The following report was for my individual project for a Data Science course in the Masters of Quantitative Management program at Duke University. The accompanying R code can be viewed at https://github.com/malikamohan01/significant-police-factors-r/blob/main/codeappendix.
In order for stakeholders like activism groups and local policymakers to make the most change in the quickest and most effective manner in response to these calls, the following data analysis and report strive to answer a few questions that will enable this.
Firstly, where are these incidents happening the most? This will help activist groups like Black Lives Matter and Color of Change focus their efforts as opposed to a vague/broad call for defunding across the U.S. Secondly, what are the significant factors of areas of higher incidents? And lastly, can we predict what factors may lead to a higher likelihood of an incident happening? These latter two questions will help arm policymakers to best respond to activist call-for-changes by understanding the factors that best explain and predict a police shooting incident, and inform stronger policies and trainings in response.
Two datasets were used in order to answer the proposed questions. Firstly, a dataset was obtained from Kaggle on police records in the U.S. of shootings that occurred over the past five years. There were 4851 records and included the following variables: Date, Manner of Death (how victim died), Age (age of victim), Gender (M/F), Race, City, State, Signs of Mental Illness (true/false if mental illness signs present in victim), Threat Level (attack/other), Flee (if victim fleeing scene or not), and Body Camera (true/false if officer wearing body camera at time of incident). A limitation to this dataset may be if not a thorough set of data was collected or if the researcher creating this dataset missed something when collecting data from Bureau of Justice websites.
The second dataset was obtained by combining the counts of incidents per state with state-level government data such as the State, Count of Incidents, Pop Size, Pct of Incidents per Pop, Pct White (% of state population that is Non-Hispanic White), Poverty Rate, Median HH Income, Party Leaning 2020 (Democrat/Republican), Police Spending Per Capita and Median Age. These two datasets were merged into a comprehensive dataset describing specific police-shooting incidents and explanatory data about the state that they are occurring in.
Data Cleaning: The process of data cleaning encompassed standardizing date formats, renaming columns that had strange characters in them (eg. state was initially ï..State), fixing typos and inconsistencies in the data (e.g. all of the ‘37’’s in the age column had extra decimals following the number that the other ages did not), and checking for no null values in the columns. The next step was the data merging between datasets, using the merge function to join them on the code of State.
Data Exploration: The data exploration process started with 1-D analysis on the variables in order to better understand the distribution of them before getting started by creating histograms. Some of the key insights about the incidents included that the majority of police shooting incidents involved the officer not having a body camera, that there were not frequently signs of mental illness which was surprising as that is what some police training suggestions typically surround, that the gender of victims was overwhelmingly male and that the distribution of age is left skewed with the mean at 36.5 (Figure 1).
Figure 1:
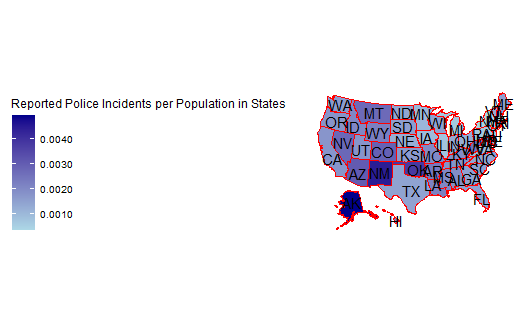
Next, alongside histograms for the rest of the variables, for two-dimension analysis, maps of the state-based counts helped to better understand these variables and states that should be focused on. We initially see that there are higher counts in states like California and Texas and lower counts in Midwest states (Figure 2a), however, after we see similar patterns in the population size map (Figure 2b) indicating to us that we should evaluate the percent of incidents per population in order to standardize it. After doing this, we see that the states with the highest frequency of shootings are: Alaska, New Mexico, Oklahoma, Arizona, Colorado, Nevada, Montana, West Virginia, Arkansas, and Wyoming (Figure 2c). Additional insights can be derived from maps on the % of a state that is white, with the ones with the largest white population including Louisiana, Utah, West Virginia, Nevada and North Carolina, the state poverty rate (highest poverty rate states include Mississippi, New Mexico, Louisiana, West Virginia and lowest include New Hampshire, Maryland and Utah), and police spending per capita (Figure 2d).
2a:
2b:
2c:
2d:
Police spending per capita is important to hone in on, and we can see that the states with the highest police spending per capita include DC, New York, Alaska, Maryland, Rhode Island, and Nevada and lowest include Maine, Indiana and Kentucky. On average, states spend $311 per capita towards their police budget (Figure 3). Something important to take note of and that was kept in mind before progressing to the modeling step is that police spending per capita and the count of incidents are not normally distributed (Figure 4), so suggested the need for it to be transformed.
Figure 3 & 4:
Next, interactions and correlations between these two types of data (state and incident-related data) were explored via a correlation matrix, boxplots, scatterplots, chi-squared testing for independence and interaction plots. The correlation matrix (Figure 5) among the numeric variables showed us that the strongest correlations of incidents were positives ones with population size (0.89), poverty rate (0.21), and police spending per capita (0.08) and negative ones with median HH income (-0.08), median age (-0.17) and percent white (-0.26).
Figure 5:
As correlation itself is not a strong enough indicator of a relationship, next Chi-Squared tests for independence were conducted in order to evaluate if a relationship exists between the variables in the population. The results showed us that statistically significant relationships (p value < 0.05) included the relationship between incidents and race, age, signs of mental illness, flee, body camera, state pct white, state poverty rate, state party leaning and police spending per capita, positioning them as potential variables for our model. The boxplots below help us understand these relationships, like for example we can see there’s the highest count of Black and Hispanic victims and a higher count in Republican states (Figure 6a). We also visualized the relationship between pct white/count as negative, poverty rate/count as positive, and police spending/count as positive when seeing the scatter plot.
Figure 6a & 6b:
Based on the correlation matrix and chi squared tests, interaction effects (when one regressor depends on another regressor) were also considered and plotted using the interact_plot function of R and we can see that slight interaction effects exist between a state’s poverty rate/median HH income, median HH income/police spending and pct of counts per pop/poverty rate (Figure 7).
Figure 7:
Data Transformation: As we saw earlier, the target variable of police shooting incidents was not normally distributed, so evaluating what transformation would normalize it was necessary before advancing to the modeling step of the analysis. This was done via boxcox, which computes the optimal power transformation. This gave us the optimal_lambda value of 0.58 which indicates that square root would be the best transformation to use (Figure 8).
Model 1: The first model was created using the most highly correlated variables that were also found to be statistically significant in the Chi-Squared test. These were poverty rate, police spending per capita, median hh income, pct white, race, age, body camera and party leaning that were used as the regressors against the target variable of sqrt(incidents) in a linear regression lm model. Cross validation was also conducted on the model, using the traincontrol and “cv” functions in R, in order to test it. We saw that nearly all the variables were significant except for body camera so eliminated that in order to get the following:
Model 2: The second model was a lasso model, which is a regression analysis method that compares all possible choices of variables, standardizes them and performs variable selection and regularization to make the prediction accuracy better. This was done wielding the cv.glmnet function in R and evaluating the lambda coefficients, to get the following. We see there are less variables than Model 1.
Model 3: Next we used a ridge regression which is similar to lasso but that makes coefficients 0 compared to ridge which does not (works best if there are a large amount of parameters), and is helpful for data with multicollinearity, which may be applicable here as we saw via our interaction effects, by adding a degree of bias to the regression estimates and again performed cross-validation. This produced the following:
Model 4: The last model created was a random forest model which used 500 regression trees with different randomly selected 3 variables on different randomly selected samples/subsets of the data in order to train and test it, and averages the outputs of all the trees to output a predicted continuous value. The model outputs the following important predictors by showing the sum of them over the number of splits (different trees) conducted that include the features. We see these variables and their node purity below, showing us that with the larger range of values, impurity is higher (Figure 9).
In order to evaluate which model would be the most useful for predictive analysis, the metrics that can be compared across them are the R-squared (represents the proportion of variance for a dependent variable that is explained by variables within the regression model so the higher the better), RMSE (standard deviation of the residuals/prediction errors so the lower the better) and MAE (sum of absolute differences between target and predicted variables so the lower the better). Also, a point of consideration is that Model 1 includes 7 predictors, 2 includes 9 and 3 includes 11. The comparison of these metrics across the four models can be seen in the figure (Figure 10).
Based on this comparison, we can see that the random forest (Model 4) has the highest r-squared however as it is significantly higher than the others this may be cause for concern and a red flag for potential overfitting. Model 3, or the ridge regression, has the next highest r-squared as well as has the lowest error terms (RMSE and MAE). Due to this, we’d likely want to deploy model 3 or utilize ensemble learning (combining multiple prediction models to outperform any single model), to train and run both model 3 and the random forest and average the individual models predictions. Additionally, however, as a result of all the models we can have higher confidence that the variables that continued to occur across the different models — pct white, police spending per capita, poverty rate, median HH income, party leaning, race, and armed are significant predictors in police shootings.