OpenAI’s API feature GPT3 is a wonderfully expressive technology. The API is a text in/text out API converts the input text by way of a extremely large language “transformer network” into the output text. The API is so expressive that it is easy to get lost in conversation/interaction with it and miss forensic details about its behavior. The more sophisticated your desired use the more the nuances of GPT3 become important to spot and understand.
Note about the intent of this essay series
This post is not an architecture nor technical essay — it is about understanding and using the behavior of the API and GPT3. (If you want a quick developer tutorial Twilio has a good one)
Interested readers should go read up on transformers and GPT2 and GPT3 architectures. Transformer networks are sufficiently complex that knowing their architecture in detail doesn’t offer much guidance on the emergent behavior of the network. This is a common experience in physics, chemistry and biology. Different levels of a system have unique properties and often has correlative but not fully deterministic causal relationships. Thus the experiments and exercises here explore the linguistic, algebraic and statistical behavior of GPT3 and the API.
Additionally we will cover what GPT3 is made of — human language as put onto the web AND the encoding algebra (the math/relationships) of this language.
All that said… this is an attempt to use simple examples, simple language and very little, if any, “hard math”. There will be pattern observation and simple arithmetic.
If this exercise does a job the reader will come away much more equipped to fluently deploy GPT3 in a variety of use cases.
- Structure
mathematical/data structure: lists, number, string, delimiters
language structure: parts of speech/types, grammar, punctuation
programming and markup structure: code, mark up, text - Meaning/Semantics
human language meaning
mathematical/algebraic/computational meaning
corpus - Interpretation/Language Tasks
searching
classification
summarization (compression)
questioning and answering
prediction/completion
translation/encoding-decoding - Emergence and Synthesis
how all these things come together - Systems
the compounding of multiple modalities into adaptive experiences and tools
Notation Conventions
Input and output of GPT3 or other computations: When you see BOLD text or numbers or strings that refers to any human supplied data and the computer generated output will continue but will not be in bold.
Any aspect that has been run through an algorithm/computation will be highlighted in grey.
Structure refers to patterns and how sets of things might be organized, arranged, demarcated. We start here because this is by far the most important aspect to think about with GPT3 (and all Natural Language Processing). One must always understand, analyze, parse, factor in, consider the basic structure of the text (and what it “represents”).
Lists (using Numbers)
Lists are the most basic structures. Sometimes lists are considered sets. Don’t think too hard about it. A list is literally some stuff, some other stuff, and other stuff somehow made clear by a delimiter/separator. But let’s start simply. Here is the start (by me) of a list and then extension of that list (by GPT3).
As an aside consider this “playground” UI provided by OpenAI. Here we should become familiar with a few things. There’s a text entry area and then the parameters on the right. These parameters allow us to tell OpenAI API what tunings to use to process our text in/text out. For most of this post we’re dealing only with Response Length and Temperature and Presence Penalty. Response Length just tells the API how much text/data to send back. The Temperature is a “randomness” setting that introduces non-determinism into transformation. At setting 0 there is no randomization (we will talk more about this later). Presence Penalty is another source of variability (slightly different that temperature, and we will return to this.)
So back to this list. This is a list of numbers, the natural numbers, the positive integers. It is a list of numbers delimited by commas.
Let us simply swap out the commas for periods.
Now we have something confusing. The list of numbers divided by commas turns out very differently than a list of numbers divided by periods or decimals. And that’s the issue. The structure of numbers and letters is greatly influenced by delimiters and punctuation. A list, in written language, is usually signified by the use of commas. Periods/decimals may or may not indicate list membership.
Here we simply swap the periods for a ||. A || pipe produces the list of numbers again. Why? because || has no alternative structural use in common language. So the GPT3 model treats it similarly to a comma.
Key Point: if a symbol, token, string is almost always used as a delimiter in common use OR if a symbol, token, string is almost never used as a delimiter then GPT3 will readily treat it as a delimiter in the output. For delimiters, avoid using symbols, tokens, and strings that have many different uses.
Lists are a very rich concept. So let’s quickly show more examples. Assume for the next examples we are sticking with the settings;
- “Curie” for the model (this is a smaller, but faster model than the big model “Davinci”, models will be reviewed later).
- Temperature = 0
- Presence Penalty = 0
Lists + Delimiters
Lists are any delimited set of things or just a set of elements. When we write out lists we delimit elements in some way. Remember that in written, typed, programmed language set elements and delimiters are all actually elements of a bigger list.
1,2,3,4,5,6 is a list of the first 6 counting numbers (integers). But that list is also a super list of 1comma2comma3comma4comma5comma6. So in that regard
A list needs very view elements to “guess it” or rather common lists are common and so they are what a GPT3 will pick by default.
1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,
but… we can’t do a 2 element prompt for the odd integers. Odd integer lists are not as common as just the integers.
1,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,
so… add one more odd number element to the list and GPT3 finds the odds.
1,3,5,7,9,11,13,15,17,19,21,23,25,27,29,31,33,35,37,39,41,43,45,47,49,51,53,55,57,59,61,63,65,67,69,
some people write the prime numbers starting with the same 3 elements as the integers (mistakenly so as “1” isn’t technically a prime or is it?): 1,2,3,… so at temperature 0 and pp 0 GPT3 will never guess the primes from just 3 elements.
how about 4 elements?
1,2,3,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,
nope. So now we have another issue with structure and lists. Lists aren’t just the “template” of a list. The actual structure or “meaning” of the list elements is important. (not surprising). Let’s stick to simple numbers though to keep exploring lists to see where they are easier to encode in GPT3 and where they might expose ambiguity.
5 elements?
1,2,3,5,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,
Still no. So the prime numbers are far less common in regular language use than a list of the integers. You can think of “size of input” to establish a structure as the probability of finding that general structure in common language use. How elements will we need for GPT3 at temperature 0 to get the primes?
1,2,3,5,7,11,13,17,19,23,29,31,37,41,43,47,53,59,61,67,71,73,79,83,89,97,101,103,107,109,111,115,119,121,123,125,127,131,
Turns out *6*. Not bad. But that gives you a sense, roughly, that the primes are 1/2 as present or “obvious” as the positive integers to the learning model of GPT3 . Don’t get too hung up on technicalities here. This is about linguistic ideas. So here, what we’re learning is that a list of the first set of primes is common enough to be prompt-able with only 6 elements. This makes sense also considering the other list of integers that differ from the primes by an element or two: 1,2,3,4,5,6 or 1,3,5,7 or 2,4,8, or 1,2,3,4,5,6 and so on.
Key Point: GPT3 and transformer models are fundamentally about sampling probabilities — how present is a structure or pattern in a corpus of language. And based on that probability … a prompt can be found more or less reliably / easily / frequently.
Let’s make the point clearer about lists, delimiters and how they are encoded as lists of numbers (vectors). We can convert the list 1,2,3, to its Byte Pair Encoding (the raw “vocabulary” of the model.) of 16,11,17,11,18,11. Commas encode as 11s and 1 is 16, 2 is 17, 3 is 18…. or n → n+15.
This gives us a direct sense of how everything really is a list of integers mapping to other lists. No matter what text you throw at GPT3 it’s converted to a list of integers, mapped to other integers and then converted back to output text. This shouldn’t be surprising but that’s how computers work in general for everything, for the most part.
This will be useful later on as we look at more advanced structures. Sometimes it helps to step out of the text and look at the lists of numbers — to be able to use the tools of statistics and mathematics to help us see what’s going on.
Mathematical Imprecision Note: this essay does not do a rigorous treatment of components and ideas like the BPE. In fact, this essay stretches their meaning a little. Worth reading up BPE. also note that GPT3 uses the GPT2 BPE, but with some modification.
(e.g. from page 16 of the GPT3 paper: This could be a weakness due to reusing the byte-level BPE tokenizer of GPT-2 which was developed for an almost entirely English training data set. and page 24 Finally, it is worth adding that solving these tasks requires character-level manipulations, whereas our BPE encoding operates on significant fractions of a word (on average ∼ 0.7 words per token), so from the LM’s perspective succeeding at these tasks involves not just manipulating BPE tokens but understanding and pulling apart their substructure.)
Keeping Track of Details — a Necessary Sidebar
No doubt this gets very confusing to keep straight at what “level” things are happening on. We have to be pedantic because the mathematical/computational reality of what machine learning language models is not what the reality of language is — at least not directly.
For example, our written language signs are symbolic as written/read but also represent other things like sounds (phonetics), timing and more. The computer encoding has no sense of those things in these transformer networks. It might get close or resemble sense of phonetics but really phonetics can only work with a user of language that hears/sounds those phonetics.
We will return to issues of language interpretation later. This sidebar is a warning that the annoying details are important and will continue to be pointed out.
Lists within Lists
Language considered simply is a list of letters joined into a list of words into a list of phrases into a list of sentences into a list of paragraphs … delimited by punctuation marks and spaces. Additionally words and phrases carry references from list to list forming “meta-lists” such as how pronouns and determiners function. Of course mathematics with numbers and algebraic variables share these features of grammar as well.
All seems well. But this is where the details about what transformer networks are as probabilistic maps(given X input what is the most common Y to expect) starts to matter a lot.
Let’s just try to make a list of lists of numbers.
Now instead of continuing a numeric list or starting a new numeric list GPT3 instead dips into what seems like programming language comments and programming code. Per all the above this should make sense why this happened. The most common usage of parenthetical lists of numbers would be in programming code uploaded to the web. So this list of lists of numbers is networked to programming code, and specifically function arguments.
more examples to demonstrate the various possible behaviors influenced by use of delimiters and lists of lists (remember we are still on “curie” and temp=0):
(1,2,3,4,5),(1,2,3,4,5),(1,2,3,4,5),(1,2,3,4,5),(1,2,3,4,5),(1,2,3,4,5),(1,2,3,4,5),(1,2,3,4, (1,2,3,4,5),(1,2,3,4,5,6),(1,2,3,4,5,6,7),(1,2,3,4,5,6,7,8),(1,2,3,4,5,6,7,8,9),(1,2,3,4,5,6,7,8,9,10),(1,2,3,4,5,6,7,8,9,10,11),((2,4,6,8,10),(1,3,5,7,9),(2,4,6,8,10),(1,3,5,7,9),(2,4,6,8,10),(1,3,5,7,9),(2,4,6,8,10),(1,3,5,7,9),(2,4,6,8,10),(1,3,5,7,9),(2,4,6,8(2,4,6,8,10),(1,3,5,7,9,11),(2,4,6,8,10,12),(1,3,5,7,9,11,13),(2,4,6,8,10,12,14),(1,3,5,7,9,11,13,15),(2,4,6,8,10,12,14,16),(1,3,5,7,9,11,13,15,17),
So here we can see some basic pattern with in pattern recognition. GPT3 picks up on lists that are of the same length and those that have an additional element. GPT3 also is able to pick up the pattern of advancing the numeric values by a successor and by successor of even/odd. But is GPT3 doing mathematical reasoning or are these just sequences that are found in many places on the web?
Let’s try some sets that are probably not very common:
(10012,10025,10038,10051,10064,10077,10090),(110012,110029,110046,110063,110080,110097,110114,110131,110148, 110165,110182,110199),(110212,110229,110246,110263,110280,110297,110314,110331,110348, 110365,110381,110398),(110412,110429,110446,110463,110480,110497,110514,110531,110548, 110565,110582,110599),(110612,110629,110646,110663,110680,110697,110714
Here GPT3 has picked up another possible way of producing corresponding patterns. GPT3 picked up the +17 pattern of the second list of the original lists provided AND it picked up that from list 1 to list 2 in the input that the lists start with 12 in tens place. Then for list 2 of the generation it took the hundreds up +100, but retained the starting with a 12 in the 10s place. Each list in the GPT3 generation moved up the hundreds place from end of previous list. This is somewhat complicated so let’s break it down.
(10012,10025,10038,10051,10064,10077,10090) => n+13(110012,110029,110046,110063,110080,110097,110114,110131,110148, 110165,110182,110199) => n+17(110212,110229,110246,110263,110280,110297,110314,110331,110348, 110365,110381,110398) => start list +13 and XXXX12 from end of previous list and then n+17 for each number in list(110412,110429,110446,110463,110480,110497,110514,110531,110548, 110565,110582,110599) => start list with XXXX12 and move hundreds place up 1 and n+17(110612,110629,110646,110663,110680,110697,110714 => start list with XXXX12 and move hundreds place up 1 and n+17
There’s another concept we can introduce here, probabilities and log probabilities. These are the little statistical bits that indicates how the model decoded the possible patterns in the prompt and produced a completion with those patterns.
Roughly we can read the highlights of the given prompt (the bold string) as an indication of how “rare” the tokens in the string are (rare means “information rich”). And the highlights of the completed text indicate how well it was able to follow the pattern.
In the completion the model reported a 37.7% probability for “11” and 22.69% for “110” and “113” at 1.23% … and so there was a combined ~60% for a number starting with “11”, where as “12”,”10″,”13″ were pretty far behind. If you follow these probabilities all the way through you’ll see how they statistically model the “logical” nested patterns described previously.
As humans we can pick this part and ask “are these the implied lists?” Well, of course they are as you can see how each of the lists and list members was generated. These may not be the list one wants in listing those two lists, but the GPT3 algorithm made reasonable statistical guesses as to explainable lists. In fact, it’s pretty remarkable it found 3 or 4 levels of structure within these lists provided in the input.
To bring home the point we can look at the inputs and outputs as encoded by the BPE again. This helps show how the patterns reveal in ways that are not necessarily “arithmetic” and “series completion” in the linear way above, but instead as emergent in resolving probabilities during the model training. (that’s a complex way of saying, hey, these patterns emerge in a way that makes sense but is a different sense than how we’d do it with series completion.).
[7, 3064, 1065, 11, 3064, 1495, 11, 3064, 2548, 11, 3064, 4349, 11, 3064, 2414, 11, 3064, 3324, 11, 3064, 3829, 828, 7, 42060, 1065, 11, 42060, 1959, 11, 42060, 3510, 11, 42060, 5066, 11, 42060, 1795, 11, 42060, 5607, 11, 1157, 486, 1415, 11, 1157, 486, 3132, 11, 1157, 486, 2780, 11, 1367, 486, 2996, 11, 1157, 486, 6469, 11, 1157, 486, 2079, 828]
=>
[7, 11442, 21777, 11, 11442, 23539, 11, 11442, 26912, 11, 11442, 29558, 11, 11442, 21033, 11, 11442, 26561, 11, 11442, 33638, 11, 11442, 31697, 11, 11442, 28978, 11, 9796, 24760, 11, 11442, 36626, 11, 11442, 31952, 828, 7, 11442, 39226, 11, 11442, 11785, 11, 11442, 27260, 11, 11442, 38380, 11, 11442, 22148, 11, 11442, 38073, 11, 11442, 47396, 11, 11442, 20, 3132, 11, 11442, 49934, 11, 9796, 47372, 11, 11442, 46044, 11, 11442, 43452, 828, 7, 11442, 43610, 11, 11442, 48602, 11, 11442, 27720, 11, 11442, 45791, 11, 11442, 37397, 11, 11442, 40035, 11, 11442, 45722]
What is worth noting here is how some singular text characters are treated as a singular token when next to some other characters but then treated as part of a string in others. e.g. commas next to numbers are generally encoded as 11. But when a comma appears next to a close ) in “),” the token is 828. You can also notice how “numbers” that to a human seem like a singular number with magnitude places are given token numbers in a different ways. e.g. the number 110199 in text form is encoded as 1157,486,2079 in the BPE. This means that 1101 is 1157,486, so 11 is 1157 and 10 is 486 and 99 is 2079. This does not mean that all numbers of that length get encoded as 3 tokens in BPE. e.g. 110212 encodes as 11442, 21777.
Key Point: This should make us wonder what’s going on here? why are some numbers broken up as two tokens and others three? Following the themes here it should become clear with some thoughts. The higher the token number in the BPE the less probable/frequent the token. So small integers tend to be far more frequent than larger ones. And integers like 11 are far less frequent than 10… keep in mind encodings are relative. so 11 is going to encode differently if it’s just by itself versus next to other characters that might change its meaning/frequency. Check out the entire GPT2 (and I think GPT3) BPE here.
In this plot you can see how integers up to 100 are encoded. As expected 1–9 are sub 100 in the BPE, and as you move up the distribution widens. Notice that at multiple of 10s the BPEs are lower, multiples of 10 are frequent in written language.
If we take 1/BPE token then we can get some rough idea of a frequency for that number/string in the model.
Just for fun we can explore different kinds of numbers, say the even numbers vs. prime numbers for their estimated frequency (token id). Nothing too exciting or unexpected. For those interested in human language numbers generally distribute according to fun patterns like Benford’s Law.
While we have used numbers and lists of numbers to make these points above about lists and frequency of occurrence obviously the same idea applies to language on the whole. The entirety of natural language processing and machine learning relies on the fact that stuff in the world has structure AND it has referential / instance frequency. That is, there is structure in the world and some of those structures appear more than others.
Small numbers and the digit 1 are more frequent than big numbers and the number 8 and 89009890. Literally the digit 1 is part of most big numbers. The word “the” is very frequent in language and most book titles, titles in general, many sentences contain it and so on. Smaller words tend to be more frequent. Punctuation is extremely frequent because punctuation delimits lists (it’s always needed!).
But! Frequency doesn’t imply meaning or information. We will get to this in a bit. Often highly frequent things are hard to determine meaning from! “the” doesn’t really indicate that much!
Keep this, that, and the in the, a, your mind!
Lists and Structure (using “Natural” Language)
Hopefully it’s becoming clearer how structure exists and emerges from within GPT3, the BPE and from the raw “input” of the world. We now have to do a little bit of forensics on basics of human natural language, just as we did with basic lists of numbers.
What we need to remember.
Have to call this out! We cannot proceed with our GPT3 efforts without always remembering lists, delimiters, frequency of use, sentence structure, punctuation and articles as delimiters….
{1,2,3} is a number sentence. Numbers one, two and three are a set is a word sentence. They are all the same structural components, in particular in how they might be found in the GPT3 encoding.
The above examples are remarkable. Without even adjusting our settings from base level parameters we can get completely different responses to content that differs in minor ways. The responses themselves SEEM wildly different, but that’s only in read meaning. What’s happening in the BPE->GPT3 embeddings (the network itself) is not that different. Remind yourself how richly the network found structures in our two number lists previously and then reconsider the above examples.
- one,two,three,
- one, two and three?
- Numbers one, two and three?
- Numbers one, two and three are a set?
- Numbers one, two and three are a set is a word sentence
Why are Question Marks so potent? How do they take things away from just “extending the list in the current content form”… or is that what they are doing?
The ? mark is less frequent in language (written AND programming) than other sentence endings and other language delimiters. The BPE has ? as 30, ! as 0, . as 13, and yes, remember, , as 11. oh and a “ “ (space by itself) is 220. So in a trivial sense a ? mark already sets up the model to go to less frequently occurring paths.
Key Refrain: Do not over extend this point about BPE token number and frequency. It’s just useful to keep thinking about these topics. Technically you can overreach especially as we build up more complex inputs.
Structure as Grammar
Let’s just quickly rip through parts of speech and sentences now that we are more familiar with the core concepts.
The cat sat on the mat. The cat sat on the mat. The cat sat on the mat. The cat sat on the mat. The cat sat on the mat.
That example doesn’t go anywhere because that example is the sentence in every high school sentence diagramming exercise and every NLP programming demonstration. Plus the words are so frequent there’s no where for this to go, especially at temp 0.
The cat sat on the mat? The cat sat on the mat? The cat sat on the mat? The cat sat on the mat?
Not even a question mark can shake it loose.
Is there anything structurally interesting to be done with these words in this order as this sentence?
The Cat sat on the mat. "I'm not going to hurt you," said the Cat. "I'm just going to look at you." "I'm not afraid of you," said the Mouse. "I'm not going to hurt you," said the Cat. "I'm just going to look at you." "I'm not afraid of you," said the Mouse. "I'm not going to hurt you," said the Cat. "I'm
and a variation.
Cat sat on the mat. "I'm not sure I can do this." "You can do this," I said. "You can do anything you put your mind to." "I don't know if I can do this," Cat said. "I don't know if I can do this." "You can
Whoa. All we did was capitalize “Cat”! But what does that indicate in language? Proper noun, names, characters. and what types of language forms start sentences and paragraphs with Proper Nouns?
The Cat sat on a mat. The Cat sat on a mat. The Cat sat on a mat. The Cat sat on a mat. The Cat sat on a mat.
the to a mat.
The Cat sat on the mat, and the Mouse sat on the mat, and the Cat said to the Mouse, "What are you doing?" The Mouse said, "I'm eating the cheese."
a comma.
The cat spat on the mat. "I'm not going to let you go," he said. "I'm going to keep you here forever."
sat to spat. we have added some infrequency.
The cat sat on the windowsill, watching the world go by.The cat was a stray, and the owner was not home.A cat is a cat is a cat.A cat, a dog, a bird, a fish, a rabbit, a pig, a cow, a goat, a sheep,
More examples where the basic structures of language itself do “work” to route patterns in the model. We are staying on this to avoid thinking parameters are magic knobs of meaning.
Man not Cat
The man sat on the mat. He was a young man, with a thin face and a long nose. He was dressed in a white shirt and a pair of baggy trousers. He had a small, round, black hat on his head. He was holding a small, black, leather-bound book in his hands. "I am the man who will be your teacher," he said. "I am the man who will teach you the ways of the world. I am the man who will teach you the ways of the world."The Man sat on the mat. He was a small man, with a round face and a bald head. He wore a white shirt and a black vest. He had a long, thin beard. He was very old. “I am the Man,” he said. “I am the Man. I am the Man.Man sat on the mat. He was a big man, with a big belly and a big head. He was bald, with a big head of hair. He was a big man, with a big belly and a big head. He was bald, with a big head of hair. He was a big man, with a big belly and a big head. He was bald, with a big head of hair. He was a big man, with a big belly and a big head.
The “story” structure/content is triggered for “Man” because there are almost no references in books or WWW where “the man sat on the mat.” is used as an linguistic instruction or programming example. “the cat sat on the mat” is commonly used for demonstrations and not just stories and so it’s possible structure inclusions is greater than “the man sat on the mat.” Presence of structure and meaning in the corpus used to train GPT3 will be an important topic to return to. For now we will stay focused on the core structure of human language.
Combine these two structurally similar sentences into one prompt where instead of a period punctuation/delimiter we use a comma. What happens?
The cat sat on the mat, The man sat on the mat, The cat sat on the mat, The man sat on the mat, The cat sat on the mat, The man sat on the mat, The cat sat on the mat, The man sat on the mat, The cat sat on the mat, The man sat on the mat, The cat sat on the mat, The man sat on the mat, The cat sat on the mat, The man sat on the mat, The cat sat on the mat, The man sat on the mat, The cat sat on the mat, The man sat on the matThe Cat sat on the mat, The Man sat on the mat, The Cat sat on the mat, The Man sat on the mat, The Cat sat on the mat, The Man sat on the mat, The Cat sat on the mat, The Man sat on the mat, The Cat sat on the mat, The Man sat on the mat, The Cat sat on the mat, The Man sat on the mat, The Cat sat on the mat, The Man sat on the mat, The Cat sat on the mat, The Man sat on the mat, The Cat sat on the mat, The Man sat on the matCat sat on the mat, Man sat on the mat, and the cat said, "I'm going to eat you." Man said, "No, you're not." The cat said, "Yes, I am." Man said, "No, you're not." The cat said, "Yes, I am." Man said, "No, you're not." The cat said, "Yes, I am." Man said, "No, you're not." The cat said, "Yes, I am."
So, why did removing the determiners change the outcome from a repetitive list into a dialog between characters? Proper nouns again. But there again we’re making to the effect of corpus and meaning — a future topic.
Let’s go back to periods instead of commas. Now the structure is much more clearly two sentences, two statements. Watch what happens.
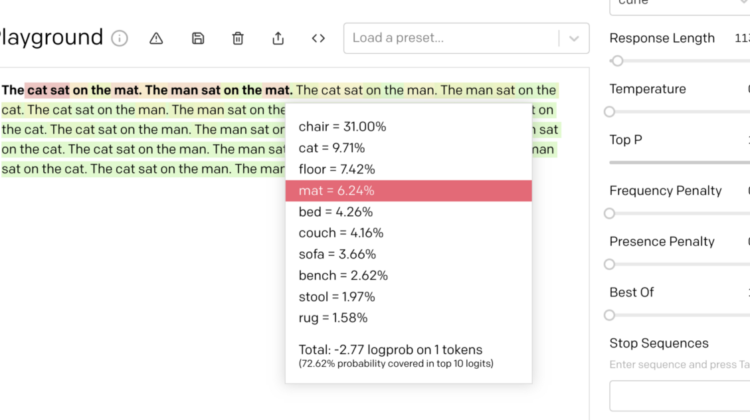
The cat sat on the mat. The man sat on the mat. The cat sat on the man. The man sat on the cat. The cat sat on the man. The man sat on the cat. The cat sat on the man. The man sat on the cat. The cat sat on the man. The man sat on the cat. The cat sat on the man. The man sat on the cat. The cat sat on the man. The man sat on the cat. The cat sat on the man. The man sat on the cat. The cat sat on the man. The man sat on the cat.
Now the sentences get a remix but the mat goes missing. What’s going on?
There are a variety of complexities going on here. The two sentences are now supplying “inference context”. GPT-style models prefer the content of the prompt over the trained model and so now the man and the cat overtake the mat in the decision tree. You can see in the probabilities what’s going on and if you look at the BPE you can see too. “mat” and “cat” are at similar places in the BPE and thus in this scenario they end up “splitting the probability” thus leaving “man” (which is far more common in the corpus, thus more relationships in the network) with a much higher probability of being swapped in for mat. Same thing going on for cat and mat, when the man is subject of the sentence.
This can be confusing to keep straight. Again, think probabilities and delimiters.
The cat sat on the sub-terrain. The man sat on the carrier. The cat sat on the sub-terrain. The man sat on the carrier. The cat sat on the sub-terrain. The man sat on the carrier. The cat sat on the sub-terrain. The man sat on the carrier. The cat sat on the sub-terrain. The man sat on the carrier. The cat sat on the sub-terrain. The man sat on the carrier. The cat sat on the sub-terrain. The man sat on the carrier. The cat sat on the sub-terrain. TheThe cat sat on the sub-terrain,The man sat on the carrier,The cat sat on the sub-terrain,The man sat on the carrier,The cat sat on the sub-terrain,The man sat on the carrier,The cat sat on the sub-terrain,The man sat on the carrier,The cat sat on the sub-terrain,The man sat on the carrier,The cat sat on the sub-terrain,The man sat on the carrier,The cat sat on the sub-terrain,The man sat on the carrier,The cat sat on the sub-terrain,TheThe Cat sat on the sub-terrain,The Man sat on the carrier,The Cat sat on the sub-terrain,The Man sat on the carrier,The Cat sat on the sub-terrain,The Man sat on the carrier,The Cat sat on the sub-terrain,The Man sat on the carrier,The Cat sat on the sub-terrain,The Man sat on the carrier,The Cat sat on the sub-terrain,The Man sat on the carrier,The Cat sat on the sub-terrain,The Man sat on the carrier,The Cat sat on the sub-terrain,The
Here we swapped in valid nouns for grammar but these are not commonly used words and particular not in these types of sentences. Now we just get repeated elements in a list.
The Cat sat on the sub-terrain. The Man sat on the carrier. The Cat was in the sub-terrain. The Man was in the carrier. The Cat was in the sub-terrain. The Man was in the carrier. The Cat was in the sub-terrain. The Man was in the carrier. The Cat was in the sub-terrain. The Man was in the carrier. The Cat was in the sub-terrain. The Man was in the carrier. The Cat was in the sub-terrain. The Man was in the carrier. The Cat was in the sub-terrain. The
Ok, now we re-introduce the Capitalization of Cat and Man and something new has happened. “sat on” => “was in”. Linguistically this all “valid” and it makes sense from everything learned so far that sub and carriers often have stuff in them not just on them. (Remind yourself how how number sequences played out too. Some number sequences have more possible and probable completions than others).
Cat sat on the sub-terrain. Man sat on the carrier. "I'm going to take a look at the sub-terrain," Cat said. "I'll go with you," Man said. "No, you stay here. I'll be back in a few minutes." "Okay." Cat walked over to the sub-terrain. He looked at the sub-terrain. He looked at the sub-terrain. He looked at the sub-terrain.
Just by removing “The” we have grammatically (and semantically) altered what the model has to play with. Reminder that we are still at temperature 0 and curie engine. So including “The” and capitalizing nouns introduces a pretty large amount of “expressiveness.” We have shown a pretty broad set of behavior simply by changing delimiters/punctuation, capitalization.
Expressiveness sounds exciting and useful. It is! In a way expressiveness is built into Numbers and into Natural Language — human language is metaphorical and full of interpretative structure+meaning. But this also has a “downside” if we want more deterministic/reliable input to output. Markup languages and computer programming are uses of human language and mathematical symbols where we want much more predictability in the structural input to output.
Structure using Programming Languages and Markup
If lists of numbers and simple sentences resist being tied down what hope is there for programming and mark up? what makes these uses of language different than numbers and natural language?
Programming and Markup are proto-languages or rather mini-languages defined just in time. They have a highly reduced vocabulary, very strict structural rules and are highly context constrained. The literally definition of programming and markup are to have a specific vocabulary for use in producing expected relationships between input and output. Markup is used to constrain the meaning and interaction of the language/signs it is marking up. Context constraint is enforced because programming and markup require defining to a large extend what one is doing at the time one is doing it. e.g. you define a variable and the variables possible uses right before you use it.
More specifically, programming is literally just lists, delimiters and directions for how to combine, sort, or otherwise relate those lists.
Warning, a little bit of magic forthcoming. If we participated thoughtfully in the earlier part of the essay the magic should be less magical, and more mechanical.
Here is a simple prompt of programming code (in a programming language called javascript) by which 3 words are assigned the value (meaning) of A Number (these assignments are usually referred to as variables). An operation is defined on what to do with those words (called a function). That function defines “write each number out one after the other”.
the BPE encoding of the above prompt:
[7785,530,796,352,26,198,7785,734,796,362,26,198,7785,1115,796,513,26,198,8818,1351,7,77,17024,19953,198,198,1640,357,14421,26545,1659,15057,28,15,26,14421,26545,1659,15057,27,77,17024,13,13664,26,14421,26545,1659,15057,4880,19953,198,220,220,220,220,220,220,220,8624,13,6404,7,77,17024,58,14421,26545,1659,15057,36563,198,220,220,220,1782,198,92,198,220,198,4868,26933,505,11,11545,11,15542,36563]
GPT3 was able to encode our program, execute the program (?), and tell us that it recognized we provided it code. Disbelief may make us go, “it didn’t do any logical computing on that code, it simply has a template of that code in its model and it spit it out.”
We can test our disbelief.
BPE encoding of this modified program:
[7785,530,796,352,26,198,7785,734,796,362,26,198,7785,1115,796,678,26,198,8818,1351,7,77,17024,19953,198,198,1640,357,14421,26545,1659,15057,28,15,26,14421,26545,1659,15057,27,77,17024,13,13664,26,14421,26545,1659,15057,4880,19953,198,220,220,220,220,220,220,220,8624,13,6404,7,77,17024,58,14421,26545,1659,15057,36563,198,220,220,220,1782,198,92,198,220,198,4868,26933,505,11,11545,11,15542,36563]
So… something akin to program interpretation and logical operations is happening.
Key Point: Careful readers can tell from everything else we did above indeed these transformer networks are just probabilistic mappings from input to output. Those with programming experience probably recognize that’s exactly what computer compiling and execution of programs is. That’s what computers do. They take an input of lists and delimiters ([this list is that, that list is this, a list is that, not this list not that list]) and probabilistically produce an output. Our computers are full of “transformer” networks that under the right inputs will always produce the same outputs and those inputs and outputs can be packaged together in all sorts of ways. Our computers aren’t endlessly deterministic logically perfect machines. Even addition in our computers is a probability situation and is resolved through various implementations of “transformers”.
But, of course, as we’ve seen, it’s not so easy. There’s a lot going on here. and we need to keep pressing what these multiple levels of transcoding are doing.
Here instead of “19” as the “var three” we put in “1”. The results are not what you’d expect out of this javascript program.
Ok, so now choose a token for that variable that’s more rare in the model AND in the context and what happens? here we go with 2.
here are the probabilities of that “23” in the output. In essence by assigning the variable “three” to “23”, a number that’s easier to spot as important in the inference, in the input we made it “easier” for the transformer to get the “output right”.
Let’s chase this down.
var one = 1; var two = 34567; var three = 23; function list(numbers){ for (currentPositionofNumber=0;currentPositionofNumber<numbers.length;currentPositionofNumber++){ console.log(numbers[currentPositionofNumber]); } } list([one,two,three]); function list(numbers){ for (currentPositionofNumber=0;currentPositionofNumber<numbers.length;currentPositionofNumber++){ console.log(numbers[currentPositionofNumber]);
nope.
var one = 2341; var two = 2; var three = 23; function list(numbers){ for (currentPositionofNumber=0;currentPositionofNumber<numbers.length;currentPositionofNumber++){ console.log(numbers[currentPositionofNumber]); } } list([one,two,three]); The above code will output: 2341 23 23
nope.
but you can see what has happened… we have made the inference part harder to get a “correct” code output — we gave the model a wider set of possible directions to.
What’s making this confusing to interpret and to figure out how we might force the model to produce reliable input-output relationships according to our proto-language programming and our ideas of logic is that the output includes “The above code will output…”. That is a “meta” statement about the input, it is not simply responding to the input at the level you expect code to be interpreted.
Key Point: GPT3 is a general language network. It is not a fully realized programming interpreter. Or, rather, it has that capability, but the interface to that style of input-output mapping is not like the interface of a javascript interpreter. A javascript interpreter will likewise not be addressable in the same ways as GPT3. We can, in fact, get GPT3 and javascript to perform any arbitrary computation. All we’re doing here is figuring out what it takes to get what we want. (this is a topic for a different kind of essay on universal computation and computational equivalence).
Key Point 2: Whether GPT3 or Javascript or the words we are writing and reading here are “right” or “wrong” or “sensical” or “logical” is a matter of human subjectivity. These communication modalities are exactly what they are in all the ways they are and behave. GPT3 is not mysterious, nor is human language. We can forensically go through it and see how things work and when they are confusing or non deterministic we can find the source of that. It doesn’t mean we can resolve everything in any of these modalities into deterministic input output. We can’t even do that with math. Again, interested readers on these topics should read about mathematical incompleteness or halting problems in computational theory or about the many strange details of number theory. The take away up to this point is that GPT3 “makes sense” in what it’s doing and is “causal” in how it goes from input to output. The utility of that map making is up to the end human trying to do things in the world.
We can keep exploring this new “programming language” of GPT3+javascript:
var one = 0; var two = 2; var three = 4; function list(numbers){ for(currentPositionofNumber=0;currentPositionofNumber<numbers.length;currentPositionofNumber++){
console.log(numbers[currentPositionofNumber]);
} } list([one,two,three]); The above code will output: [0,1,2]
The above code will output: [0,1,2,3]
The above code will output: [0,1,2,3,4]
This seems like a very strange language, hard to use perhaps. We shouldn’t give up too easily though. GPT3 doesn’t actually have a javascript interpreter inside of it. We need to give it more context and it may still be able to emulate. Remember we haven’t even started using the bigger GPT3 model, davinci, nor tuned parameters like temperature.
Notice if we change the variable names to match the numeric value we assign that GPT3 does return to “correctly interpreting the javascript function”.
This is plenty of ground to cover for Part 1 of GPT3 Linguistics 101. The goal was to ground ourselves in the abstract concepts of structure in the form of lists, delimiters and probabilistic maps between them. We introduced 3 of the most common “lexical categories” of math, natural language and programming/markup and their corresponding grammars.
None of the examples nor topics were exhaustive, but they prime us for what is coming. These concepts are ever present in every thing we will build on top. As we move on to Meaning/Semantics, Tasks/Interpretation, Emergence/Synthesis and then Systems we will need to dip back into these low level concepts.
Let us close by experimenting more with the above rapidly and seeing if we can recognizing the patterns emerging on how GPT3 linguistically behaves.
coherence between variable name and number produces list. (reduced the patterns within patterns GPT3 has to parse).
var zero = 0; var two = 2; var four = 4; var nine = 9; function list(numbers){ for (currentPositionofNumber=0;currentPositionofNumber<numbers.length;currentPositionofNumber++){ console.log(numbers[currentPositionofNumber]); } } list([zero,two,nine]); The above code will output: 0 2 9
Introducing a new variable that has a sum but maintains coherence between name and value produces expected output (according to javascript interpretation.)
var zero = 0; var two = 2; var four = 4; var nine = 9; var thirteen = nine + four; function list(numbers){ for (currentPositionofNumber=0;currentPositionofNumber<numbers.length;currentPositionofNumber++){ console.log(numbers[currentPositionofNumber]); } } list([zero,two,nine, thirteen]); The above code will output: 0 2 9 13
removing the coherence between variable name and variable value produces a grammatically/structural correct but logically and lexically incorrect, according to javascript.
var zero = 0; var two = 2; var four = 4; var nine = 9; var fortyfour = nine + four; function list(numbers){ for (currentPositionofNumber=0;currentPositionofNumber<numbers.length;currentPositionofNumber++){ console.log(numbers[currentPositionofNumber]); } } list([zero,two,nine, fortyfour]); The above code will output: 0 2 9 44
Give it some commentary to add more inference.
var zero = 0; var two = 2; var four = 4; var nine = 9; var fortyfour = nine + four;
// fortyfour is a sum of the var nine and var four, fortyfour is not 44. function list(numbers){ for (currentPositionofNumber=0;currentPositionofNumber<numbers.length;currentPositionofNumber++){ console.log(numbers[currentPositionofNumber]); } } list([zero,two,nine, fortyfour]); // zero is a sum of the var zero and var two, zero is not zero.
Provide a natural language description and re-order the javascript.
Below is a javascript program that defines a function for listing values from a supplied array of numbers.
###
function list(numbers){ for (currentPositionofNumber=0;currentPositionofNumber<numbers.length;currentPositionofNumber++){ console.log(numbers[currentPositionofNumber]); } }
var zero = 0; var two = 2; var four = 4; var nine = 9; var blahblah = 2345+567;
list([zero,two,nine, blahblah]); Output: 0 2 9 2345 567 The above program is a simple example of a function that takes an array of numbers and returns the sum of the numbers.
This may seem like a hopeless effort to hover between “that works!” and “that’s not right!” However, we’ve barely begun. The above examples already started to venture into semantics and higher order lexical details. We also have chosen to try to “program” without an actual compiler. No need for hope or despair. The forensics have just begun!
Part 2 is coming soon. (by 12/14/2020 mid afternoon pacific. This essay will be updated to link to it.)