Machine learning is a complex field that borrows elements from different areas such as computer science, algebra and statistics. Hence, it is not immediate, even for experts in the field, to build strong machine learning models to solve predefined task. Furthermore, those models should also be optimized with a time-consuming and repetitive hyper-parameters search in order to find the best set of hyper-parameters that better fit the data. A significative portion of time is also dedicated to the data pre-processing phase. In fact, every dataset is a new challenge itself: some column values may be missing, others could be outliers. Some columns may contain numerical feature while other contains pure text or, even worse, mixed types could be included.
Although some existing libraries such as Numpy, Pandas and Sklearn could make data scientists life much easier, setting up a full ML pipeline is still far from being a quick and straightforward task. The wish to have the work done quickly from modern developers and the need to make ML more accessible gave birth in recent year to the so called auto-ML. The idea is to have a single process that takes care of the full ML pipeline starting from data pre-processing to model optimization without requiring the user to have any ML knowledge.
In this blog we are going to explain how Genify.ai tested Amazon Personalize (AP), an auto-ML tool specialized in making recommendations, to develop a banking products recommendation system or engine. Amazon Personalize is a fully managed machine learning service that goes beyond rigid static rule based recommendation systems and trains, tunes, and deploys custom ML models to deliver highly customized recommendations to customers across industries such as retail and media and entertainment. It provisions the necessary infrastructure and manages the entire ML pipeline, including processing the data, identifying features, using the best algorithms, and training, optimizing, and hosting the models.
Before going on, let’s briefly understand the content of the data provided by the bank. The dataset contains one and a half years of customers behaviour data from Santander. The goal of the bank is to predict what new products customers will purchase. The data starts at 2015–01–28 and has monthly records of products a customer has, such as credit card, savings account, etc. In addition, the dataset also records monthly user personal data such as average income, age, sex and so on. Finally, the recommendation engine will predict what additional products a customer will get in the last month, 2016–06–28, in addition to what they already have at 2016–05–28 (products acquisition). Thus, the train set contains 17 months from 2015–01–28 to 2016–05–28 and the test set contains only the timestamp corresponding to 2016–06–28. Models are thus trained on sequences of 16 months to predict items acquired on their respective last month. In our experiments we randomly sampled a sub-set of 20000 users in order to speed-up the computation. In the next section we can see the items owned by a sample user along with its metadata.
In this section we are going to summarize the steps we performed in order to set up our ML pipeline with Amazon Personalize.
- First of all, we created an account on AWS in order to use the 3 following services: S3, IAM, and Amazon Personalize. S3 is a cloud service used to store the data involved in the process while IAM is used to give the permissions to Amazon Personalize to read/write data from/to S3. Finally, we tested Amazon Personalize to train a model and make predictions.
- Next, we created and uploaded our dataset on S3. Note that all files containing the data should follow a specific format defined here. Extracting, formatting and filling missing values from those two datasets has been the only “manual” work we performed on the dataset. Moreover, due to a limitation imposed by AP, each user can have at most 5 features. Consequently, we used a feature selection algorithm to estimate features’ importance and select the 5 most useful ones (source).
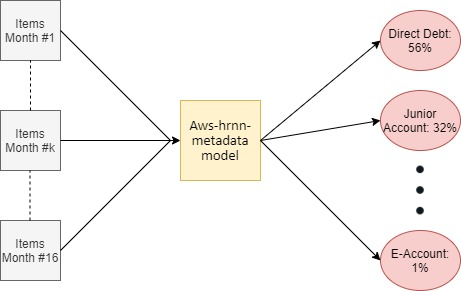
- The next step consisted of training a solution version (model). In our experiment we selected the aws-hrnn-metadata model since it makes use of both user’s personal features and products history dataset to make predictions (source).
To get performance metrics, Amazon Personalize splits the input interactions data by randomly selecting 90% of users and their related interactions as training data and the other 10% as testing data. The solution version is then created using the training data. Afterwards, the solution version is given the oldest 90% of each user’s testing data as input, and the recommendations it generates are compared against the real interactions given by the most recent 10% of testing data (source). However, this method has two problems which make those metrics unusable for our goals. First, we want to compute the metrics on the test set provided by the bank and not on a test set defined by AP. Secondly, we want the test set to contain only the last interaction and not the most recent 10% ones. As a reference we show the metrics computed by Amazon Personalize so to show later that also our script yields similar results.
Note: readers not familiar with the meaning of the metrics can find a detailed introduction here in the official documentation.
While Amazon Personalize performed recommendations only based on items ownership, we evaluated the recommendations provided by Amazon Personalize both on predicting items ownerships and acquisiton. Let’s recall that the difference between predicting items ownership and acquisition is that the latter doesn’t include items owned in the last month before to the month to predict. Hence, items acquired on the last date 2016–06–28 are computed excluding the items owned on 2016–05–28 from the original predictions.
Note: The defaults metrics provided by Amazon Personalize in table 3 are based on products ownership.
Consequently, to evaluate the model, we created a json file containing the index of the users contained in the test set and used it to create a batch inference job on Amazon Personalize so to get the corresponding predictions. Finally, we computed the metrics using our own script. The results we got are the following.
Consideration 1: The original Metrics@k=25 has no sense since we only have 21 items, thus it has been replaced with k=20. For Mean Reciprocal Rank and Normalized Discount Cumulative Gain, k=5, k=10 and k=20 all yields similar results, thus it has only been reported k=20. Moreover, they have been added Precision@1 and Precision@3.
Consideration 2: Why MRR is so high? By analysing the recommendations, we can note that the system predicts the item #0 (Current Accounts) with high confidence (>0.99) for many users. This is probably due the fact that the dataset contains a considerably high number of user-item interactions containing the item #0 (237883 in our sample, which is roughly the sum of the occurrences of the other items as we can see in image 2).
It’s true that a powerful tool such as Amazon Personalize makes automatic most of the work required to set up a full working recommendation system. However, Amazon Personalize has still some limits which may with different degrees make this service less desirable for expert scientists and that could restrict the full performance of the model itself:
- Amazon Personalize is relatively slow: most of the operations involving Amazon Personalize takes time to complete. For example, creating a new dataset from the dashboard can take a few minutes while train a model can take hours depending on the size of the dataset but it takes long time even for small datasets. Finally, creating a campaign and a batch inference process also take several minutes.
- Input data should follow a specific format: although using Amazon Personalize doesn’t require any machine learning knowledge, however, a team of data scientists is still required to handle the data pre-processing which could be a very time and resource consuming process.
- Amazon Personalize accepts a maximum of 5 features per user: consequently, should be used any feature selection algorithm to estimate features’ importance and select the 5 most useful ones.
- Comparison is not straight-forward: The fact that Amazon Personalize selects a random test set makes it difficult the comparison with other models with the metrics provided by the system. Thus, we had first to make predictions on the test set, process the result and manually compute the metrics.
We tested Amazon Personalize auto-ML tool to build and evaluate a discrete recommendation system on financial data. However, we are going to show in the next blog that we succeeded to design and train our own model on the same data outperforming Amazon Personalize, thus providing even more powerful recommendations.