Often you must have heard this saying- “80% of the time goes into data cleaning and 20% in model building”. It is quite right because algorithms follow one thing, that is, garbage in garbage out. What does it mean?
It means that if you give a low quality of data to the machine learning algorithm, it will perform poorly. In a nutshell, the performance of your machine learning algorithms depends on the quality of the data you provide. So your path for Data Science should be data-oriented rather than algorithms oriented. So you must be wondering that What are the steps to prepare the data for machine learning algorithms. Don’t worry!
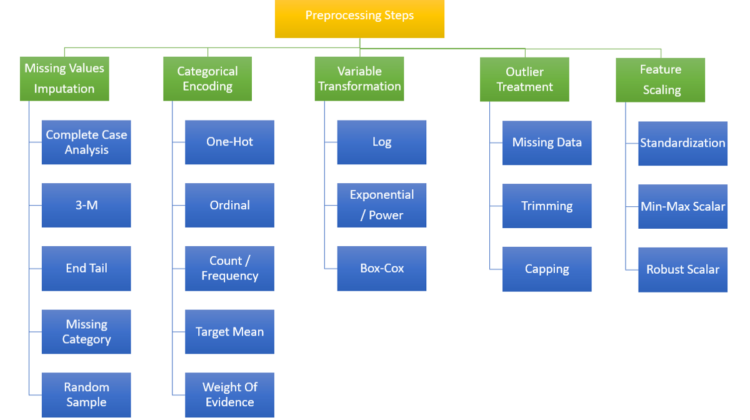
This post will help you understand different data processing techniques that you can implement in your data science project. So here are the things we are going to cover in this post.
As the name suggests, the values which are not present in the data or there is “Nan” in place of numerical or string values. The problem is that our machine learning algorithms are not smart enough to process this information with missing values. So even if you run the algorithm without treating the missing values, you might end up getting errors. So it’s crucial to treat them with suitable techniques. Here I have talked in depth about these techniques.
So what is Categorical Encoding?
In simple terms, it is a technique by which we try to replace the string data into a numerical format. There are various ways to do this, and we will be talking about them one by one.
So why Categorical Encoding is necessary?
It is necessary because the machine learning algorithms are not good at handing string data. It needs data in a numerical format so, our aim should always be to convert these data while retaining the information. So let’s talk about them.
1) One Hot Encoding
In this technique, we try to convert each categorical observation into a boolean value, 0 or 1. Here we introduce a new column for each unique value in that column. 1 in the newly created column indicates that it was this value in the original column. Below is the example of the one-hot encoding.
So the number of boolean columns is equal to the x-1, where x is the number of values a categorical column can take. Suppose we have a variable that can take three values, so we create two boolean columns. Below is the correct representation of the quoted example.
So why we left one variable?
We do this to make sure that there is no linear combination among the newly created columns because it may lead to multi-colinearity.
Advantages:
- This technique is quite robust for both tree-based models and linear models. In the case of the tree-based method, instead of x-1, we go with x number of columns.
- It keeps all the information intact since there is no data loss.
- It is easy to implement using pandas.
Dis-Advantages:
- The curse of dimensionality, namely, if the cardinality of a column is high. It ends up adding more dimensions to the data.
- This technique doesn’t consider the ordinal relationship. For example, if heights are as follows: Tall, Medium, and Short, so this technique considers them equal. Hence, we lose valuable information.
This technique is identical to the categorical encoding. The only difference is, in this technique, instead of creating a binary column, we assign a numerical value to the unique values of that column. Suppose we have a column of heigh taking three values, namely, short, medium, and tall. So we assign 0,1,2 respectively to each of the column values.
- It is easy to implement, and there is no data loss.
- It does not increase the dimensionality of the data.
- It modifies the data without losing the information. In the above example, we know that tall is greater than medium, and in turn, the medium is greater than the short. So we can assign values in such an order that this information is retained even after the transformation.
- While it retains the information after the transformation, but still doesn’t add any new information in the data.
- We have to be cautious while using this technique. Suppose we use this technique on the gender column. It might end up adding unnecessary information like the male is greater than female or vise-a-versa.
- It can’t handle a new column value. Suppose the gender column can take three values, albeit, male, female, and others. If we split the data, and we don’t get any row containing “others” as gender value in the train set. We end up encoding based on male and female only. Hence model will not be able to make any prediction if any data point containing “others” as a gender value.
In this technique, categories get replaced by the number of times they appear in the dataset. Due to its simplicity, this technique is prevalent in kaggle machine learning competitions. For this technique, we have to split the data. We cannot use complete data because it may lead to data leakage and overfitting. If we divide count encoding with the total number of instances, we get frequency encoding. Below is an example of this technique.
- This technique is easy to implement and quite robust with tree-based machine learning algorithms.
- This technique doesn’t add any dimension to the data, so we don’t have to worry about the increase in dimensionality.
- If the two different categories have the same numerical values, our machine learning algorithms might end up interpreting them identical. This way, we will lose some information. For example, If in the height column, The number of instances for tall and short is the same. This technique will assign the same number, losing the information that there is a difference between short and tall.
In this technique, we try to replace the category with the mean value of the target. This technique is suitable for both categorical or continuous target variables. Below is an example.
- This technique is straightforward and easy to implement.
- This technique doesn’t increase the dimensionality of the data. So on doesn’t have to worry about it.
- This technique creates a monotonic relationship between the target and the categorical values.
- It introduces the same problem as the count/frequency encoding, that is, losing the information when two categorical values are assigned the same values.
- Sometimes this technique may lead to over-fitting.
This technique has its application in loan default prediction. It tells the predictive power of a categorical variable concerning the target variable. Below is the formula.
Good-customer: If a customer paid his loan.
Bad-customer: If a customer didn’t pay his loan.
Here : If woe is positive, it means we have more examples of good than bad.
If woe is negative, it means we have more examples of bad than good.
- This technique doesn’t increase the dimensionality of the data.
- Since the categorical variables are on the same scale, it is easy to identify which one is more predictive.
- This technique introduces a monotonic relationship between the categorical values and target.
- When a categorical column has too many values, we can bin them and use the woe as a whole.
- Binning leads to loss of information. So we end up losing some valuable information.
- This technique may lead to overfitting sometimes since one can manipulate the binning.
This step involves transforming the continuous variable into a normal distribution. The reason is most machine learning algorithms follow the assumption of normality. All the linear models in machine learning assume that data is normally-distributed.
If we feed the non-normal data, the parameter of machine learning algorithms will be far-off from the actual values. It may end up giving inaccurate results. For example, in linear regression, we end up getting far-off values of slopes and intercept.
We avoid this thing by converting the distribution of our variables into a normal distribution. We only transform the data from the training set. We don’t do this on the test set because the purpose of the transformation is to streamline the training process. So let’s talk about the techniques.
It is a straightforward and robust technique used in machine learning. In this technique, we take the log of the column that we want to transform, and the base can be 2, 10, or natural log. Log transformation solves the problem of normality, and it can also deal with the skewness of the data. One can not use log transformation when there are negative values in a column because the log of a negative value is not defined. Below is the example of the different exponential functions applied to a column.
In this technique, we transform the variable of interest using powers like square root, cube root, squares, etc. One cannot say that the square root transformation is better than the cube root transformation. One has to find the best one by hit and trial method.
Again this transformation may not work in the case of negative values. Below is the example of the different exponential functions applied to a column.
This technique tries to make a variable linear. The lambda parameter is estimated by using maximum likelihood estimation, and its value ranges between 5 and -5. If the value of lambda is one, it uses log transformation. In a way, we can say that it is an extension of log transformation. This technique cannot deal with negative values, but there are extensions of box-cox which can deal with negative values. Here is the link if you are interested in the mathematics behind it. Below is the mathematical formula for this technique.
Below is the example of the different exponential functions applied to a column.
What are outliers?
An outlier is that observation that varies widely from the set of a data point. For example, in a school, if the height of students varies from 140 cm to 160 cm. Suddenly a new student with a height of 190 cm. This student is an outlier.
Machine learning algorithms are prone to outliers. They give inaccurate results or distorted results in the presence of outliers. Below is the example of linear regression.
Here we have two graphs, one without outliers and the other with outliers. We can see how the regression line changed by introducing just two outliers. Hence to make the training smooth for machine learning algorithms, we have to treat these outliers with the appropriate method.
In the case of skewed distributions, the approach is to calculate the quartile and the interquartile ranges (IQR). Below we have calculated the upper and lower limit for a variable. Anything above or below can be an outlier.
In the case of a variable following a normal distribution, we can use the fact that 99 % of the observations fall under three standard deviations. Any value that does not fall under this range can be an outlier.
Another method we have is a graphical method that is creating a box plot. So any value that is not outside the whiskers can be an outlier. Below is the example of a variable containing outliers.
So let’s talk about them.
In this technique, we consider the outliers as missing values. We try to implement the missing values techniques. Here I have already talked about all the missing values techniques.
In this technique, we delete all the values that fall under the outlier definition. The problem with this is we end-up losing some data, so it is better when there are a few outliers in the dataset. The below image depicts the effect of this technique.
In this technique, we cap or limit the values for the variable based on the type of distribution it follows. So if the variable follows a normal distribution, we can use the three-sigma value to cap the variable. If we have skewed distribution, we use the Inter Quartile Range (IQR) to find the lower and upper bound and use it to cap the variable values. We use the above formula for the capping.
What is Feature Scaling?
Feature scaling is the last step in the data preparation for the machine learning algorithms. In this step, we try to bring the value of all the variables on the same scale. Scaling of the feature depends on the type of techniques we use.
Why do we scale the features?
You must have heard of the phrase “comparing apple with oranges.” That is what our machine learning algorithms have to do. For example, suppose you have a height column and weight column, and we know that the height and the weight have different measures. To discover a precise relation between these two variables, we have to bring them down to the same level.
Another reason, some machine learning algorithms are susceptible to scale of the variable because high magnitude variable dominates the low magnitude variables. It results in machine learning algorithms paying more attention to the higher values. Below are the algorithms that are influenced by the scale of the variables.
So let’s talk about each technique.
In this technique, we use the z-scores to calculate the position of a particular value from the mean. Z-score is a statistical score that tells how far-off values are from the mean of the data, in terms of standard deviation. If the z-score for an observation is 2.5, that means the value is 2.5 times the standard deviation away from the mean. Few things to keep in mind:
- This technique changes the mean from whatever value to zero.
- This technique changes the variance from whatever value to 1.
- This technique preserves the shape and outliers in the data.
This technique is not suitable if the data is non-normal. Below is the formula for this technique:
Here is the Python implementation of this technique.
Note: Z-Score is itself a topic and out of the scope of this post. Here is a detailed explanation of this technique.
This technique uses the minimum and the maximum value to scale down the feature values. This technique gets influenced by the presence of outliers. After the transformation, the feature values range between 0 and 1. This technique is not good when data has outliers. Below is the formula for this technique.
This technique consists of two things. First, the centering of the data, that is, it changes the median from whatever value to zero. Second, it scales the data based on IQR and the median of the data. These two steps are independent of each other. Outliers do not influence this technique. Below is the formula used.
“That is all for this post, and if you have reached this far, I would like to thank you for investing your valuable time reading this. If you have any doubts or suggestions, please do let me know in the comment section.”