systems are not bogged down by upload times, given that a model will be at most a few megabytes.
Properly orchestrating model updates to the master model is a crucial step in federated learning. Transferring model parameters across an entire fleet requires a stable and reliable messaging system that can ensure data privacy at a high performance. The communication system handling model parameters must be robust to avoid data lost. Every parameter is vital to updating the model and parameter transmissions must be stable enough to transfer accurate data. A loss in data can affect the entire performance of the driving algorithm and create gaps in certain environments. Additionally, the communication model needs to be quick and efficient with high throughput and low latency. These updates are very similar to vehicle recalls. If you have a system running on a faulty model, the car company must quickly deploy a new updated model to ensure passenger safety. Furthermore, the location of the consumer must remain autonomous. Although most transmitted data is encrypted, using a public network to update a vehicle can put the consumer at risk of attack. The communication model must not jeopardize the safety and privacy of the consumer. At scale, these constraints need to be diligently supervised with no break in service.
To support the federated learning algorithms in an AV application, Pandio is a highly capable contender. Developed with Apache Pulsar as the core messaging framework, Pandio is an extremely scalable event streaming platform. Pandio can quickly and efficiently handle all the iterations within a federated learning application. Additionally, Pandio uses Pulsar’s layered architecture to decouple compute from storage, which makes the platform highly tolerable to scaling and outstandingly stable and reliable. Pandio is designed to process trillions of events per day.
To improve system availability, Pulsar separates brokers from bookies. This allows independent scalability and deepens the fault tolerance of the systems. Paired with Apache BookKeeper, Pulsar ensures zero data loss at a significantly higher throughput. Thus Pandio is a secure and reliable platform to handle model transmissions in all the iterations accompanying federated learning. Furthermore, Pandio’s scalability is a product of Pulsar’s segment-based storage architecture. By cutting the topic into small fragments, the platform can easily scale out with an exceptionally high throughput and by incorporating data authentication, data privacy is guaranteed in the parameter transmissions.
With all the aforementioned features, Pandio can effectively handle your federated learning needs. Do you have an AV application that needs support at scale? Lets talk.