Federated learning with different models
In vanilla federated learning [1], the centralized server will send a global model to each participant before training takes place. After every round of federated training, the participants send back its local gradient to the global model and the server updated it with the average of all the local gradients. Hence, the participants involved in the federated learning process only obtained a generalized global model with no respect for any personalization of their data. One of the challenges in federated learning is data and device heterogeneity, this can pose a problem when a user has rich data but is unable to customize the global model to take advantage of its own personalization (Since gradients are averaged, the averaging effects can get drown out by other gradients other than it’s own).
With statistical or data heterogeneity, different participants have different data. In order to have a personalized model such as different models created for different participants, statistical heterogeneity needs to be addressed first, which implicitly leads to model heterogeneity. To tackle statistical heterogeneity is to have an individual model for each participant, however, we also need to ensure that the individual model converges to a true global model which is not possible with simple averaging due to client drift.
In this paper [3], the author focus on a different type of heterogeneity, which is the differences in local models. The author explored and applied two techniques such as transfer learning and knowledge distillation [2] into federated learning. This allows the global model to be universal and also allows every participant to have a customized model with personalization.
One trivial example without personalization is, assuming we are training a federated learning model for a food recommendation with two participants A and B as shown in Fig 1. Participant A only has data for fruits, participant B only has data for beverages. Clearly both participants have data drawn from different distributions. Hence, using simple averaging of the gradients doesn’t make any of the models unique, as participant A only wants fruit personalization, and participant B only wants drinks personalization and not a mixture of both.
The author proposes a framework called “FedMD” which allows transfer learning and knowledge distillation to be incorporated into federated learning Fig 2. below.
Transfer learning
The reason for using transfer learning is the scarcity of private data since private datasets can be small and if we can leverage transfer learning on a large public dataset it would be extremely beneficial to the model.
Knowledge distillation
With knowledge distillation [2], the learned knowledge is communicated based on class scores or probability scores. These newly computed class scores will be used as the new target for the dataset, and with these approaches, we can train any agnostic model to leverage the knowledge learned from one model into another model.
FedMD
The FedMD framework requires each participant to 1. Train a unique model on a public dataset to convergence (A large dataset that is publicly accessible), 2. Train its own small private dataset using the unique model, 3. During each round of federated learning, participants to compute class scores on the public dataset and sends the result to a central server, 4. The central server computes and updates the consensus which is the average of the class scores, 5. The updated consensus or class scores will now be the baseline (new public dataset) where the participants will now use for further federated training and fine-tuning.
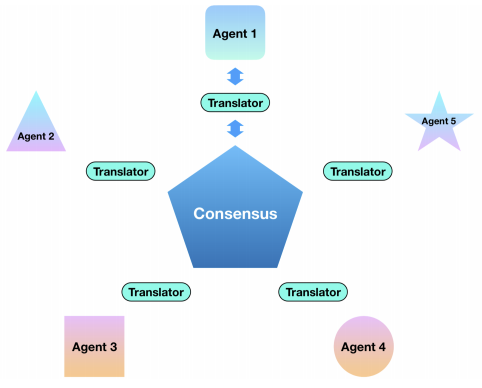
The following Fig 3. is a general framework for heterogeneous federated learning used by FedMD framework, where each agent/participant owns a private dataset and a uniquely designed model. Each participant has the class scores computed via knowledge distillation, which is known as the translator. The translator communicates to the central server known as the consensus and the consensus performs an update of the consensus with the average of the class scores computed from each participant.
The full algorithm of the FedMD framework from paper [3] is shown below.
Experiment on 10 participants
Experiments are carried out on 10 participants, each with unique convolution networks that differ by the number of channels and layers. These 10 participants are first trained on the public dataset and achieve a test accuracy around 99% on MNIST and 76% on CIFAR10 achieve state-of-the-art accuracy, and secondly trains its model on its own small private dataset. It was shown in Fig 4. below that the curve slowly approaching the optimal test accuracy of FedMD framework when FedMD framework is used.
FedMD is a framework that allows participants to have a unique, independently, and privately designed model in federated learning. This framework relaxes the statistical and model heterogeneity challenges in federated learning. The model architecture of the participants need not be the same as opposed to vanilla federated learning e.g. Federated averaging (FedAvg), and this is achieved by using transfer learning and knowledge distillation. FedMD is one framework that allows participants to craft their own model to meet its distinct specification in federated learning, which further addresses some of the concerns such as scarcity of private data and model privacy.
[1] https://towardsdatascience.com/introduction-to-federated-learning-and-challenges-ea7e02f260ca
[3] Daliang Li, Junpu Wang. “FedMD: Heterogenous Federated Learning via Model Distillation.”