This blog is about how to solve instacart problem in Kaggle. Hopefully, this blog will give you a good understanding of solving the recommendation problem.
Instacart is an American company that operates a grocery delivery and pick-up service in the United States and Canada. Consumers in Instacart order large basket sizes of diverse foods over and over again from them. They have more density on user behavior than any e-commerce company. Work of a data Scientist in Instacart: https://tech.instacart.com/data-science-at-instacart-dabbd2d3f279
As having a huge user behavior data density, Instacart work in recommendation of products to the customer, as mentioned in the above URL. This problem focuses on improving the recommendation system to the user for more hand on experience for the user to suggest or recommend type of products to fill the basket, hence Instacart market basket analysis.
Based on previous orders the model have to predict what will user ultimately re-order, and with more precision, N number of most applicable recommendations for a user. For Deployment, Instacart as a company AB-Test every model for better user experience.
Data Source : https://www.kaggle.com/c/instacart-market-basket-analysis/data
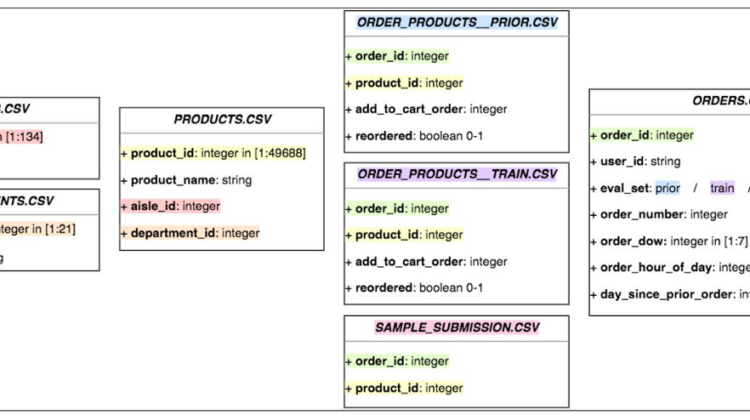
Data sets we have are 6 corelated csv files which can be easily merged using the primary keys.
The biggest problem any recommendation problem face is that the problem tend to be a cold start problem but in this case because of correlated files we can actually grab the behavior of every user and product and use that behavior for recommendation.
If we look at the diagram, we can see the orders.csv contains the history of transactions for the user and the eval set column in oreders.csv actually refer to the order_products_prior.csv file and order_products_train.csv file and the all the data in orders.csv file with eval set equal to test is the data we have to predict the products for.
This is the main reason why the problem is not a cold start problem because we can actually distinguish users and products with the correlation and behavior.
The existing solutions to the problem actually primarily focuses on feature engineering more and then actually build a simple model on it, which makes the problem more interesting as the there can be wide varieties of features one can think of while solving the problem.
Distribution of the data:
As we can see most data lies in the prior region, that is why we can extract the maximum behavior from it and use that behavior to train the model in the train region and then predict for the test region.
So we make a data with merging order_products_prior.csv file with orders.csv file and do the analysis on user and products.
Features to look at are :
- order_number
- order_dow
- order_hour_of_day
- days_since_prior_order
- add_to_cart_order
Univariate and multivariate analysis on how these affected the reordering for users and products:
As we can see most number of order-numbers were equal to 1 i.e. a positive skew can be seem in the behavior of the order-numbers
Seeing the the bar plot, it is clear that the day 0 and 1 are the days with maximum orders coming in which raises the question are 0 and 1 weekends or not?-yes 0 and 1 are weekends.
Maximum orders are ordered in between 10th and 16th hour of the day
As more no. of orders are ordered in the mid-day with Saturday afternoon and Sunday morning.
As we can see, reordering rate is maximum at 30 days and 7 days, means maximum users tend to reorder after 7 or 30 days.
As we can see most number of add_to_cart_order were equal to 1.
Maximum reorders are done on the Sunday morning, and all the reorders are happening basically in the early morning.
List of all the features:
<class 'pandas.core.frame.DataFrame'>
MultiIndex: 4833292 entries, (3, 248) to (206208, 49621)
Data columns (total 47 columns):
# Column Dtype
--- ------ -----
0 up_unique_dow int8
1 up_unique_hod int8
2 up_unique_atc int8
3 up_unique_reordered int8
4 up_cumcount_on int16
5 up_cumcount_dow int16
6 up_cumcount_hod int16
7 up_cumcount_dsp float16
8 up_cumcount_atc int16
9 up_orders_cumcount int8
10 up_orders_num int8
11 up_orders_since_previous int8
12 up_reordered int8
13 up_order_ratio float16
14 up_order_dow_score float16
15 up_order_hour_of_day_score float16
16 up_last_five float16
17 up_last_five_ratio float16
18 max_orders int8
19 total_items int16
20 orders_ratio float16
21 unique_products int16
22 num_reorders int16
23 reordered_mean float16
24 reordered_std float16
25 user_dow_mean float16
26 user_dow_var float16
27 user_dow_std float16
28 user_hod_mean float16
29 user_hod_var float16
30 user_hod_std float16
31 user_dsp_mean float16
32 user_dsp_var float16
33 user_dsp_std float16
34 prod_sum_on int32
35 prod_sum_dow int32
36 prod_sum_hod int32
37 prod_sum_dsp float32
38 prod_sum_atc int32
39 prod_sum_reordered int32
40 prod_num int32
41 prod_unique_users int32
42 prod_reorder_mean float16
43 prod_order_hour_of_day_mean float16
44 prod_order_hour_of_day_var float16
45 prod_order_dow_mean float16
46 prod_order_dow_var float16
dtypes: float16(23), float32(1), int16(7), int32(7), int8(9)
memory usage: 507.1 MB
The core problem this problem has is to make strong features and give more predictability power to the model. My features covered the behavior of users alone ,products alone and how user behave with products.
The main function which helped to construct these features was the “groupyby” function in the pandas library, lets see how:
For users:
Taking one example for users will be getting max number of orders any user have done.
#max_orders:Max orders ordered by users
max_orders = prior_orders.groupby(by='user_id'['order_number'].max().to_frame('max_orders')
max_orders = max_orders.reset_index()
max_orders
Similarly like this create other features for users and we can actually experiment and come up with many different types of features as in place of .max() we can use .apply() and create our own function and come up with new features.
For products:
Taking one example for products will be getting prod_reorder_mean for any products.
#prod_reorder_mean : product reorder mean
prod_reorder_mean =
prior_orders.groupby(by="product_id)["reordered"].mean().to_frame("prod_reorder_mean").reset_index()
prod_reorder_mean
Similarly like this create other features for products and we can actually experiment and come up with many different types of features as in place of .mean() we can use .apply() and create our own function and come up with new features.
For user-product features:
Taking one example for user-products will be getting up_orders_num for users and products.
#up_orders_num : Number of times user ordered the products
up_orders_num = prior_orders.groupby(["user_id","product_id"])["order_id"].count().to_frame("up_orders_num").reset_index()
up_orders_num
Similarly like this create other features for user-products and we can actually experiment and come up with many different types of features as in place of .count() we can use .apply() and create our own function and come up with new features.
Like this we basically make three pickle files named “users.pickle” , “products.pickle” and “user_products.pickle” and merge all these into one data set which we can call a absolute data set, from which we have to create data_train and data_test,on which we have to do the modelling and come up with a prediction.
Making of absolute data:
user = pickle.load(open("users.pickle" , 'rb'))
products = pickle.load(open("products.pickle" , "rb"))
user_products = pickle.load(open("user_product.pickle" , "rb"))data = pd.merge(user_products , user , on="user_id" , how="left")
data = pd.merge(data , products , on="product_id" , how="left")
#We want only the data with eval_set = "train" and "test"
orders_filtered = orders_data[(orders_data.eval_set == "train") | (orders_data.eval_set == "test")]
orders_filtered = orders_filtered[['user_id', 'eval_set', 'order_id']]#Making the absolute data
data = pd.merge(data , orders_filtered , on="user_id" , how="left")
data.fillna(0,inplace = True)
Making of data_train:
#Training Dataset
data_train = data[data.eval_set == "train"]#Getting the information for the Trainig data from train data
data_train = data_train.merge(or_prod_train[['product_id', 'order_id', 'reordered']], on=['product_id', 'order_id'], how='left')#filling the NAN values in the reordered
data_train.reordered.fillna(0, inplace=True)#setting user_id and product_id as index.
data_train = data_train.set_index(['user_id', 'product_id'])#deleting eval_set, order_id as they are not needed for training.
data_train.drop(['eval_set', 'order_id'], axis=1, inplace=True)
Making the data_test:
#Creating Test Dataset
data_test = data[data.eval_set == "test"]#setting user_id and product_id as index.
data_test = data_test.set_index(['user_id', 'product_id'])#deleting eval_set, order_id as they are not needed for training.
data_test.drop(['eval_set', 'order_id'], axis=1, inplace=True)
Final shape of data_train and data_test : (8474661, 48) ,(4833292, 47)
If we look at the business constraints of the problem that are Latency-constraints , Accuracy-constraints.
The metrics I used for selecting the best model were :
- Confusion-Matrix
- AUC-ROC
- AUC-PR
- F1-Score
Look through on metrics:
Confusion-Matrix : More theoretically we should not include this in metrics but this actually gives a great intuition on the model performance, specifically if the problem is a Classification problem.
AUC-ROC : For this problem particular, this was a good metric to be sure if the model is performing good for the data set or not and weather the model should be even bothered to be taken for consideration.
AUC-PR: This metric is one of the main metric for model evaluation, as in the real competition, the metric was average-f1-score,but I found to compute average f1 score is actually computationally expensive but plotting AUC-PR graph and calculating area of the graph gives a similar intuition for the model.
F1-Score: This one was the main metric for the evaluation of the results, but personally this was just the F1-Score and not average F1 score so for me AUC-PR was a better intuition for the models.
How to do modelling on such big data?
One problem with training dataset I faced was managing the data size for training. Training such big data on models like XG-Boost and Random Forest tend to take very long time for converging so I’ll suggest to go with those models which have more parameters to tune and have the possibility converge faster.
For me those models came out to be :
- Light Gradient Boosting Classifier.
- Catboost Classifier.
Taking Log-Probabilities and then maximizing the F1-Score:
Code snippet for maximization F1-Score:
thresholds = clf.predict_proba(X_test)[:, 1]
f1_scores = []
values = np.arange(np.mean(thresholds)-(2*np.std(thresholds)) , np.mean(thresholds) +(2*np.std(thresholds)) , 0.02)#Getting F1-Scores
for value in tqdm(values):
y_pred = (clf.predict_proba(X_test)[:, 1] >= value).astype('int')
f1_scores.append(metrics.f1_score(y_test , y_pred))#Plotting
plt.figure(figsize=(10,10))
sns.barplot(values , f1_scores , color = "red")
plt.xlabel("thresholds")
plt.ylabel("F1-score")
plt.title("Thresholds vs F1-score")
plt.grid(True)
plt.xticks(rotation = 90)plt.show()
For Light Gradient Boosting Classifier.
For Catboost Classifier.
Other models I tried were XG-Boost , Random-Forest Classifier , MLP Classifier , Conv-1D Layering NN , Dense-Layer NN.
The model I chose was Catboost Classifier as it gave me the highest Kaggle score out of others.
So, the Final Kaggle Score is 0.37868
The public score is 0.37868
The private score is 0.37802
This score puts me into the Top 500 rank which is Top 20% of the leaderboard.
There is one more trick to actually increase the accuracy score, that is by making two models one for prediction which products will be reordered and second for which user will reorder and then merging the two data sets formed using thresholds and probabilities. I would really like to try this approach as the people who tried this actually got a score of 0.4 and above.
Computing more features related to the user and a product like a user cart size, user’s average day of the order, and others.
Also, I am looking to try the Apriori Algorithm to get some more features.
- https://www.kaggle.com/errolpereira/xgboost-with-minimal-feature-engineering#Creating-user-product-features.
- https://www.kaggle.com/philippsp/exploratory-analysis-instacart
- https://www.kaggle.com/nickycan/lb-0-3805009-python-edition
- https://medium.com/analytics-vidhya/instacart-market-basket-analysis-kaggle-competition-856ddd7b08e0
- https://www.kaggle.com/c/instacart-market-basket-analysis/discussion/99252
- https://www.appliedaicourse.com/
GitHub Link for all pynb’s for this problem : https://github.com/Rag-hav385/Intacart-Market-Basket-Analysis
My LinkedIn : https://www.linkedin.com/in/raghav-agarwal-127539170