In the past few years, Transformer models gained a lot of popularity in solving Natural Language Processing(NLP) tasks. Transformers are large pre-trained neural networks trained on massive data to grasp the patterns in language. These models can be fine-tuned to solve many NLP tasks like Semantic analysis, question answering, machine translation etc.
OpenAI’s GPT-3 certainly created a lot of hype and became one of the most famous deep learning transformer models in the last few years. It is well known for it’s size of 175 billion parameters and in some way it is nothing but GPT-2 with more parameters.
Google’s Switch Transformer is currently getting a lot of attention for it’s 1.6 trillion parameters model size and outranked T5 model in multiple NLP benchmarks.
Switch Transformer’s 1.6 trillion parameters is impressive but the most impressive aspect is it’s simple and efficient computation which is unlike of GPT-3(computationally expensive). Switch Transformer achieved the same perplexity as T5 -Base and T5-Large models 7x times faster with same computational resources.
Introduction:
In deep learning, typically models reuse the parameters for all inputs. Whereas Mixture of Experts(MoE) select different parameters for each incoming example. Despite the notable successes of MoE in machine translation, it’s adoption is hindered by complexity, communication costs and training instabilities. Here Experts are nothing but Feed Forward Networks(FFN).
In Switch Transformer, switch means routing the input to particular subset of parameters which implicitly follows Not all knowledge is useful all the time. Switch Transformer architecture simplifies and improves Mixture of Experts(MoE) to yield training stability and computational benefits. Switch Transformer has many instantiations based on parameter count have names like Switch-Base, Switch-Large, Switch-XXL, Switch-C(1.6 trillion parameters).
Note: Switch Transformer doesn’t only refer to Switch-C(1.6 trillion parameters initialized).
As seen in above figure, We replaced the dense Feed Forward Network(FFN) layer in Transformer with a sparse Switching FFN layer. This Switching FFN layer operates independently on the tokens in input sequence. The token embedding of x1 and x2 (produced by below layers) are routed to one of four FFN Experts, where the router independently routes each token.
How does the router know which expert to switch on?
Let the token z after the embedding, Self-Attention and Add+Normalize layers be x(token embedding). The router needs to determine the best expert to pass the token embedding(x). Steps on how to select the Expert:
- Let Wᵣ be the router variable(a learnable parameter)multiplied with the embedding x produces logits h(x) = Wᵣ * x
- h(x) is normalized via softmax distribution over the available N experts at that layer. The gate-value for the expert i is given by: pᵢ = softmax(h(x)ᵢ) This pᵢ represents the probability of passing the embedding through the expert i.
- The embedding x is passed through the expert i with highest probability. Finally, the output (i.e., the updated token embedding) is the activation produced by the expert, weighted by its probability score: y= pᵢ * Eᵢ (x)
Here the embedding is passed through only the expert having highest probability, whereas in normal MoE layer we pass it through k(k>1) experts. This k=1 routing strategy is referred as Switch Layer. Previous studies like MoE in context of LSTMs state that network selects multiple experts(at least two) and aggregates the results. Prior intuition of having minimum two experts for reliable training of routing parameters is defied by Switch Transformer as it selects only one expert.
Benefits of Switch layer:
- The router computation is reduced as we are only routing a token to a single expert.
- The batch size of each expert can be at least halved since each token is only being routed to a single expert.
- The routing implementation is simplified and communication costs are reduced(since only one expert needed for computation).
Switch Transformer is a sparsely-activated expert model, where sparsity comes from activating a subset of the neural network weights for each incoming example. Model sparsity introduces training instability(different training runs can lead to different performance because of initialization of parameters).
Reasons for Training Instability:
Instability can result because of the hard-switching(routing) decisions at each of these layers and low precisions formats like bfloat16(brain floating point). Low precision formats can exacerbate issues in the softmax computation for our router.
Solutions to Training Instability:
Stability achieved by selectively casting to float32 precision within a localized part(router) of the model, without incurring expensive communication cost of float32 tensors. Router input was cast to float32 precision and removes the exacerbate issues in softmax computation. Precision is only used within the body of the router function, so no expensive communication cost but we still benefit from the increased stability.
Reducing the initialization scale results in the better model quality and more stable training of Switch Transformer.
One of the more natural issue of deep learning models is Overfitting. Simple way to alleviate this issue is by increasing the dropout inside the experts known as expert dropout. So smaller dropout rate(0.1) at non-expert layers and larger dropout rate(0.4) at expert layers improves performance.
Observations on Scaling properties :
Switch Transformer architecture is scaled in many dimensions like experts, number of layers.
The number of experts is the most efficient dimension for scaling our model because increasing the experts keeps the computational cost fixed as the model selects only one expert token. Choosing the expert is a lightweight computation so increase in experts won’t effect model computationally.
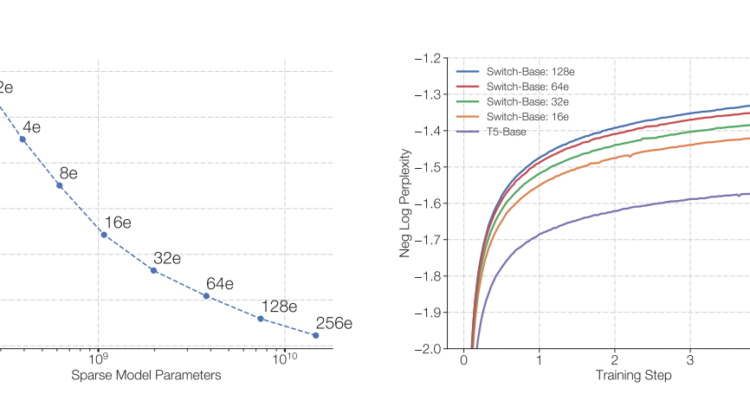
From the Left Plot of Figure 4: From top-left to right-bottom, we increase the number of experts from 1 to 2, 4, 8, 16, 32, 64, 128 and 256. We can observe the with the increase of experts there is an consistent improvements in performance with equal computational budget.
From the Right Plot of Figure 4: Switch Transformer is achieving the same perplexity as T5-model more earlier. With the increase in experts count the Switch Transformer is achieving the results more earlier.
Observation from above figure: With same amount of computation and training time, Switch Transformers significantly outperformed Dense transformers(T5-model) and 64 expert Switch-Base model achieves the same quality 7x times faster than T5-Base model.
Downstream Results:
In this section authors used highly-tuned 223M parameter T5-Base model, 739M parameter T5-Large model as baselines and compared them with 7.4B parameter Switch-Base, 26.3B parameter Switch-Large models. Authors used the 124B floating point operations(FLOPS) for base models and 425B floating point operations(FLOPS) for large models. Switch Transformer models performed better than the FLOP matched T5-Base and T5-Large models in most of the NLP tasks like question answering, classification ,summarization.
Conclusion:
In the present days of ever increasing large models, it is motivating to see these large models using limited computational power. This research also motivates sparse models as an effective architecture and alleviate the issues of sparse models like model complexity, training difficulties ,communication costs. Switch Transformer study makes us to consider these flexible models in natural language tasks.
References:
Fedus et al.: Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity (2021)
Raffel et al.: Exploring the limits of transfer learning with a unified Text-to-Text Transformer(2019)
Shazeer et al.: Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer (2017)