Most of the time, underfitting happens when the models or algorithms are too simple to fit more complex trends. The solution to this is simply train your model for more time or try a more complex model or algorithm. So, what is overfitting?
What is overfitting?
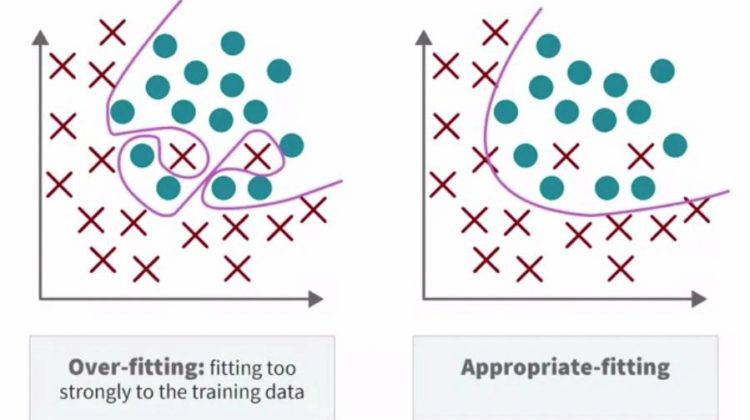
We briefly talked about overfitting when discussing methods for high-dimensional problems in linear regression. Overfitting is when the model fits the idiosyncrasies of the training data patterns so well that the model will only work well for the training data, and not on new data sets. Overfitting happens when the model fits to not only the signal that is useful about the features and but also begins to memorize the random fluctuations, anomalies, and noise that might be present in a training dataset.
Hyperparameters and algorithmic design choices can be tweaked to hit the sweet spot of appropriate fitting. Learning curves are one of the most common tools used to diagnose problems, such as model underfitting or overfitting, as well as the sanity check or debug the code and implementations. A common second type of learning curve to visualize during training is the plot of the final performance metric, for example, accuracy. This is useful to get a sense of actual model performance, since lower loss usually corresponds to better model performance, but it doesn’t tell us whether the accuracy is at a level we are happy with or not. Performance curves, such as accuracy curves, can also provide additional information to complement our analysis when we diagnose issues from learning curves.
What are some of the strategies to address overfitting?
Stop early
Machine learning models operate by first getting a rough set of weights which fit the training patterns in a general way and then progressively learning towards a set of weights in the model for features that fit well the training data. But if learning goes too far down this path, overfitting can happen. Therefore, if it is allowed to learn for too long, the model will become more prone to overfitting. To get a good fit, we must stop at a point just before where the error on the validation datasets starts increasing. At this point, the model is said to have good skills on the training dataset as well as on the unseen validation dataset.
Weight decay
The art of reducing overfitting is called regularization. Weight decay of one of the three commonly used regularization approaches. It is to add a value in the loss that represents the magnitude of the parameter values or the weight coefficients and penalize the model through the loss function fur using too many or too much of its parameters. If the model has many non-zero or large weights, the magnitude will be large. Since the model is looking to minimize the loss, this constraint forces the model to have small valued weights and thus forces to the less complex. The strength of this added value in the loss function is a common hyperparameter.
Dropout
A second regularization technique is dropout. Dropout means randomly setting parameter values to zero in the model during training. This means picking a layer of the model that randomly drops out output values and sets them to zero. The intuition is that that layer will become more unreliable, and that the model has to build in redundancy into its subsequent layers. By having to account for redundancy, the model cannot be as complex. The probability of dropping out a given neuron is a common hyperparameter.
Data augmentation
A third regularization technique is data augmentation. Data augmentation means randomly warping or transforming the samples in a training set to prevent the model from learning any features that are too specific. Some common augmentations for example for images include things like, rotating the image, randomly cropping it, resizing the image, adjusting color and brightness or flipping an image horizontally and vertically. Since the reason a model over fits training sets is because it gets too familiar with the samples. By constantly changing what the samples in the training set look like, you slow down or potentially prevent the model from memorizing that training set.