The speech parameter generation algorithm is used to generate the spectral and the excitation parameters from the Hidden Markov Model (HMM) that are often excessively smooth compared with those of the natural speech. Poor modelling accuracy may cause over-smoothed parameters, and lead to quality degradation of the synthesized speech. The over-smoothing is classified into two types: time-domain and frequency-domain. The over-smoothing in the frequency-domain is the main factor which influences the quality of the synthesized speech and it is generally caused by the irregularities obtained in the training algorithm accuracy, whereas the over-smoothing in the time-domain which is caused due to the limited model structure can nearly be ignored. Hence, the resultant quality of the synthetic speech is degraded. One of the key reasons behind the over-smoothing is that the distribution of the generated parameters and the parameters corresponding to natural speech is significantly different. Hence, we can improve the quality of synthetic speech by transforming the generated speech parameters in such a way that their distribution is close to that of natural speech. This can be achieved by employing the recently proposed Generative Adversarial Networks (GAN) in the TTS-based system. In particular, we plan to implement the GAN-based TTS for three Indian languages, namely, Hindi, Marathi and Gujarati. Furthermore, this proposed work will also identify the current limitations of the GAN-based TTS and will attempt to alleviate it.
The framework of GAN-based Text-To-Speech
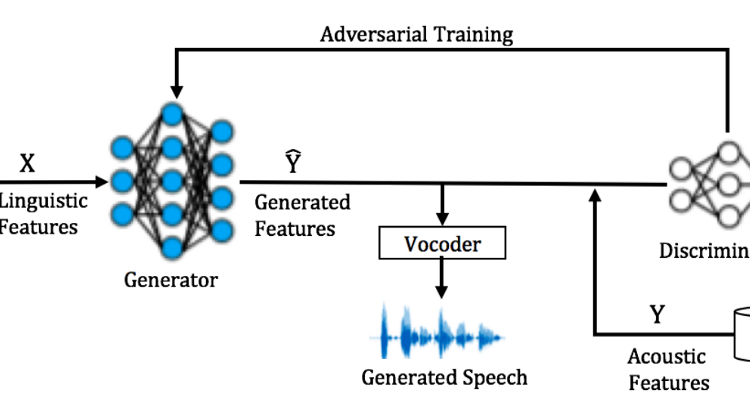
The overall architecture of GAN-based TTS system is shown in Figure 2. We will develop speech corpus for three low resource Indian languages. Phonetically balanced optimal text corpus will be selected. The key steps of the TTS framework are discussed below.
Frontend Text Processing:
The task of the frontend text processing block is to extract the linguistic features from a given input text. It consists of the following steps.
•Text normalization:-This step defines a set of rules for expansion of commonly used abbreviations, acronyms, numbers based on the context, etc.
•Letter-To-Sound (LTS) rules:-LTS rules indicate how the written text has to be spoken. These rules will tackle issues related to the Indian languages, such as schwa deletion, anuswara, etc [3],[4].
- Labeling:- Appropriate sound units, such as syllables, phones, diphones, triphones will be selected for respective Indian language. Based on the units, the labelled speech corpus will be created. We will explore automatic segmentation algorithms for this task [5].
Let us consider X = [XT 1, XT 2,…, XT T ] be a linguistic feature sequence obtained after the frontend text processing.
Acoustic Analysis: From speech corpus, the system (vocal tract), as well as excitation source-related features, will be extracted. In particular, spectral features, pitch (fundamental frequency (f0)), energy, aperiodicity related parameters will be extracted using WORLD vocoder. Let Y = [Y T 1, Y T 2,…, Y T T ] be an acoustic feature sequence. We will use GAN to learn the mapping between X and Y.
Mapping using GAN: GAN is a deep generative model, that simultaneously trains two networks, namely, a generator G that estimates the mapping function between the representative pairs and a discriminator D that acts as a binary classifier. The D network accepts the real samples coming from the natural speech distribution Y and the fake samples generated by G. The output of the discriminator, 1/(1 + exp(D(Y))), represents the posterior probability that input Y is a natural data. The D network is adversarially trained to maximize the likelihood of the samples coming from Y as real and minimizes the likelihood of the samples coming from the model distribution Yˆ (output of generator) as fake. In the other words, the D network is trained to make the posterior probability 1 (i.e., natural speech) for the natural data and 0 (i.e., spoof speech) for the generated data, while the generator is trained to deceive the D network. Both the D and G networks are trained using Stochastic Gradient Descent (SGD) algorithm. First, by using natural data Y and generated data Yˆ, we calculate the discriminator loss (Y, Yˆ ). The objective function can be formulated as:
where EX∼X denotes the expectation over all the samples from the distribution. Figure 2 illustrates the procedure for computing
The networks loss. After updating the discriminator, we calculate the adversarial loss of the generator which deceives the discriminator. A set of model parameters of the generator G is updated by using the stochastic gradient. The adversarial framework minimizes the approximated divergence between the two distributions of natural speech and the generated speech data.
Research Issues Related to the Low Resource languages:- There are only a few databases which contain the phonetically-rich sentences. The intelligible and the natural-sounding TTS systems exist for a number of languages of the world. However, for low-resource, high-population languages, such as languages of the Indian subcontinent, there are very few high-quality TTS systems available. One of the bottlenecks in creating TTS systems in new languages is the development of a frontend that can take sentences or words in the language and assign a pronunciation in terms of the phonemes from a phone set defined for the language In some languages, such a frontend may make use of a lexicon, which is a list of words in the language with their pronunciations, and of an LTS model that predicts the pronunciation of Out-of-Vocabulary (OOV) words. Other frontends may not have a lexicon and may only use LTS or Grapheme-to-Phoneme (g2p) rules to predict the pronunciations of all words. Languages that have fairly close relationships between the orthography and pronunciation typically fall in the latter category.
Research Issues in GAN-based TTS
Following are the research issues associated with the current GAN-based techniques which we will focus in this proposed work
- Despite the existence of the mathematical convergence for an objective function of the GAN given by Eq. (1) and Eq (2), training of GAN is difficult.
- The GAN training requires the appropriate model and its hyperparameters selection for better performance.
- Mode-collapse and the vanishing gradient problems in the degrades the generated sample quality of the GAN.
- The training of the GAN with less amount of speech data (which will be the case in low resource languages).
- The computational complexity involved with GAN, due to simultaneous utilization of two networks