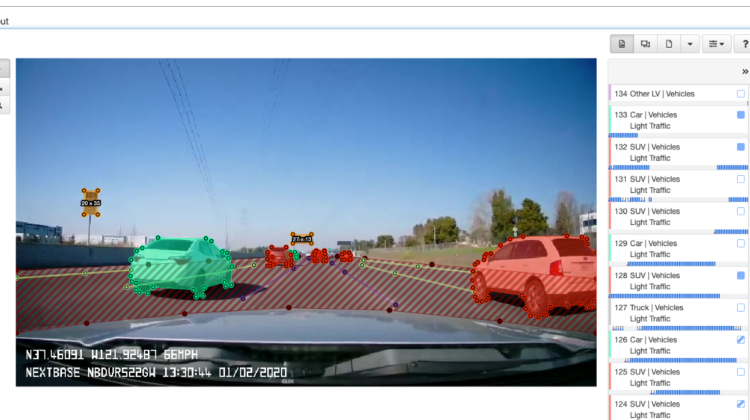
At Samasource, Vector Annotation of objects using polygons is a task that our expert annotators spend a great deal of time on. This is especially true for projects involving autonomous vehicles, where it is typical to apply instance segmentation to label scenes comprising hundreds of frames, each with multiple objects (vehicles, pedestrians, traffic signs, etc.) like you see in Figure 1.
In this post, we summarize an approach that we have developed to speed up polygonal instance segmentation using machine learning. This approach was presented earlier this year at the CVPR Workshop on Scalability in Autonomous Driving, and the ICML Workshop on Human-in-the-Loop Learning.
Building instance segmentation Deep Learning (DL) models for autonomous vehicles requires a significant amount of labeled data. The use of Machine Learning (ML) for producing pre-annotations to be reviewed by human annotators, whether in an interactive setting or as a pre-processing procedure, is a very popular approach for scaling up labeling while controlling the costs.
Multiple approaches have been suggested for machine-assisted instance segmentation. These typically consist of a DL-based segmentation of the object(s) integrated into a human-in-the-loop system. The human can interact with the system by correcting the model output, initializing the model with one or several clicks, or a combination of those steps. Examples of such systems include Polygon-RNN++ [1], DELSE [7], DEXTR [3], and CurveGCN [2]. Those systems all present good results, but some open questions remain:
- Do these methods perform well when a production-level accuracy is required, as when working for a customer project?
- Does the choice of annotation tool influence the results? The gains to be made by using ML depend on how difficult it is for humans to draw polygons in the provided UI. Here we used our optimized drawing tool for polygons, which is part of SamaHub, our labeling platform.
- ML integration is not usually approached from a human-centric perspective. Beyond the optimization of traditional metrics like IoU, what interactions are most desirable and how should we present the output of the model to annotators?
Our method relies on combining the well-known DEXTR [3] approach with a raster-to-polygon algorithm, to make the result more easily editable. This is not unlike what other tools (such as CVAT) have implemented, though we have optimized this approach for our specific use cases using A/B testing.
Our instance segmentation model is based on the well-known Deep Extreme Cut (DEXTR) approach [3], along with a raster-to-polygon conversion algorithm that yields high quality polygons whose vertices are sampled in a way that reproduces human drawing patterns. The model uses the few clicks provided by human annotators at inference time. The steps are described in Figure 2.
Regarding the model itself, we adopted a custom version of the UNet [5] along with an EfficientNet backbone [6] (instead of the ResNet backbone used in the paper).
In our experience, for human annotators to produce good instance segmentation masks efficiently, a polygon annotation tool should be used. As such, we needed to convert the raster masks produced by our model to high quality polygons. To add to the challenge, humans tend to produce sparse polygons, adding vertices only when necessary. We therefore adopted a raster-to-polygon procedure that minimizes the number of output vertices.
At Samasource, we use A/B testing as much as possible to systematically refine and improve our new features. To this end, we have developed a flexible testing infrastructure that can ingest and aggregate data from multiple internal processes and is made available to anyone within the organization.
This framework measures the statistical impact of proposed changes on our efficiency metrics (such as drawing time or shape adjustment time). The significance of observed differences on a given efficiency metric is evaluated using statistical tests.
Toy A/B Tests
We conducted an A/B test of the method using a synthetic automotive dataset called SYNTHIA-AL [8]. The dataset’s images and corresponding annotations were generated from video streams at 25 frames per second (FPS). Figure 3 shows SYNTHIA image examples, along with their segmentation (done manually and with the Few-Click tool).
The test, applied only to motor vehicles, reproduced realistic annotation guidelines, namely:
- The drawn polygon needs to be within 2 pixels of the edge of the vehicle.
- All vehicles down to 10 pixels (height or width) need to be annotated.
Following this test, we found a nearly 3-fold reduction in annotation time. On the other hand, we also found that on some of the more complex shapes, annotators were spending quite some time manually adjusting the ML output. DEXTR’s authors originally showed that the segmentation can be improved with additional clicks beyond the four initial ones. We therefore extended our few-click tool to allow online refinement of the polygons by considering modifications to their vertices as extra clicks. At train time we simulated the corrective clicks by considering the point of greatest deviation between predicted mask and ground truth as illustrated in Figure 4.
- Problem: DEXTR’s 4 extreme clicks are not always sufficient.
- Observation: DEXTR trained on 4 clicks benefits from additional clicks.
- Solution: Fine-tune DEXTR model with additional clicks for hard samples as established by IoU at train time.
Using this method, annotators are able to re-trigger the model inference with an additional click, instead of manually adjusting the output. We proceeded to a second toy A/B test, and results showed that we could obtain a theoretical efficiency gain of up to 3.5x on vehicles using the improved method.
Download our paper on Human-Centric Efficiency Improvements in Image Annotation for Autonomous Driving here and stay tuned to hear more about our latest advances!